全国大学生数学建模2021年A题(部分公式未展示)
基于决策树算法的互联网金融信贷预测
摘要
随着互联网的发展和大数据技术的兴起,金融行业作为互联网的热门行业之一,在这两年更是爆发出了蓬勃向上的势头。如何把握资金质量、资金集中管理、以及风险管理成为互联网金融信贷的重点关注问题。本文针对互联网金融信贷预测问题展开一系列研究。
对于问题1,首先进行数据的预处理操作,从两种数据类型(文本类型和数据类型)入手找出缺失值和异常值,分别采用填充法和删除法进行数据的处理。对于文本类型,利用Excel工具筛选出缺失值,共计7420个,之后选择文本类型中信息最具体的内容,采用单一值填充法对缺失值进行填充;对于数据类型,利用SPSS的缺失值分析,得到单变量统计表,确定month列缺失8个数据,根据month占比图,采用单一值填充法将缺失值填充12。再利用箱型图找出异常值,结果表明: month、money、type三列数据中存在异常值,共计16个。由于异常值数量相较于数据总量较少,删除异常值对数据影响甚微,选择将异常值删除。
对于问题2,利用问题1中数据预处理后得到的新的数据集,提取 remark列中的8个可能影响放贷的因素:是否缴纳社保及公积金、是否有车房、有无逾期记录、负债情况、薪资情况、文化程度、婚姻状况、职业。采用决策树算法将影响因素划分为不同的区域,对放贷风险进行评级,利用熵和Gimi系数对信息纯度进行度量,求出影响因素对放贷的信息增益,之后通过决策树叶子节点对基本信息进行交叉验证确立评价函数,评价函数即为决策树精化过程中的损失函数,最后根据评价函数建立其放贷模型。
对于问题3,首先运用Pearson相关分析法,得到影响放贷的各个因素之间的双变量相关性,选择皮尔逊相关系数,利用sig值得出相关性矩阵,根据相关性矩阵得到影响放贷模型的各个因素之间均存在较强的相关性。之后根据影响贷款是否成功的因素,建立二元Logistic回归模型,利用SPSS选取对影响放贷的因素进行分析处理,采用0-1规划得出二元Logistic回归方程。结果表明:影响贷款结果的主要因素为money、type、id。最后,通过在原有操作上对贷款结果是否成功进行预测。
对于问题4,根据放贷模型和贷款结果的影响因素,从个人、社会、国家三个方面给平台提出建议。从把握资金质量、降低信贷风险、健全防控机制等方面出发,结合问题1和问题2所得到的结论,给平台提出合理的建议。
关键词:信贷预测 箱型图 决策树算法 放贷模型 Logistic回归模型
1.
问题的重述
1.1 问题的背景
随着互联网的发展和大数据技术的兴起,金融行业作为互联网的热门行业之一,在这两年更是爆发出了蓬勃向上的势头。互联网金融信贷可以看作是金融领域的一次创新,金融行业的发展与互联网技术的发展可谓息息相关,而互联网金融信贷也成为了各路专家及各大院校的探讨话题。互联网金融信贷中,最突出的两种贷款方式分别为:个人贷款和企业贷款。其中,个人贷款包括住房贷款、个人汽车消费贷款、个人耐用消费品贷款等多种贷款方式,个人贷款主要用途为:满足个人的消费需要;企业贷款包括专项贷款和流动资金贷款两类贷款方式。企业贷款的主要用途为:解决中小微企业的短期资金周转问题,解决资金周转问题。需要注意的一点是,逾期可能性比消费贷款更大,即贷款风险更大。
由于用户数多,业务量大等一系列原因,现在的互联网公司均面临着管理经验缺乏,平台运营不善等诸多问题。几乎所有的贷款平台都存在部分外贷资金无法回收的坏账问题。因此,如何把握资金质量、资金集中管理、以及风险管理成为互联网金融信贷的重点关注问题。目前平台的贷款申请审核工作,主要依赖风控人员的经验,以线下纯人工审核的方式进行。
1.2 问题的提出
线下纯人工审核的方法效率低下、成本高昂、过于主观。根据客户相关信息,用量化手段提高风险管控效率,是各互联网金融企业的迫切需求。为了提高风险管控效率,要求基于平台所提供的数据,查阅相关的文献资料,建立数学模型研究下列问题:
1. 请正确处理缺失值和异常值;
2. 构建评价函数建立放贷模型;
