
Java开发面试题
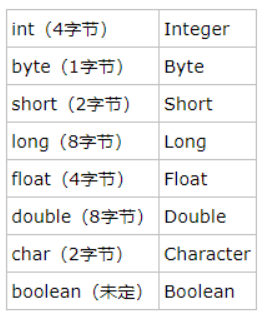
1.Java的基本数据类型有哪些?对应的包装类?
2.开发过程中对String字符串操作的方法(函数)有哪些?分别是什么作用?

3.怎么定义静态变量或方法,静态方法、变量有什么特点,如何使用?
定义:静态数据成员在定义或说明时前面加关键字static
public class AnyThing {
static double PI = 3.1415; //在类中定义静态常量
static int id; //在类中定义静态变量
public static void method1(){ //在类中定义静态方法
}
public void method2(){
System.out.println(AnyThing.PI); //调用静态常量
System.out.println(AnyThing.id); //调用静态变量
AnyThing.method1(); //调用静态方法
}
}
静态成员的提出是为了解决数据共享的问题。实现共享有许多方法,如:设置全局性的变量或对象是一种方法。但是,全局变量或对象是有局限性的。
静态数据成员
在类中,静态成员可以实现多个对象之间的数据共享,并且使用静态数据成员还不会破坏隐藏的原则,即保证了安全性。因此,静态成员是类的所有对象中共享的成员,而不是某个对象的成员。
使用静态数据成员可以节省内存,因为它是所有对象所公有的,因此,对多个对象来说,静态数据成员只存储一处,供所有对象共用。静态数据成员的值对每个对象都是一样,但它的值是可以更新的。只要对静态数据成员的值更新一次,保证所有对象存取更新后的相同的值,这样可以提高时间效率。
4.接口和抽象类有什么异同?
不同点:
抽象类(abstract class):
1.抽象类可以定义构造器、成员变量
2.抽象类中可以有抽象方法、具体方法、静态方法
3.有抽象方法的类必须被声明为抽象类,而抽象类中不一定要有抽象方法
4.一个类只能继承一个抽象类
5.抽象类中的成员可以是private、默认的、protected、public
接口(interface):
1.接口中不能定义构造器、静态方法
2.接口中的方法全部都是抽象方法
3.接口中定义的成员变量实际上都是常量
4.一个类可以实现多个接口
5.接口中的成员全都是public的
相同点:
1.都不能被实例化
2.可以将抽象类和接口类型作为引用类型
3.一个类如果继承了某个抽象类或者实现了某个接口都需要对其中的抽象方法全部进行实现,否则该类仍需要被声明为抽象类
5.I/O中都有哪些流?
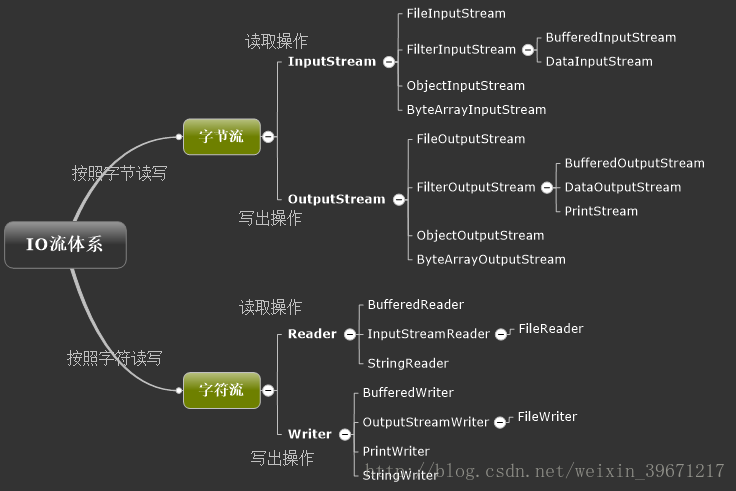
FilInputStream文件输入流(字节输入流)
FilterInputStream过滤输入流(封装其他输入流)
BufferInputStream缓冲输入流
ObjectInputStream 对象输入流
ByteArrayInputStream字节数组输入流
PrintStream字节打印流
InputStreamReader转换流(字节到字符的转换)
OutStreamWrite转换流(字符到字节的转换)
StringWriter 字符输出流
IO流的分类:根据处理数据类型的不同分为:字符流和字节流
根据数据流向不同分为:输入流和输出流
字符流和字节流:字节流:以字节为单位读取的流
字符流:以字符为单位读取的流
字节流和字符流的区别:
读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
结论:只要是处理纯文本数据,就优先考虑使用字符流。 除此之外都使用字节流。
6.什么是缓冲流?有什么作用?
