CentOS7环境下MySQL主从复制
MySQL集群高可用架构
MySQL主从架构
此种架构,一般初创企业比较常用,也便于后面步步的扩展
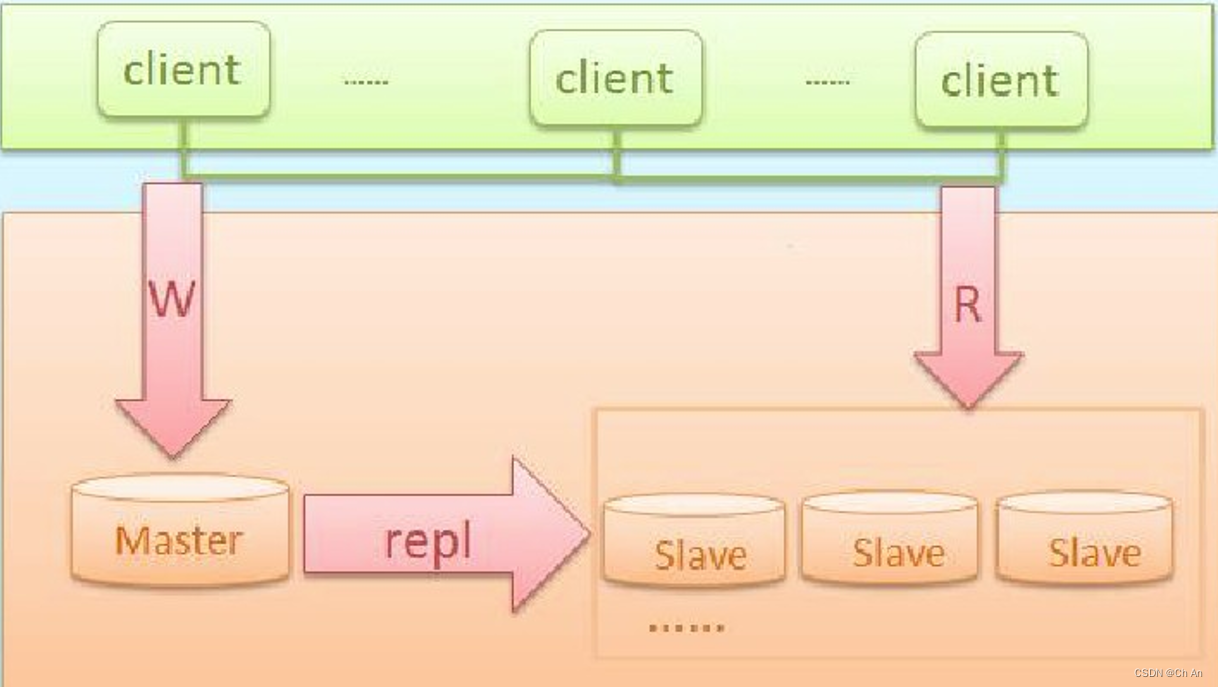
此架构特点:
1、成本低,布署快速、方便
2、读写分离
3、还能通过及时增加从库来减少读库压力
4、主库单点故障
5、数据一致性问题(同步延迟造成)
MySQL+DRDB架构
通过DRBD基于block块的复制模式,快速进行双主故障切换,很大程度上解决主库单点故障问题
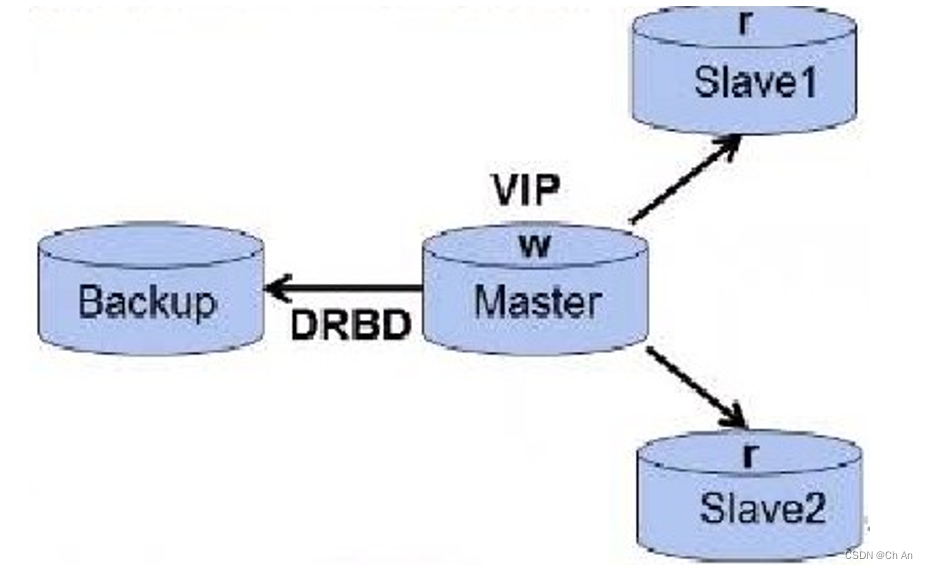
此架构特点:
1、高可用软件可使用Heartbeat,全面负责VIP、数据与DRBD服务的管理
2、主故障后可自动快速切换,并且从库仍然能通过VIP与新主库进行数据同步
3、从库也支持读写分离,可使用中间件或程序实现
MySQL+MHA架构
MHA目前在Mysql高可用方案中应该也是比较成熟和常见的方案,它由日本人开发出来,在mysql故障 切换过程中,MHA能做到快速自动切换操作,而且还能最大限度保持数据的一致性
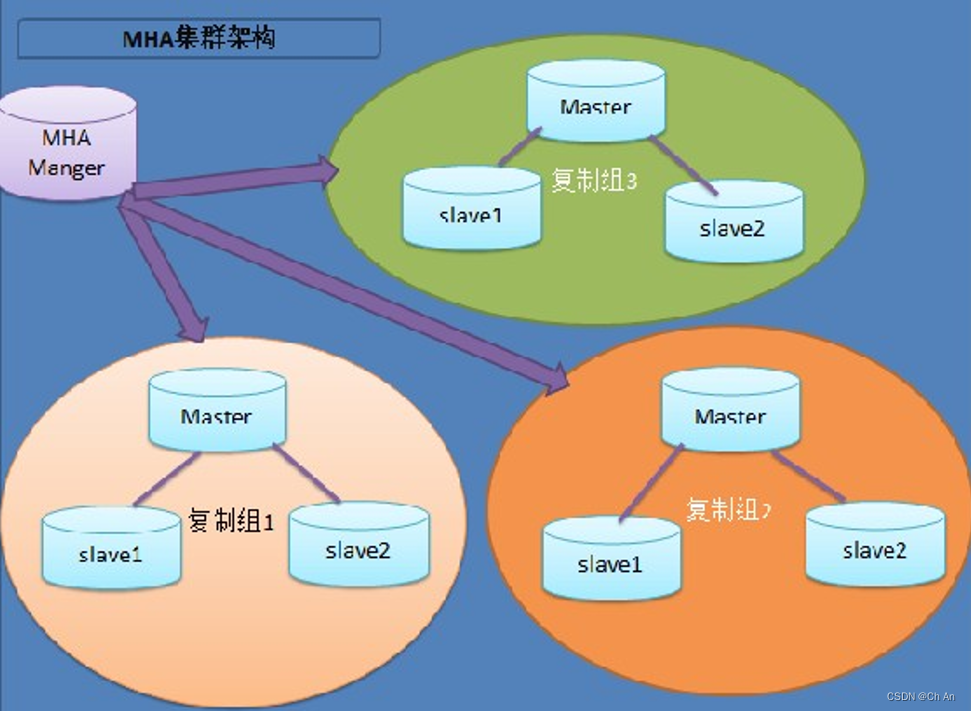
此架构特点:
1、安装布署简单,不影响现有架构
2、自动监控和故障转移
3、保障数据一致性
4、故障切换方式可使用手动或自动多向选择
5、适应范围大(适用任何存储引擎)
MySQL+MMM架构
MMM即Master-Master Replication Manager for MySQL(mysql主主复制管理器),是关于mysql主主复制配置的监控、故障转移和管理的一套可伸缩的脚本套件
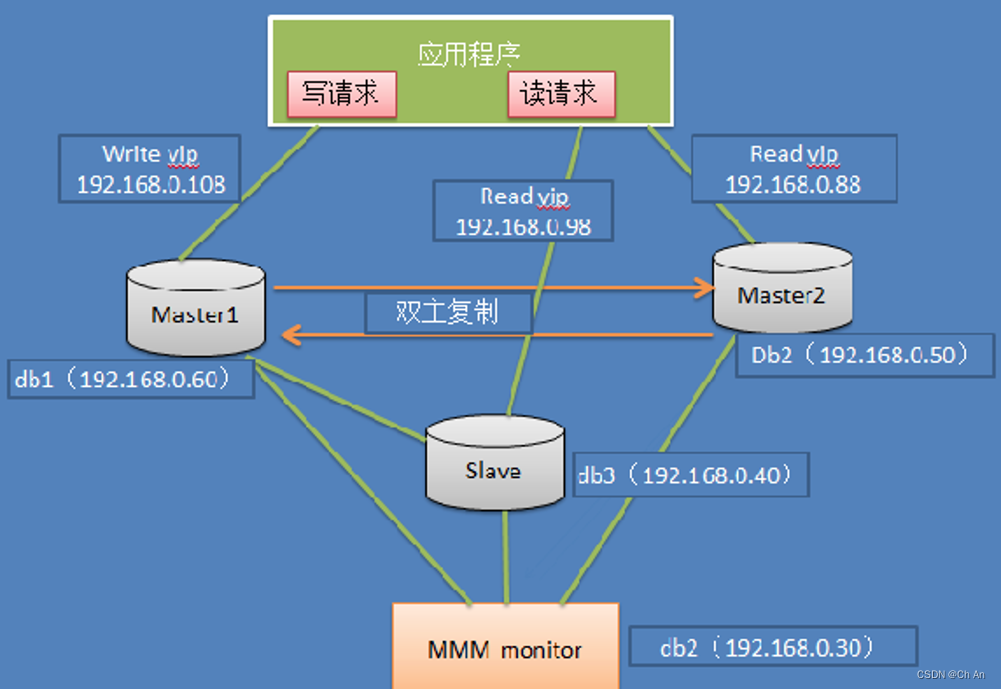
此架构特点:
1、安全、稳定性较高,可扩展性好
2、 对服务器数量要求至少三台及以上
3、 对双主(主从复制性要求较高)
4、 同样可实现读写分离
MySQL主从复制
主从复制原理
主要基于MySQL二进制日志
主要包括三个线程(2个I/O线程,1个SQL线程)
1、MySQL将数据变化记录到二进制日志中;
2、Slave将MySQL的二进制日志拷贝到Slave的中继日志中;
3、Slave将中继日志中的事件在做一次,将数据变化,反应到自身(Slave)的数据库
详细步骤:
1、从库通过手工执行change master to 语句连接主库,提供了连接的用户一切条件(user 、password、port、ip),并且让从库知道,二进制日志的起点位置(file名 position 号); start slave
2、从库的IO线程和主库的dump线程建立连接。
3、从库根据change master to 语句提供的file名和position号,IO线程向主库发起binlog的请求。
4、主库dump线程根据从库的请求,将本地binlog以events的方式发给从库IO线程。