3. 预测贷款结果是否成功;
4. 给平台提出相关建议。
2. 问题的分析
2.1 问题1的分析
对于问题1,首先对原始数据进行预处理,找出数据中的缺失值与异常值,之后,查找处理数据的缺失值和异常值的方法。对于缺失值来说,缺失值即为整个数据集中缺少的信息,附件apply.csv中数据的缺失属于完全随机缺失,缺失值常见的处理方法有:删除缺失值法、单一值填补法、k近邻法、多重插补MI法等,由于单一值填补法不需要做大量工作来创建插补集并进行结果分析且与其他数据特征无关。所以计划采用单一值填补法对数据的缺失值进行填充;对于异常值来说,异常值指的是数据集中存在着的不合理的值,常见的处理数据异常值的方法为:简单统计分析法、箱型图分析法、平均值修正法等,由于箱型图分析法可以粗略地看出数据是否具有对称性、数据的分散程度,所以计划采用箱型图分析法对数据的异常值进行处理。
2.2 问题2的分析
对于问题2,对数据进行预处理之后,得到新的数据集。基于新的数据集,构建评价函数建立放贷模型,要考虑互联网金融信贷的风险,风险大的不予放贷,风险小的方可放贷。对于个人信贷风险,需要从其薪资、存款、现有固定财产等不同方面综合考虑,首先从remark中提取个人相关信息,共有以下八种情况:是否缴纳社保及公积金、是否有车房、有无逾期记录、负债情况、薪资情况、文化程度、婚姻状况、职业。由于决策树算法具有准确性高、便于理解、可以清晰的显示重要字段、可以处理连续和种类字段等优点,预计使用决策树算法进行放贷模型的求解。可以将提取出来的八种情况代入决策树风险评级,通过决策树评级将影响因素划分为不同的区域,确定是否放贷的评价函数,最后根据评价函数建立金融放贷模型。
2.3 问题3的分析
对于问题3,首先需要确定影响贷款是否成功的因素之间的相关关系,再判断在以上因素中,哪些因素对贷款结果有较大的影响,利用这些对贷款结果有较大影响的因素对是否贷款成功进行预测。
预测是否贷款成功,考虑两个方面的因素:申请贷款状态(xd_score)和贷款是否成功状态(sms_reply)。由于SPSS可以直接进行双变量分析,其中皮尔逊相关分析可以在分析时一次放入多个变量。通过皮尔逊相关性分析对数据进行处理,对得到的相关性表中的结果进行分析,可以通过比较sig值与0.05的大小确定各个因素的相关关系,在建模过程中考虑两者的直观性,选择直观性较为明显的方法;接着考虑给出的7个因素中,哪些因素对贷款是否成功有较大的影响,Logistic回归具有预测、判断、求概率三大用途,计划使用Logistic回归模型,将影响因素作为自变量,是否贷款成功作为因变量进行回归分析,这里需要注意的是,只有成功申请贷款后,才能进行是否贷款成功的判断。由于回归的结果是综合所有进入回归方程的自变量对因变量的结果而成的,所以这种方法更适用于本题的求解,之后利用回归方程得到对贷款结果影响较大的因素。最后对是否贷款成功进行预测,得出预测结果。
2.4 问题4的分析
对于问题4,给平台提出建议,要结合所建立的放贷模型及决策树模型,从三个方面考虑:个人层面、社会层面、国家层面。由题意知互联网金融信贷重点关注问题是如何把握资金质量、资金集中管理、以及风险管理,所以提出的建议更应该侧重于如何去提高资金的质量、如何去进行有效地资金管理及如何提高风险管理的效率。在个人层面还要考虑到:目前平台的贷款申请审核工作,主要依赖风控人员的经验,以线下纯人工审核的方式进行。所以还需要考虑如何去提高服务人员的责任意识。
3. 模型的假设
针对所给问题,考虑各种因素对建模的影响,给出如下假设:
1. 假设外界因素对互联网金融贷款没有影响;
2. 假设不出现金融危机等特殊情况;
3. 假设所给数据真实可靠。
4. 符号说明
表 1 符号说明表
|
符号 |
说明 |
|
手机号码归属地 |
|
|
城市ID |
|
|
申请额度 |
|
|
贷款期限 |
|
|
申请类型 |
|
|
id号码 |
|
|
|
两个不同的事件 |
|
|
对该事件可能产生的期望 |
|
|
变量的熵对条件的期望 |
|
|
