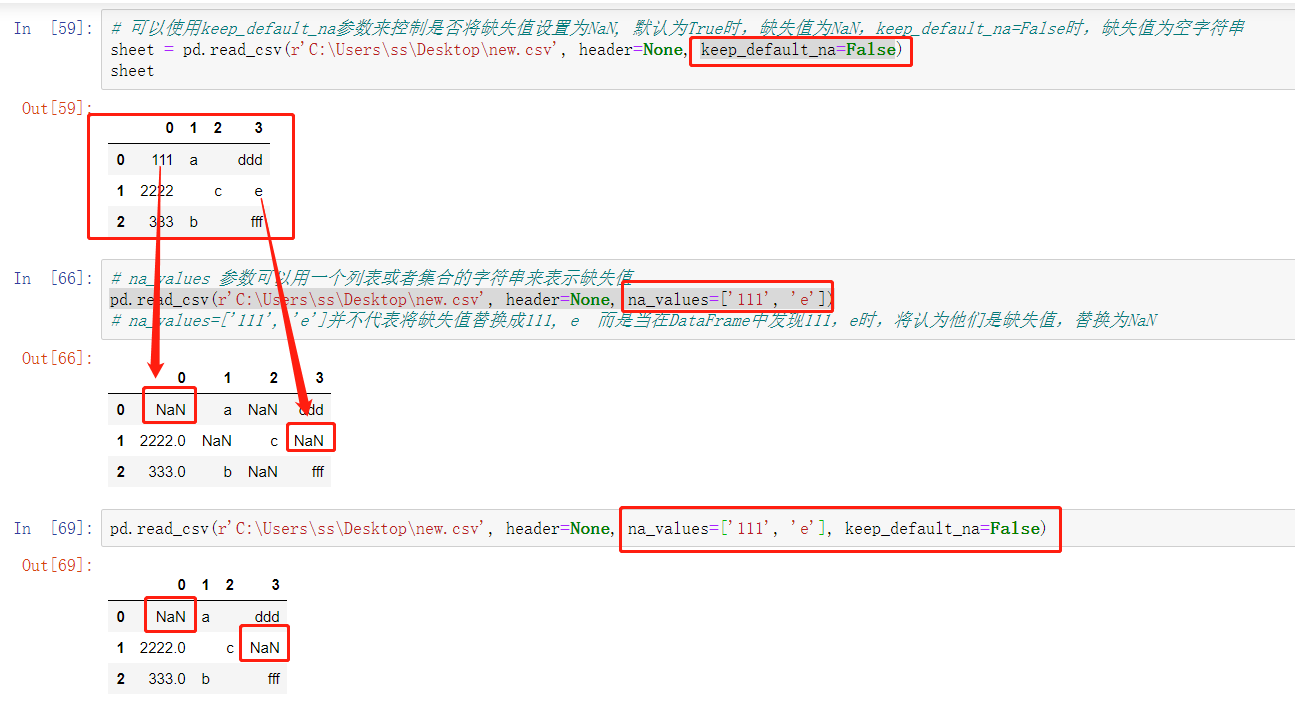
pandas中na_values与keep_default_na
我们在使用pandas读取文件时,常会遇到某个字段为NaN。
一般情况下,这时因为文件中包含空值导致的,因为pandas默认会将
'-1.#IND', '1.#QNAN', '1.#IND', '-1.#QNAN', '#N/A N/A','#N/A', 'N/A', 'NA', '#NA', 'NULL', 'NaN', '-NaN', 'nan', '-nan', ''
判定为缺失值,从而转换为NaN。那么如何避免DATa Frame中出现NaN呢,使用keep_default_na参数可以解决。
keep_default_na参数用来控制是否要将被判定的缺失值转换为NaN这一过程,默认为True。,当keep_default_na=False时,源文件中出现的什么值,DataFrame中就是什么值。
下来再说na_values参数, 这个参数用来控制那些值会被判定为缺失值,它接收一个列表或者集合,当列表或者几个中出现的字符串在文件中出现时,它也会被判定为缺失值.
但是,无论此时keep_default_na=True还是False,他都将被改写。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号