5、从库IO线程接收binlog events,并存放到本地relay-log中,传送过来的信息,会记录到master.info中
6、从库SQL线程应用relay-log,并且把应用过的记录到relay-log.info中,默认情况下,已经应用过的relay 会自动被清理purge
MySQL主从复制实战
环境准备
两台机器一主一从。
主库(MySQL Master):[ip为XXX port为3306]
从库(MySQL Slave ):[ip为XXX port为3306]
主库配置
1) 设置server-id值并开启binlog参数[mysqld]
log_bin = mysql-bin
server_id = 120
重启数据库
2) 建立同步账号
mysql> grant replication slave on *.* to 'rep'@'192.168.95.%' identified by '123456';
mysql> show grants for 'rep'@'192.168.95.%';
3)锁表设置只读
为后面备份准备,注意生产环境要提前申请停机时间;
mysql> flush tables with read lock;
提示:如果超过设置时间不操作会自动解锁。
mysql> show variables like '%timeout%';
测试锁表后是否可以创建数据库:
4) 查看主库状态
查看主库状态,即当前日志文件名和二进制日志偏移量
mysql> show master status;
5) 备份数据库数据
mysqldump -uroot -p -A -B |gzip > /server/backup/mysql_bak.$(date +%F).sql.gz
6) 解锁
mysql> unlock tables;
7) 主库备份数据上传到从库
scp /server/backup/mysql_bak.2015-11-18.sql.gz 192.168.95.130:/server/backup/
从库上设置
1) 设置server-id值并关闭binlog参数
log_bin = /data/mysql/data/mysql-bin
server_id = 130
重启数据库:
2) 还原从主库备份数据
cd /server/backup/
gzip -d mysql_bak.2015-11-18.sql.gz
mysql -uroot -p < mysql_bak.2015-11-18.sql
检查还原:
mysql -uroot -p -e 'show databases;'
3) 设定从主库同步
mysql> change master to
MASTER_HOST='192.168.95.120',
MASTER_PORT=3306,