两事件同时发生的信息量 |
|
|
影响放贷因素的信息增益 |
|
|
评价函数 |
|
|
决策树的根节点 |
|
|
评判标准 |
|
随机事件发生的概率 |
5. 模型的建立与求解
针对题目中给出的四个问题,在建立数学模型前,我们首先需要对数据进行预处理操作,正确处理数据中的缺失值和异常值,之后得到新的数据集,在新数据集的基础上才能建立相应的模型进行问题的求解,最后给出互联网金融信贷策略。数据预处理的流程图如图1所示
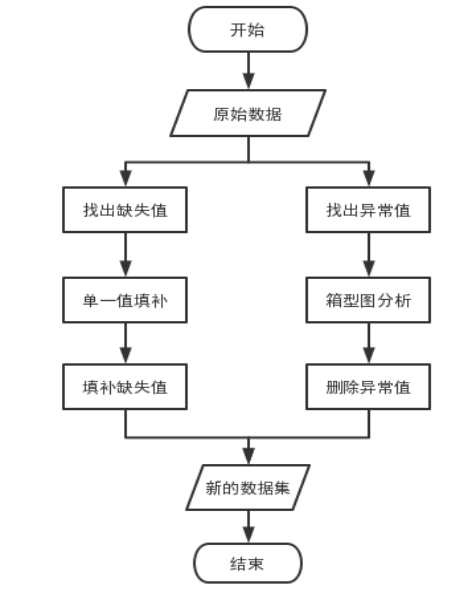
图 1 数据预处理流程图
5.1 问题1的求解
5.1.1 缺失值的处理
附件apply.csv中同时存在数据类型和文本类型,不能直接导入SPSS,选择利用Excel处理apply.csv中展示的15列数据,找出文本类型的缺失值,可以直观看出remark列中存在缺失值,接着利用Excel对remark列进行筛选,得到缺失值共有7420个。对于上述文本类型的缺失,由于缺失个案数较多,直接删除会影响数据的可靠程度,因此选用单一值填充法对缺失文本进行填充。remark列中不同的type信息格式填写的条件、备注不同,选择信息较为具体的一项进行填充,均填充为“出生日期:1989年7月<br />工作所在地:南宁<br />公司单位性质:私企<br />工资发放形式:打卡<br />月收入:4000~5000<br />是否缴纳社保:无缴纳<br />是否缴纳公积金:无缴纳<br />有无逾期记录:无<br />名下是否有房:无<br />名下是否有车:无”。
将其他数据导入SPSS,利用SPSS对其他列进行缺失值分析,得到单变量统计表如表2所示
表 2 单变量统计表
|
单变量统计 |
|||||||
|
|
个案数 |
平均值 |
标准 偏差 |
缺失 |
极值数a |
||
|
计数 |
百分比 |
低 |
高 |
||||
|
money |
14783 |
147.05 |
3742.639 |
0 |
0 |
0 |
33 |
|
month |
14775 |
19.76 |
14.449 |
8 |
0.1 |
0 |
259 |
|
type |
14783 |
6.70 |
5.532 |
0 |
0 |
0 |
1254 |
|
parent_id |
14783 |
63926.09 |
361921.712 |
0 |
0 |
0 |
453 |
|
status |
14783 |
|
|
0 |
0 |
|
|
由上表可以看出,月份一列不同于其他数据列,缺失了8个数据。对于缺失的数据,根据互联网金融信贷的具有一定的规律性,选择最频繁的贷款期限进行填充。将贷款期限的各个月份占比进行统计,得出统计图如图2所示
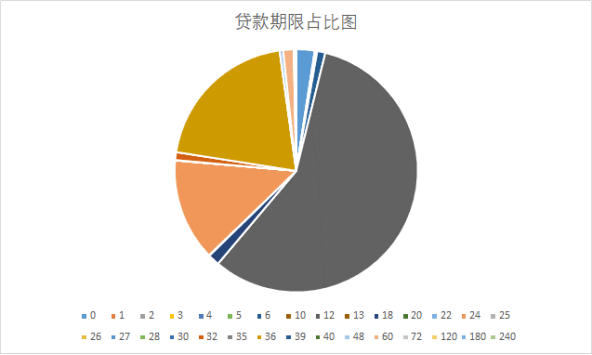
图 2 贷款期限占比图
由上图可知,贷款期限为12个月是大众选择最多的贷款期限,因此,将月份缺失的8个数据均填充为12。
5.1.2 异常值的处理
对于异常值,首先采用箱型图找出异常值,箱型图是利用数据中的五个统计量:最小值、第一四分位数、中位数、第三四分位数和最大值来描述数据的一种方法,它也可以粗略地看出数据是否具有对称性,分布的分散程度等信息,特别可以用于对几个样本的比较。利用箱型图分析法寻找异常值,需要用到SPSS软件。操作步骤为:【分析】—【描述统计】—【探索】,在绘制图形框中选择想要的图形,如正态QQ图,箱型图,茎叶图等。本文采用正态QQ图判断各个因素中出现的明显偏离大多数观测值的个别值。如图3、4、5所示。
图 3 影响因素id的异常值图
图 4 影响因素gsd_zone_id的异常值图
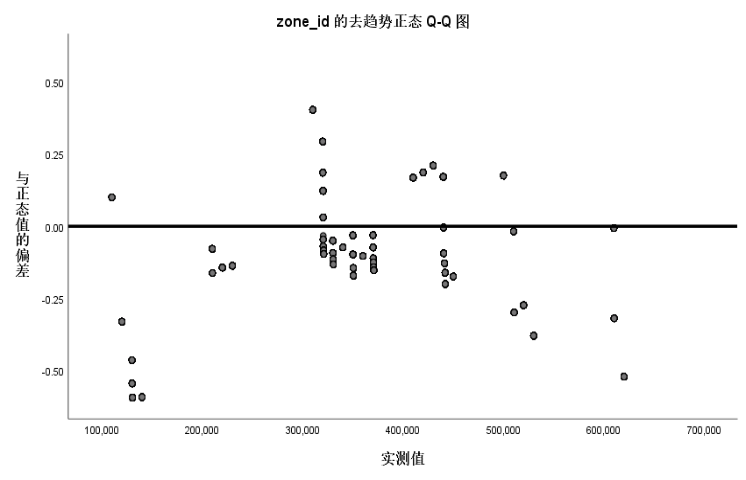
图 5 影响因素zone_id的异常值图
由上面三个正态图可以看出,id、gsd_zone_id、zone_id三列中均不存在异常值。于是只需要考虑剩下的因素中可能存在异常值的因素。由于影响因素id与其他因素的差异较大,且不存在异常值,这里只列出其他5种影响因素的箱型图如图6所示
