学习心得:
学习笔记:
在python中一个py文件就是一个模块
模块好处:
1、提高可维护性
2、可重用
3、避免函数名和变量名冲突
模块分为三种:
1、内置标准模块(标准库),查看所有自带和第三方模块总数的方法:help("modules"),带下划线的是系统调用的,我们用的主要是不带下划线的。
2、第三方开源模块,可通过pip install 模块名 联网安装
3、自定义模块
模块调用:
import module
from module import xx
from xx.xx import xx as rename
from module.xx .xx import *
-------------------------------------------------------------------------------------------------------------
import module #会解释整个module
from module import method #会解释整个module,但只引入方法
from package import module #会解释整个module
from package.module import method #会解释整个module,但只引入方法
import package #只执行package下的__init__方法,并不解释包下的所有模块。
注意:模块一旦被调用,即相当于执行了另外一个py文件里面的代码
python找模块的时候会有一些路径,这个路径可以用sys.path显示出来
import sys >>>sys.path #输出结果:['', 'C:\\Python\\Python35\\lib\\site-packages\\pytz-2018.3-py3.5.egg', 'C:\\Python\\Python35\\lib\\ site-packages\\pip-10.0.1-py3.5.egg', 'C:\\Python\\Python35\\python35.zip', 'C:\\Python\\Python35\\D LLs', 'C:\\Python\\Python35\\lib', 'C:\\Python\\Python35', 'C:\\Python\\Python35\\lib\\site-packages '] #第一个空表示当前目录,最后一个site-packages是放标准和第三方模块的地方。
https://pypi.python.org/pypi
下载安装第三方模块:
>>> python setup.py build #setup.py是模块包的中文件名称 >>> python setup.py intall
包和文件夹:
在python2中只能从包导入,如果是从文件夹导入会报错。
python3对此做了优化,从文件夹也可以导入模块。
只有入口程序所在的目录会加入到sys.path中来,不管里面间接调用多少层,和他们没关系。如何理解?看下面。

假如有这样一个目录结构,现在从manage.py进入程序,在manage.py文件中通过from crm import views.py,如果在views.py中想要引入proj下面的settings.py,要怎么引入呢?通过from proj import settings.py,为什么可以这样?views.py和proj不在同一个目录,sys.path中也没这个路径啊,程序是怎么找到proj这个包的呢?其实这块就验证了上面那句话,只有入口程序所在的目录会加入到sys.path中来,而在入口程序中调用其它py文件,其它Py文件再调用另外其它py文件,都是按照这个sys.path路径来查找的。这才是上面问题的本质。因为这个原因,所以项目的入口程序都是放在程序的根目录下的,这样就能很方便的调用所有模块了。
1、从views.py开始运行,在views.py文件中导入proj中的settings.py,实现如下:
import sys,os print(dir()) print(__file__) #my_proj\crm\views.py 显示的路径是从python执行的当前位置开始往后的路径 #也就是说__file__就是这样一个相对路径。 BASE_DIR = os.path.dirname(os.path.dirname(__file__)) #这块的path是os模块的方法,不是sys的 print(BASE_DIR) #my_proj 往上走了两层,获得了当前文件的目录的目录路径,但还是相对路径 BASE_DIR =os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #注意BASE_DIR中只用到了os.path的方法,没有用到sys,这样得到的就是整个绝对路径。 print(BASE_DIR) #C:\Users\Lowry\PycharmProjects\lufyy\my_proj sys.path.append(BASE_DIR) #将BASE_DIR加入到sys.path中 from proj import settings #至此跨模块导入模块就实现了 def sayhi(): print("hello world")
2、从manage.py开始运行程序,如何在views.py中引入module.py模块?