MASTER_USER='rep',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=329;
4) 启动从库同步开关
mysql> start slave;
检查状态:
mysql> show slave status\G
MySQL主从复制的状况监测
主从状况监测主要参数
Slave_IO_Running: IO 线 程 是 否 打 开 YES/No/NULL
Slave_SQL_Running: SQL线程是否打开 YES/No/NULL
Seconds_Behind_Master: NULL #和主库比同步的延迟的秒数
可能导致主从延时的因素
主从时钟是否一致
网络通信是否存在延迟
是否和日志类型,数据过大有关
从库性能,有没开启binlog
从库查询是否优化
常见状态错误排除
发现IO进程错误,检查日志,排除故障:
tail localhost.localdomain.err
…
2015-11-18 10:55:50 3566 [ERROR] Slave I/O: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work. Error_code: 1593
找到原因:从5.6开始复制引入了uuid的概念,各个复制结构中的server_uuid得保证不一样
解决方法:(从库是克隆机器)
修改从库的uuid
vim auto.cnf
server-uuid=
常见状态错误排除
show slave status;报错:Error xxx doesn’t exist
解决方法:
stop slave;
set global sql_slave_skip_counter = 1;
start slave;
测试主从同步:
主库创建一个数据库:
mysql -uroot -p -e 'create database test_m_s;'
从库检查:
mysql -uroot -p -e 'show databases;' |grep "test_m_s"
生产环境其他常用设置
1、配置忽略权限库同步参数
binlog-ignore-db='information_schema mysql test'
2、从库备份开启binlog
log-slave-updates
log_bin = mysql-bin
expire_logs_days = 7
应用场景:级联复制或从库做数据备份。
3、从库只读
read-only来实现
innodb_read_only = ON或1,或者innodb_read_only
结论:当用户权限中没有SUPER权限(ALL权限是包括SUPER的)时,从库的read-only生效!
主从复制高级进阶
配置延时从库
SQL线程延时:数据已经写入relaylog中了,SQL线程"慢点"运行一般企业建议3-6小时,具体看公司运维人员对于故障的反应时间