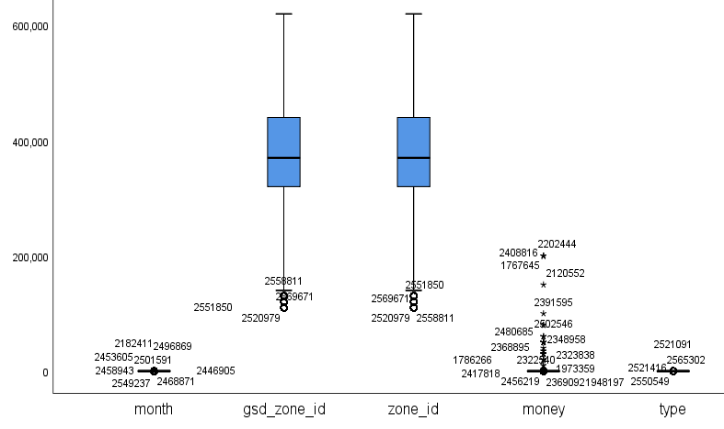
图 6 影响因素的异常值箱型图
为了能够清楚地查找出异常值,分别列出month、money、type的箱型图如图7、图8、图9所示
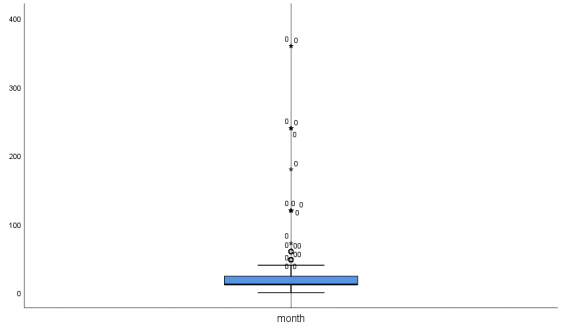
图 7 影响因素month的异常值箱型图
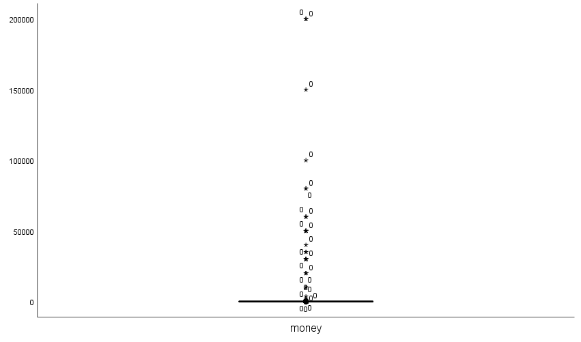
图 8 影响因素money的异常值箱型图
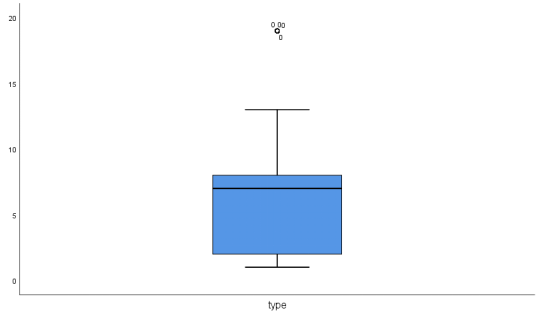
图 9 影响因素type的异常值箱型图
结合以上三个图,可以确定数据的异常值存在于month、money、type三列数据中,其中,month列存在5个异常值,money列存在10个异常值、type列存在1个异常值。异常值的存在会影响数据的准确性,考虑到存在的异常值相较于附件中的数据占比极少,直接删除并不会影响数据的可靠程度,所以选择将异常值直接剔除。
5.2 问题2的建模与求解
在复杂的决策情况中,往往需要多层次或多阶段的决策。决策树算法是一种简单易用的非参数分类器,是一种以实例为基础的归纳学习方式,从无序无规则的信息中归纳出分类的规律。如果从关联规则的角度看,树的各个分支就是各个规则,由此可以通过树模型的结构来为金融机构提供放贷策略。决策树风险评级的示例图如图10所示。
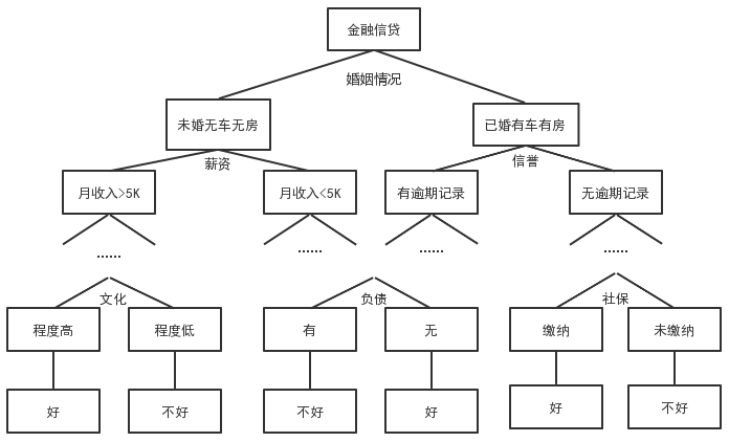
图 10 决策树风险评级示例图
从决策树风险评级示例图可以看出,决策树将所给的影响放贷的因素按照不同特征划分成了不同的区域,用“好”“不好”表示对客户的模糊评价,也同时代表还贷能力,通过各个影响因素的属性值在决策树上由根到叶子节点测试结果,对互联网金融信贷的还贷风险进行评价。
5.2.1 确定评价函数
使用决策树时,对所给的信息具有两点要求:某事件发生概率小,则该事件的信息量大;如果两事件独立,根据概率学统计可得
(1)
则两者同时发生的信息量为
(2)
其中,表示概率;分别表示两种事件;代表信息量。
根据从remark中提取出的八种信息情况:是否缴纳社保及公积金、是否有车房、有无逾期记录、负债情况、薪资情况、文化程度、婚姻状况、职业。基于以上所给的决策树算法使用称为信息增益的基于商(Entropy),这里指的是影响放贷因素的信息增益的基于商(Entropy)。通常利用熵和Gini系数来对信息的纯度进行度量,计算熵值及Gini系数的公式为
(3)
(4)
(5)
其中,表示随机事件发生的概率,表示信息量,它度量了一个具体事件发生所带来的信息,其与事件发生的概率成负相关;熵则是对该事件可能产生的信息量的期望,即所有可能发生事件所带来的信息量的期望总和;条件熵表示在有条件限定时该事件信息量的期望总和,即变量的熵对条件的期望。影响放贷因素的信息增益为
(6)
信息增益表示在一定条件下的信息复杂度,即不确定性的减少程度。由于决策树的叶子节点(又称剪枝)过多会产生过拟合现象,所以我们将过多的剪枝删去,在图13中体现出了八种影响放贷的因素,但在remark中,其影响因素远大于八种,对其进行结合交叉验证,将每个非叶子节点均进行交叉验证来得到评价结果,具体评价函数即为验证过程中的损失函数,评价函数越小即损失越小。评价函数公式[10]为
(7)
(8)
其中,R与r分别表示剪枝前后的决策树的根节点;显然,图10表示的是剪枝后的决策树。
利用评价函数可以衡量该节点的重要性。例如,叶子节点薪资情况和文化程度,若薪资情况的评价函数大于文化程度的评价函数,则薪资情况对于是否放贷的影响较大。
5.2.2 建立放贷模型
以公式(6)和公式(7)的评价函数为基础,可以得到放贷模型。当剪枝前后的损失函数相等时,放贷模型可表示为
(9)
其中,被看作是一个评判标准,越大则个人或企业贷款的还贷风险越大,其还贷能力越低,此时将不予放贷。