缓冲流是处理流的一种, 它依赖于原始的输入输出流, 它令输入输出流具有1个缓冲区, 显著减少与外部设备的IO次数, 而且提供一些额外的方法.
可见, 缓冲流最大的特点就是具有1个缓冲区! 而我们使用缓冲流无非两个目的:
- 减少IO次数(提升performance性能)
2. 使用一些缓冲流的额外的方法.
使用缓冲处理流包装就是一堆一堆的干活,还能不用CPU多次处理数据转换,只是设置一下数据转换成功后的文件。不使用缓冲处理流包装就是CPU傻傻的一个字节一个字节循环来干活存储写入文件中,相比可见效率明显变慢。
7.常用的集合有哪些?存储方式有什么区别?
常用的集合有:List Set Map
List和Set存储单列数据的集合
Map存储键和值的双列数据集合
List存储的是有序,可以重复的数据集合
Set存储的是无序,不可以重复的数据集合
Map存储的是无序,键不可以重复,值可以重复的数据集合。
8.HashMap和HashTable有什么区别?
HashMap:基于hash表的Map接口实现,非线程安全,高效率,支持null值和null键。
HashTable:线程安全,低效,不支持null值和null键。
9.数组Array和集合List怎么相互转换?
数组Array转集合List:
1.通过 Arrays.asList(strArray) 方式,将数组转换List后,不能对List增删,只能查改,否则抛异常。
2.通过ArrayList的构造器,将Arrays.asList(strArray)的返回值由java.util.Arrays.ArrayList转为java.util.ArrayList。
关键代码:ArrayList<String> list = new ArrayList<String>(Arrays.asList(strArray)) ;
3.通过Collections.addAll(arrayList, strArray)方式转换,根据数组的长度创建一个长度相同的List,然后通过Collections.addAll()方法,将数组中的元素转为二进制,然后添加到List中, 这是最高效的方法。
集合List转数组Array:toArray()
10.简述你对MVC地认识?
MVC是一种设计模式
M-Model 模型(完成业务逻辑:有javaBean构成,service+dao+entity)
V-View 视图(做界面的展示 jsp,html……)
C-Controller 控制器(接收请求—>调用模型—>根据结果派发页面)
11.SpringMVC中你常用的注解有哪些?Ajax使用异步刷新时用到哪个注解?
@RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
@Resource和@Autowired都是做bean的注入时使用,其实@Resource并不是Spring的注解,它的包是javax.annotation.Resource,需要导入,但是Spring支持该注解的注入。
@ResponseBody:该注解用于将Controller的方法返回的对象,通过适当的HttpMessageConverter转换为指定格式后,写入到Response对象的body数据区。
Ajax使用异步刷新时用到的注解@RequestMapping和@ResponseBody
12.简述你对Spring地认识?
Spring 是一个开源框架,Spring 是一个 IOC 和 AOP 容器框架。
Spring 容器的主要核心是:
控制反转(IOC),在 spring 开发模式中,spring 容器使用了工厂模式为我们创建了所需要的对象,不需要我们自己创建了,直接调用 spring 提供的对象就可以了,这是控制反转的思想。
依赖注入(DI),spring 使用 javaBean 对象的 set 方法或者带参数的构造方法为我们在创建所需对象时将其属性自动设置所需要的值的过程,就是依赖注入的思想。
面向切面编程(AOP),在面向对象编程(oop)思想中,我们将事物纵向抽成一个个的对象。而在面向切面编程中,我们将一个个的对象某些类似的方面横向抽成一个切面,对这个切面进行一些如权限控制、事物管理,记录日志等公用操作处理的过程就是面向切面编程的思想。AOP 底层是动态代理,如果是接口采用 JDK 动态代理,如果是类采用CGLIB 方式实现动态代理。
13.MyBatis中Mapper.xml中怎么对数组、集合进行遍历?