mysql>stop slave;
mysql>CHANGE MASTER TO MASTER_DELAY = 300;
mysql>start slave;
mysql> show slave status \G
SQL_Delay: 300
SQL_Remaining_Delay: NULL
延时从库应用
故障恢复思路:
1主1从,从库延时5分钟,主库误删除1个库
1> 5分钟之内 侦测到误删除操作
2> 停从库SQL线程
3> 截取relaylog
起点 :停止SQL线程时,relay最后应用位置终点:误删除之前的position(GTID)
4> 恢复截取的日志到从库
5> 从库身份解除,替代主库工作
故障模拟及恢复:
- 主库数据操作
db01 [(none)]>create database relay charset utf8;
db01 [(none)]>use relay
db01 [relay]>create table t1 (id int);
db01 [relay]>insert into t1 values(1);
db01 [relay]>drop database relay;
- 停止从库SQL线程
stop slave sql_thread;
- 找relaylog的截取起点和终点
起点:
Relay_Log_File: db01-relay-bin.000002
Relay_Log_Pos: 482
终点:
show relaylog events in 'db01-relay-bin.000002'
| db01-relay-bin.000002 | 1046 | Xid | 7 | 2489 |
COMMIT /* xid=144 */
| db01-relay-bin.000002 | 1077 | Anonymous_Gtid | 7 | 2554 | SET
@@SESSION.GTID_NEXT= 'ANONYMOUS' |
mysqlbinlog --start-position=482 --stop-position=1077
/usr/local/mysql/data/db01-relay-bin.000002>/tmp/relay.sql
- 从库恢复relaylog
source /tmp/relay.sql
- 从库身份解除
db01 [relay]>stop slave;
db01 [relay]>reset slave all
var code = “3ba81f30-6d22-4270-941d-77dece2cc5a7”
-------------------------------------------
个性签名:今天做了别人不想做的事,明天你就做得到别人做不到的事,尝试你都不敢,你拿什么赢!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