5.3 问题3的建模与求解
判断贷款结果是否成功,首先对附件中所给的因素进行双变量分析,判断各个因素之间的相关性;之后通过建立二元回归模型,利用SPSS选取指标进行处理,得出二元回归方程确定影响贷款结果的因素;最后通过贷款结果的影响因素预测贷款结果是否成功。
5.3.1 由双变量相关性确定相关关系
利用SPSS进行双变量分析,由于本文分析时涉及到的因素较多,进行双变量分析时需要一次放入多个变量,因此选择皮尔逊相关分析进行处理。将影响贷款结果的7个因素全部导入到变量中,选择皮尔逊相关系数,通过双尾显著性检验得到各个因素相关性如表3所示。
表 3 相关性表
|
相关性 |
||||||||
|
|
|
id |
gsd_zone_id |
zone_id |
money |
month |
type |
xd_score |
|
id |
皮尔逊相关性 |
1 |
-0.003 |
-0.003 |
-0.099 |
0.021 |
0.001 |
-0.007 |
|
|
Sig.(双尾) |
|
0.979 |
0.979 |
0.365 |
0.850 |
0.993 |
0.949 |
|
|
个案数 |
85 |
85 |
85 |
85 |
85 |
85 |
85 |
|
gsd_zone_id |
皮尔逊相关性 |
-0.003 |
1 |
1.000** |
0.015 |
0.001 |
0.193 |
-0.035 |
|
|
Sig.(双尾) |
0.979 |
|
0.000 |
0.889 |
0.993 |
0.077 |
0.754 |
|
|
个案数 |
85 |
85 |
85 |
85 |
85 |
85 |
85 |
|
zone_id |
皮尔逊相关性 |
-0.003 |
1.000** |
1 |
0.015 |
0.001 |
0.193 |
-0.035 |
|
|
Sig.(双尾) |
0.979 |
0.000 |
|
0.889 |
0.993 |
0.077 |
0.754 |
|
|
个案数 |
85 |
85 |
85 |
85 |
85 |
85 |
85 |
|
money |
皮尔逊相关性 |
-0.099 |
0.015 |
0.015 |
1 |
-0.039 |
0.162 |
-0.056 |
|
|
Sig.(双尾) |
0.365 |
0.889 |
0.889 |
|
0.720 |
0.138 |
0.611 |
|
|
个案数 |
85 |
85 |
85 |
85 |
85 |
85 |
85 |
|
month |
皮尔逊相关性 |
0.021 |
0.001 |
0.001 |
-0.039 |
1 |
0.103 |
-0.089 |
|
|
Sig.(双尾) |
0.850 |
0.993 |
0.993 |
0.720 |
|
0.348 |
0.417 |
|
|
个案数 |
85 |
85 |
85 |
85 |
85 |
85 |
85 |
|
type |
皮尔逊相关性 |
0.001 |
0.193 |
0.193 |
0.162 |
0.103 |
1 |
0.034 |
|
|
Sig.(双尾) |
0.993 |
0.077 |
0.077 |
0.138 |
0.348 |
|
0.759 |
|
|
个案数 |
85 |
85 |
85 |
85 |
85 |
85 |
85 |
|
xd_score |
皮尔逊相关性 |
-0.007 |
-0.035 |
-0.035 |
-0.056 |
-0.089 |
0.034 |
1 |
|
|
Sig.(双尾) |
0.949 |
0.754 |
0.754 |
0.611 |
0.417 |
0.759 |
|
|
|
个案数 |
85 |
85 |
85 |
85 |
85 |
85 |
85 |
根据相关性表,提取出sig值的数据,建立相关性矩阵:
由相关性矩阵可以得到7个影响因素之间均存在较强的相关性。
5.3.2 建立二元Logistic回归模型
贷款结果是否成功,受到多种因素的影响,如id、month、money、type等。判断货款是否成功的流程如图11所示:
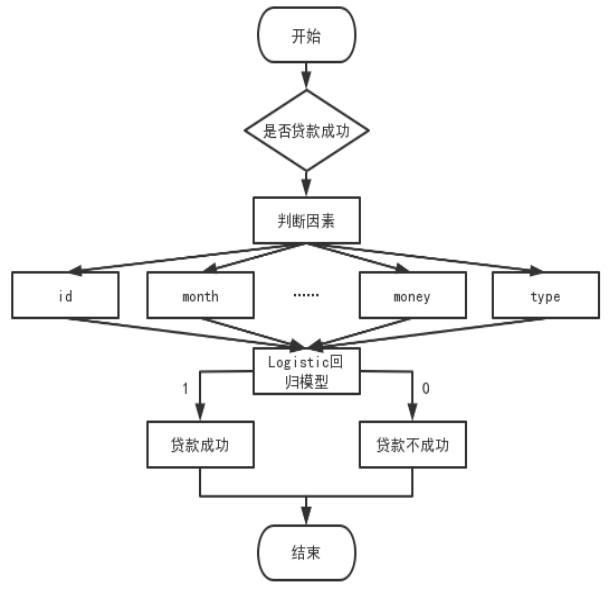
图 11 判断贷款是否成功流程图
贷款结果只有两种:成功或不成功,即可以将此问题化作0-1规划问题,把定义为贷款成功,定义为贷款不成功,可以得到:
(10)
通过p=p(y=1)的Logit变换建立回归公式:
(11)
其中:为因变量取值为1的概率,为发生比。
之后利用SPSS进行分析,因变量为贷款不成功现象,协变量为贷款不成功现象的影响因素。通过一定的指标要求,如值、概率等优先的变量逐个进行处理。得到的数据处理情况汇总如表4所示:
表 4 相关性表
|
个案处理摘要 |
|||
|
未加权个案数a |
个案数 |
百分比 |
|
|
选定的个案 |
包括在分析中的个案数
|
85 |
0.6 |
|
缺失个案数 |
14698 |
99.4 |
|
|
总计 |
14783 |
100.0 |
|
|
未选定的个案 |
0 |
0 |
|
|
总计 |
14783 |
100.0 |
|
从表中可以看出此处不存在缺少个案数,85行记录均被纳入了下面的分析。为了使方程具有显著意义,将系列的哑变量纳入方程,表5为在起始块处尚未纳入分析方程的侯选变量。
表 5 未包含在方程中的变量表
|
未包括在方程中的变量a |
|||||
|
|
得分 |
自由度 |
显著性 |
||
|
步骤 0 |
变量 |
13.265 |
1 |
0 |
|
|
9.205 |
1 |
0.002 |
|||
|
56.054 |
1 |
0 |
|||
|
18.931 |
1 |
0 |
|||
|
3.526 |
1 |
0.06 |
|||
|
106.238 |
1 |
0 |
|||
之后进行纳入变量,开始步骤1的拟合,根据设定,拟合所采用的方法为Forward。对每个步骤、块和模型进行Omnibus检验,如表6所示。可以得到每个步骤的卡方值、自由度和显著值。
表 6 模型系数的Omnibus检验表
|
模型系数的 Omnibus 检验 |
||||
|
|
卡方 |
自由度 |
显著性 |
|
|
步骤 1 |
步骤 |
102.935 |
1 |
0 |
|
块 |
102.935 |
1 |
0 |
|
|
模型 |
102.935 |
1 |
0 |
|
|
步骤 2 |
步骤 |
70.346 |
1 |
0 |
|
块 |
173.282 |
2 |
0 |
|
|
模型 |
173.282 |
2 |
0 |
|
|
步骤 3 |
步骤 |
55.446 |
1 |
0 |
|
块 |
228.728 |
3 |
0 |
|
|
模型 |
228.728 |
3 |
0 |
|
接着进行预测情况的汇总,经过多次步骤处理,准确率最终上升到了81.4%。正确百分比的变化如表7所示:
表 7 分类表a
|
分类表a |
|||||
|
|
实测 |
预测 |
|||
|
|
是否曾经违约 |
正确百分比 |
|||
|
|
否 |
是 |
|||
|
步骤 1 |
是否贷款成功 |
否 |
490 |
27 |
94.8 |
|
是 |
137 |
46 |
25.1 |
||
|
总体百分比 |
|
|
76.6 |
||
|
步骤 2 |
是否贷款成功 |
否 |
481 |
36 |
93.0 |
|
是 |
110 |
73 |
39.9 |
||
|
总体百分比 |
|
|
79.1 |
||
|
步骤 3 |
是否贷款成功 |
否 |
477 |
40 |
92.3 |
|
是 |
99 |
84 |
45.9 |
||
|
总体百分比 |
|
|
80.1 |
||
最后分别给出3个步骤的拟合情况,最后可以得到共有三个变量可以作为二元Logistic回归方程中的参数,分别为:money、type、id。各变量的变量检验情况列表如表8所示:
表8 方程中的变量
|
方程中的变量 |
|||||||
|
|
B |
标准误差 |
瓦尔德 |
自由度 |
显著性 |
Exp(B) |
|
|
步骤 1a |
0.132 |
0.014 |
85.377 |
1 |
0 |
1.141 |
|
|
常量 |
-2.531 |
0.195 |
168.524 |
1 |
0 |
0.080 |
|
|
步骤 2b |
-0.141 |
0.019 |
53.755 |
1 |
0 |
0.868 |
|
|
0.145 |
0.016 |
87.231 |
1 |
0 |
1.156 |
||
|
常量 |
-1.693 |
0.219 |
59.771 |
1 |
0 |
0.184 |
|
|
步骤 3c |
-0.244 |
0.027 |
80.262 |
1 |
0 |
0.783 |
|
|
0.088 |
0.018 |
23.328 |
1 |
0 |
1.092 |
||
|
0 .503 |
0.081 |
38.652 |
1 |
0 |
1.653 |
||
|
常量 |
-1.227 |
0.231 |
28.144 |
1 |
.000 |
0.293 |
|
根据上表,可以得到二元回归方程如下:
(12)
回归公式为:
(13)
由此可以得出结论:money、type、id对是否贷款成功有较大的影响。
5.3.3 预测结果及分析
利用对贷款结果影响较大的3个因素对14698条未回复的现象做出预测,在原有的SPSS操作基础上进行,得出预测结果。由于数据过多,只显示部分预测结果(全部预测结果见附录Ⅰ),如图12所示
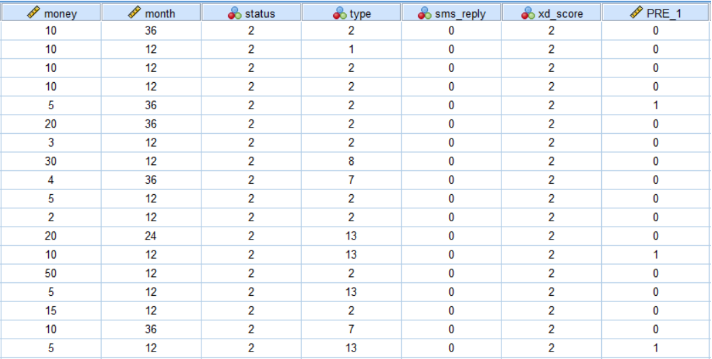
图 12 部分预测结果图
5.4 问题4的建模与求解
5.4.1 个人层面
(1)在把握资金质量方面,应该加强个人对互联网金融信贷的关注度,增强参与互联网金融信贷的绿色环保意识,谨防上当受骗。如果作为放贷人员的话,要在客户选择上下功夫,认真做好贷前调查,确保每笔贷款都有真实的贸易背景;认真核实客户提供的信息,提高识别风险的能力,确保上报审批资料的真实有效性,从而提高资金质量。
(2)在金融信贷风险方面,应当充分利用各种渠道如抖音、快手、朋友圈等平台宣传互联网金融信贷的相关知识,避免较高的信贷风险。进行投融资的个人或企业也应该对放贷平台进行综合素质考察,降低风险。
(3)人人都应提高自身的文化程度和信誉度,按时缴纳社保和公积金,尽可能的拥有一份稳定的工作,努力提高自己的薪资水平,让自己进行投资、融资、贷款时多一份底气,也减轻放贷服务人员的劳动量。
5.4.2 社会层面
(1)在信贷风险方面,完善各个金融信贷平台的风险评级制度。对互联网金融信贷进行全面的风险环节评估,建立完善的绿色金融市场,严格监管、认真审核;还可以建立专门的信贷风险评估部门,对互联网金融信贷进行专业化的识别、评估与决策,以防止出现融资风险过高的情况。
(2)健全个人信贷与企业信贷的风险防控机制,建立信息披露平台和互联网金融风险监测预警机制,根据设立的各个指标进行资金质量的评估,以此来完善互联网金融信贷风险防控机制。同时,提前制定互联网金融信贷风险预案,建立风险转移机制,考虑各类风险的应对措施,按重要性等级依次对风险问题实施解决措施,提高风险管控效率。
(3)在资金集中管理方面,完善企业内部控制。金融企业要定期检查内部控制整体流程的完整性,必要时利用情景模拟、压力测试等方法进行极端金融事件检测,完善相关内部体系,提高资金的集中管理效率。
5.4.3 国家层面
(1)在资金集中管理方面,政府需提供资金上的支持,提高各个平台参与金融信贷的积极性;完善金融政策支持体系,使用政策手段来弥补互联网金融的不足之处。出台依靠强制力保证实施的相关法律法规,加大追责力度,同时加大对资金集中管理力度。