<foreach collection="array" open="(" close=")" separator="," item="item">
#{item,jdbcType=INTEGER}
</foreach>
遍历集合:
1.不用注解
public void insertList(List<User> users);
<insert id="insertList" parameterType="java.util.List" >
insert into user (id,name,password,sex,age)
values
<foreach collection="list" open="(" close=")" separator="," item="item">
#{item.id,jdbcType=INTEGER}, #{item.name,jdbcType=VARCHAR},
#{item.password,jdbcType=VARCHAR}, #{item.sex,jdbcType=TINYINT},
#{item.age,jdbcType=INTEGER}
</foreach>
</insert>
2.使用@Param注解
public void insertList(@Param List<User> users);
<insert id="insertList">
insert into user (id,name,password,sex,age)
values
<foreach collection="users" open="(" close=")" separator="," item="item">
#{item.id,jdbcType=INTEGER}, #{item.name,jdbcType=VARCHAR},
#{item.password,jdbcType=VARCHAR}, #{item.sex,jdbcType=TINYINT},
#{item.age,jdbcType=INTEGER}
</foreach>
</insert>
遍历数组Array
1.不用注解
public List<User> selectAllUsers(Integer[] ids);
<select id="selectAllUsers" parameterType="java.util.Array" >
select * from user where id in
<foreach collection="array" open="(" close=")" separator="," item="item">
#{item,jdbcType=INTEGER}
</foreach>
</select>
2.使用@Param注解
public List<User> selectAllUsers(@Param("ids") Integer[] ids);
<select id="selectAllUsers" parameterType="java.util.Array" >
select * from user where id in
<foreach collection="ids" open="(" close=")" separator="," item="item">
#{item,jdbcType=INTEGER}
</foreach>
</select>
14.JSP中的指令有哪些,分别是什么?
指令可以有很多个属性,它们以键值对的形式存在,并用逗号隔开。
JSP中的三种指令标签:

15.JQuery中常用的选择器有哪些?
1、 基本选择器
主要有通过id名查询的id选择器(如:$("#myELement"))、类选择器(如:$(".myClass"))、标签选择器(如:$("div") )以及通用选择器(如:$("*") 选择文档中的所有的元素)。
2、 层次选择器
常见有后代选择器($("form input") 选择所有的form元素中的input元素)、子选择器($("#main > *") 选择id值为main的所有的子元素)、相邻兄弟选择器($("label + input") 选择所有的label元素的下一个input元素节点,经测试选择器返回的是label标签后面直接跟一个input标签的所有input标签元素)、同胞选择器(如:返回id为prev的标签元素的所有的属于同一个父元素的div标签)
3、 过滤选择器:简单过滤选择器、内容过滤选择器、可见性过滤选择器、属性过滤选择器、 子元素过滤选择器 、表单对象属性过滤选择器
3—1、简单过滤选择器,可能会用到的有(以tr、div等标签为例):
$("tr:first")选择所有tr元素的第一个
$("tr:last")选择所有tr元素的最后一个
$("input:not(:checked) + span")过滤掉:checked的选择器的所有的input元素
$("tr:even") 选择所有的tr元素的第0,2,4... ...个元素(注意:因为所选择的多个元素时为数组,所以序号是从0开始)
$("tr:odd") 选择所有的tr元素的第1,3,5... ...个元素
$("td:eq(2)")选择所有的td元素中序号为2的那个td元素
$("td:gt(4)") 选择td元素中序号大于4的所有td元素
$("td:lt(4)")选择td元素中序号小于4的所有的td元素
$(":header")选择h1、h2、h3之类的
$("div:animated")选择正在执行动画效果的元素
3—2 内容过滤选择器
$("div:contains('John')") 选择所有div中含有John文本的元素
$("td:empty")选择所有的为空(也不包括文本节点)的td元素的数组
$("div:has(p)")选择所有含有p标签的div元素
$("td:parent")选择所有的以td为父节点的元素数组
3—3 可视化过滤选择器
$("div:hidden")选择所有的被hidden的div元素
$("div:visible")选择所有的可视化的div元素
3—4 属性过滤选择器
$("div[id]")选择所有含有id属性的div元素
$("input[name='newsletter']")选择所有的name属性等于'newsletter'的input元素
$("input[name!='newsletter']")选择所有的name属性不等于'newsletter'的input元素
$("input[name^='news']")选择所有的name属性以'news'开头的input元素
$("input[name$='news']")选择所有的name属性以'news'结尾的input元素
$("input[name*='man']") 选择所有的name属性包含'news'的input元素
$("input[id][name$='man']")可以使用多个属性进行联合选择,该选择器是得到所有的含有id属性并且那么属性以man结尾的元素
3—1 子元素过滤选择器
查找ul中第2个li $("ul li:nth-child(2)")
查找ul中处于奇数位的li(下标从1开始) $("ul li:nth-child(odd)")
查找ul中1、4、7、10.....位置的li $("ul li:nth-child(3n + 1)")
$("div span:first-child")返回所有的div元素的第一个子节点的数组
$("div span:last-child")返回所有的div元素的最后一个节点的数组
