
为什么下载大文件时多线程比单线程速度更快?
决定用户下载大文件速度快慢的终极因素,在于用户下载进程实时抢占网络带宽的大小。其它的因素与它相比,可以忽略不计。
任意一个与互联网通信的进程,理论上都有一个实时最大可用带宽,这是客观存在,不以用户意志为转移。 如果 用户进程实时抢占的带宽 = 实时网络可用带宽 那是最最理想的,用户进程100%利用网络带宽,无论进程(Process)是单线程(Thread)的还是多线程的,下载速度几乎没有任何区别。
理想是丰满的,但现实是骨感的,因为: 用户进程实时抢占的带宽 ≤实时网络可用带宽 Forever!!!
既然如此,如果能让用户进程实时抢占的带宽无限接近实时网络可用带宽,那也是非常完美的。可是,实时网络带宽是多少? 没有人知道!实时网络可用带宽每一刻都在变化! 操作系统很愿意为用户效劳,TCP通过流量探测机制,不间断地探测实时网络可用带宽,并将实时的发送速率与之匹配(相等)起来,这个骚操作看起来很美!
为什么这么说呢?传统的TCP流量探测机制有一个非常致命的缺陷:一旦检测到有丢包,立马将发送速率降为1/2。降速1/2后,如果没有丢包,将会在1/2速率的基础上,按照固定的增长值(线性增长),加大发送的速率。接下来就会一直按照这个节奏到达丢包的那一刻(实时可用带宽)为止。然后再1/2降速,循环往复,直到文件下载结束。 如果下一个检测周期依然有丢包现象,会在当前1/2速率的基础上继续降速1/2。剩下的故事情节以此类推。
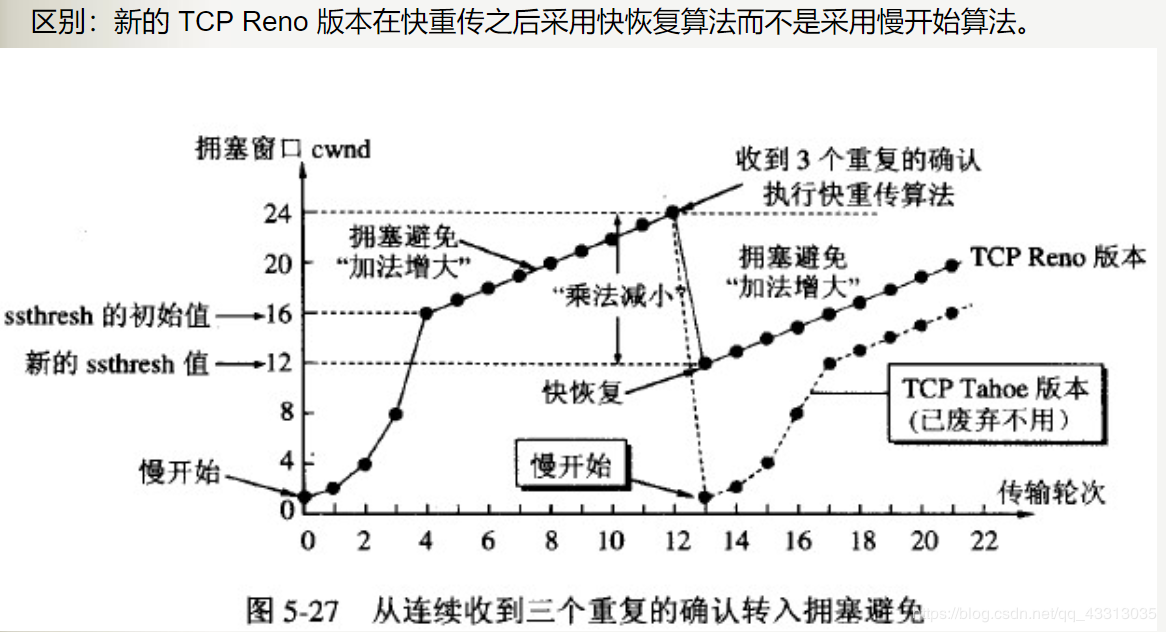
很显然,指数级降速,线性增速,这很不公平!降速很快,但升速却很漫长!造成的直接恶果就是真实的传输速率远远小于实时可用带宽。
多线程相比单线程的优势是,由于有多个线程在竞争实时可用带宽。尽管多线程逻辑上是并行的,但其实还是按时序的串行处理。所以每个线程处于的阶段并不一致。 在任意时刻,有的线程处于丢包被罚1/2降速,有的线程处于2倍增速阶段(SlowStart),而有的线程处于线性增长阶段。通过多个线程的下载速率的加权平均,得到的是一根相对平滑的下载曲线。这条平滑曲线在大多数时候应该位于单线程下载速率的上方。这就是多线程下载速率更有优势的体现。 但是,如果TCP流量探测机制更加智能,比如BBR算法。BBR算法最大的进步,就是摒弃传统TCP流量调度算法(基于是否丢包而升速或降速), BBR采取的是,实时测量网络最大的可用带宽,并将发送速率与之相匹配,一直在实时可用带宽附近小范围徘徊,避免大起大落的情况发生。测量速率能无限接近实时可用带宽,多线程相比单线程,优势就体现不出来了。
本文转载自 VX公众号:车小胖谈网络

 浙公网安备 33010602011771号
浙公网安备 33010602011771号