(2)中央在全国以及国际上推行各种战略合作与互联网金融信贷行业的紧密程度,在国家层面出台一系列优惠政策与机遇,带动整个金融市场在自身利益受到保护的前提下积极响应政府号召,加大对互联网金融信贷的发展力度,推动行业的发展。
(3)为了提高服务人员的责任意识,政府必须制定严格的法律法规对个人或企业的污染行为进行处罚。以国家法律法规为依据,全面分析不良贷款的因素,准确评价各环节责任人的执行情况。依据相关规章制度对责任人进行责任认定和处理,促进信贷管理水平的提高,降低放贷风险。
6. 模型的检验
6.1 放贷模型的检验
通过决策树建立放贷模型后,采用BP神经网络对放贷模型进行检验。通过多层反馈调整,对确定放贷模型是否合理。BP神经网络结构图如图16所示。
(14)
图 16 神经网络结构图
数据从输入端进入,信号正向传播时,对于给定的参数集合通过激活函数计算输出结果,本文采用Sigmoid函数进行激活,计算步骤为
(15)
其中表示第层第单元的激活值(输出值)。当时,为第1层的第个输入值,是第层第个单元与第层第个单元之间的连接参数,是第层第个单元的偏置项。将神经网络的误差进行反向传播采用批量梯度下降法对网络进行求解,其方差代价函数为
(16)
对于本文的数据集,定义整体代价函数
(17)
其中,为权重衰减参数。
采用梯度下降法每一次迭代都按照如下公式对参数进行更新:
(18)
(19)
其中是学习率。通过梯度下降函数对参数进行调节,使误差极小化,误差越小,预测的结果就会越好。带入本文放贷模型,经检验,模型的准确率达到了95%,故建立的放贷模型较为合理。
7. 模型的评价与推广
7.1 模型的评价
优点:
(1)二元Logistic回归模型可以分析多个变量的情况,能够准确判断各个因素之间是否具有相关性,提高数据预测效果。
(2)创建了决策树模型建立评价函数,通过对附件数据的分析,捕捉各个因素之间的相互作用,使得评价函数更贴切实际。
(3)基于大数据建立放贷模型,对于贷款结果的判断更具准确性。
缺点:
(1)决策树模型容易调整考虑样本数据从而失去稳定性。
(2)放贷模型是在历史数据的基础上创建的,当数据更新或贷款条件改变时不具备通用性。
7.2 模型的推广
(1)放贷模型不仅仅用于互联网金融放贷,还可以用于对各个银行的信贷决策,可广泛应用于金融行业。
(2)二元Logistic回归模型应用领域十 分广泛,可以在环境和医学等领域进行预测,判断某人属于某病或属于某种情况的概率有多大。预测、判断、求概率是logistic回归最常用的三个用途,logistic回归几乎已经成了流行病学和医学中最常用的分析方法,也是最成功、应用最广的分析方法。
参考文献
[1] 韩中庚, 陆宜清, 周素静. 数学建模实用教程[M]. 北京: 高等教育出版社, 2013. 200-207.
[2]王爱娥. 基于互联网金融下的信贷逾期预测的研究[D].曲阜师范大学,2019.
[3]周冠南,梁伟超.衡量广义流动性的主要金融指标分析与预测[J].债券,2020(02):52-58.
[4]王珍.基于县域金融风险的定量预测与控制问题研究[J].经济问题,2012(05):117-120.
[5]倪建立,刘颖博.中国金融机构信贷资金规模的预测分析——基于ARIMA模型[J].财经界,2010(24):21.
[6]张国群.关于开展金融预测工作的探讨[J].预测,1983(05):62-63.
[7]姚书淇,孙红梅.商业银行开展绿色金融项目的主要影响因素研究[J].区域金融研究,2020(05):37-41.
[8] 宋安, 刘琦. 出租车保有量评价与预测[J]. 交通科技与经济, 2010, 12(3):34-36.
[9] 王明亮.关于中国学术期刊标准化数据库系统工程的进展[EB/OL]. http://www.cajcd.edu.cn/pub/wml.txt/980810-2.html,1998-08-16/2015-9-12.
附录
附录Ⅰ 数据
附表 1. 问题3中200条预测结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号