$("div button:only-child")返回所有的div中只有唯一一个子节点的所有子节点的数组
4、表单选择器
$(":input")选择所有的表单输入元素,包括input, textarea, select 和 button
$(":text")选择所有的text input元素
$(":password")选择所有的password input元素
$(":radio")选择所有的radio input元素
$(":checkbox")选择所有的checkbox input元素
$(":submit")选择所有的submit input元素
$(":image")选择所有的image input元素
$(":reset")选择所有的reset input元素
$(":button")选择所有的button input元素
$(":file")选择所有的file input元素
$(":hidden")选择所有类型为hidden的input元素或表单的隐藏域
4—1 表单元素过滤选择器
$(":enabled")选择所有的可操作的表单元素
$(":disabled")选择所有的不可操作的表单元素
$(":checked")选择所有的被checked的表单元素
$("select option:selected")选择所有的select 的子元素中被selected的元素
16.JQuery中Ajax具体写法是什么?
$.ajax({
url:"http://www.baidu.com", //请求的url地址
dataType:"json", //返回格式为json
async:true,//请求是否异步,默认为异步,这也是ajax重要特性
data:{"id":"value"}, //参数值
type:"POST", //请求方式
beforeSend:function(){//请求前的处理
},
success:function(req){//请求成功时处理
},
complete:function(){//请求完成的处理
},
error:function(){//请求出错处理
}
});
17.数据库中你常用的函数有哪些,分别是什么作用?

18.举例说明多表查询语句怎么写?
1.inner join 内连接
select c.RealName,lm.* from Customers c join dbo.LeaveMessages lm on c.UserId=lm.CustomerId
2. outer join外连接
2.1左外连接left outer join左外连接会保证查出左表中的所有数据,右表中无法匹配的项将自动补为NULL。
select pc.Id, pc.Name,p.* from dbo.ProductCatagory pc left outer join dbo.Product p on pc.Id = p.CategoryId
2.2右外连接right outer join右外连接会保证查出右表中的所有数据,左表中无法匹配的项将自动补为NULL。
select pc.Id, pc.Name,p.* from dbo.ProductCatagory pc right outer join dbo.Product p on pc.Id = p.CategoryId
完全连接 full outer join 完全连接会返回左右两表中所有数据,右表无法匹配的项自动补NULL,左表无法匹配的项也自动补NULL
举例:
请你们中的夫妻关系的人手牵手到教堂外边。(内连接)
请男人牵着自己的妻子,如果妻子没在,就牵着空气到教堂外边。(左连接)
请女人牵着自己的丈夫,如果丈夫没在,就牵着空气到教堂外边。(右连接)
请男人和女人都到教堂外边,是夫妻的手牵手,否则牵着空气。(完全连接)
19.怎么进行SQL优化?
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询select id from t where num=0
3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:select id from t where num=10 union all select id from t where num=20
5.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
6.下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
7.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:select id from t where num=100*2
8.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)='abc'--name以abc开头的id
应改为:select id from t where name like 'abc%'
9.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
10.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
11.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:create table #t(...)
12.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
13.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
14.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。 一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
15.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
16.尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。17.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
18.避免频繁创建和删除临时表,以减少系统表资源的消耗。
19.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
20.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
21.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
22.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
23.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
24.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时.在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
25.尽量避免大事务操作,提高系统并发能力。
26.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号