
22 Scrapy框架简介
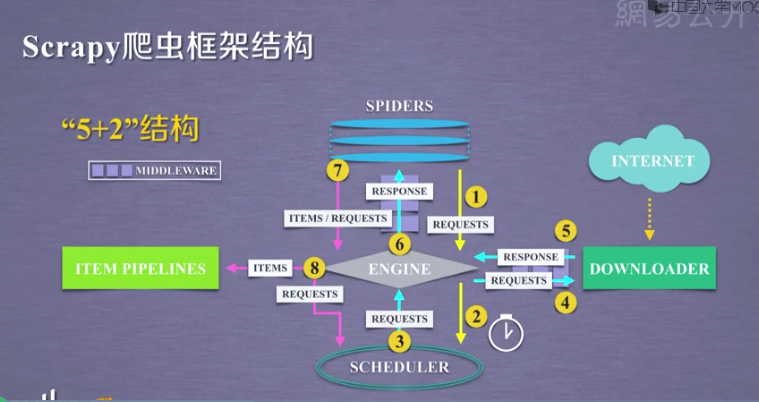
一、5+2结构:
- Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方
- Downloader Middlewares(下载中间件):是一个可以自定义下载功能的组件
- Spider Middlewares(Spider中间件):是一个可以自定操作引擎和Spider中间通信的功能组件
二、Scrapy请求发出去的流程
1.首先爬虫将需要发送请求的url(requests)经引擎交给调度器(上图1)
2.经Engine交给Scheduler(上图2),Scheduler排序处理后再由Engine,DownloaderMiddlewares(有User_Agent, Proxy代理)交给Downloader(上图3--4)
3.Downloader向互联网发送请求,并接收下载响应.将响应经ScrapyEngine,可选交给Spiders(上图5--6)
4.Spiders处理response,提取数据并将数据经Engine交给ItemPipeline保存(上图7--8)
5.Spider发现新的url经Engine再交给Scheduler进行下一个循环。直到无Url请求程序停止结束(上图7--8)

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步