#第一种方法: from crm import module #此种方法每次只能从最外层往里面找,试想里面不是一层而是10层呢?那么from后面就是crm.xx.xx.xx.xx直到views.py所在层。 #第二种方法: from . import module # 这个.代表当前文件目录
3、

第二句的意思是相对路径回到的目录不能是程序入口的那个目录,如果是,则报错。
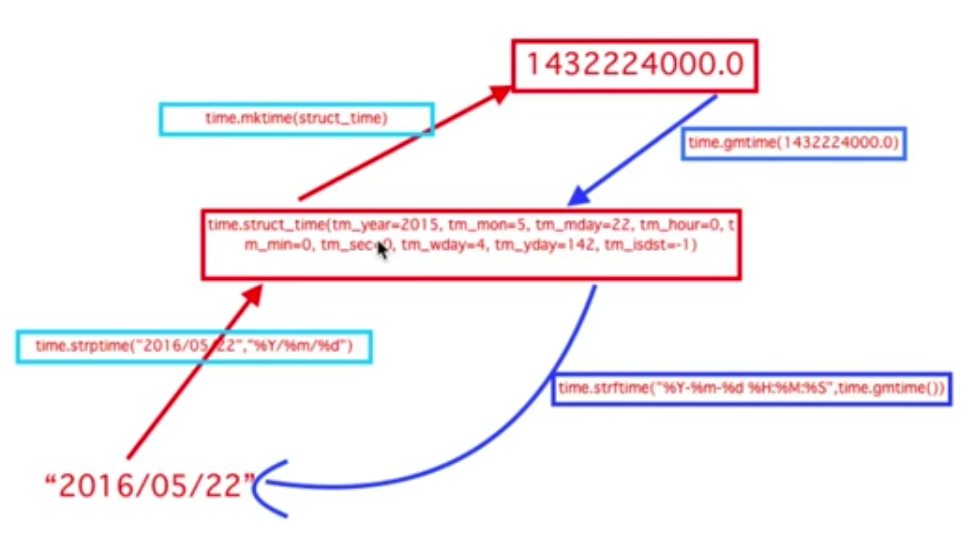
time模块:
import time print(time.localtime()) #拿到的是当前系统时间对象,随系统时间改变而改变。 print(time.mktime(time.localtime())) #将struct_time转换为时间戳
os模块:用于和系统进行交互用的
序列化模块:序列化是指把内存的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes
把字符串转成内存数据类型叫反序列化
只把数据类型转成字符串存到内存里的意义?
json.dumps json.loads
1、把内存数据通过网络共享给远程其它人
2、定义了不同语言之间的交互规则
1、纯文本,坏处,不能共享复杂的数据类型
2、xml,坏处,占空间大
3、json,简单,可读性好
json
支持str、int、tuple、dict、list
pickle
支持python里的所有数据类型
只能在Python里面使用
shelve模块:之前的json和pickle都只能dump和load一次,但这个模块可以dmup和load多次,他是通过对pickle封装得来的,所以只能在python中使用。
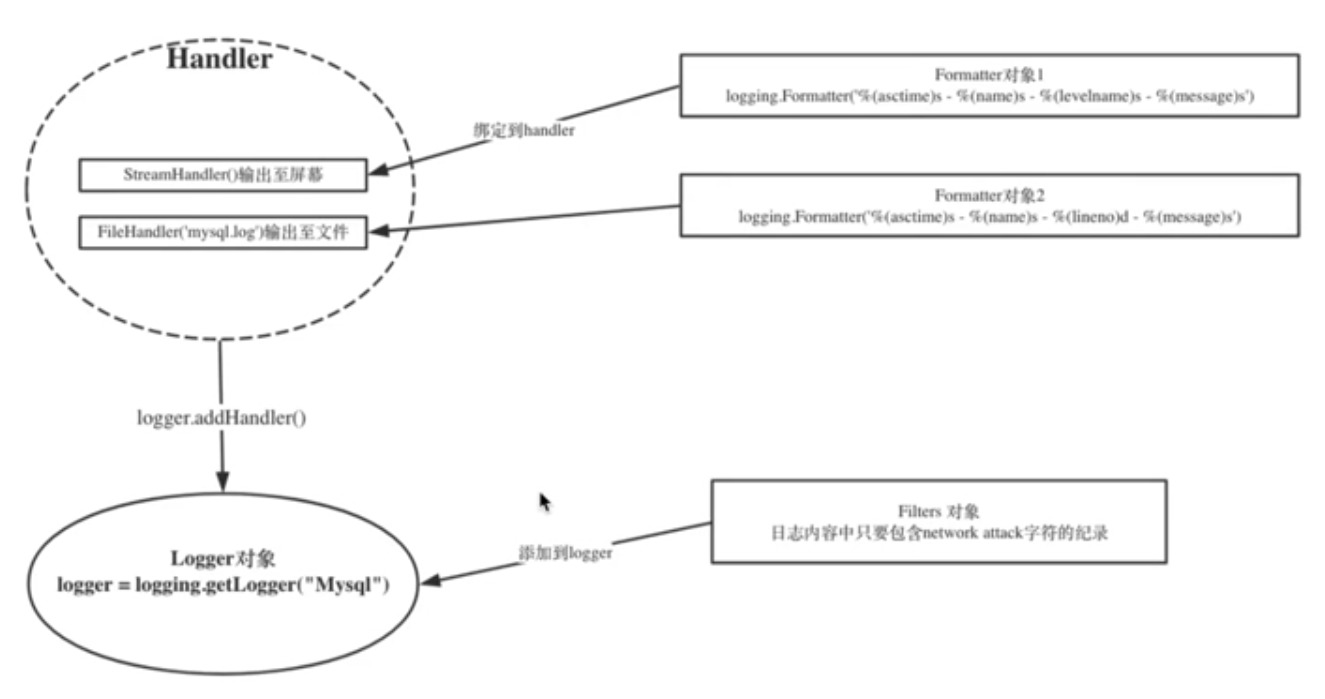
logging模块
日志同时输出到屏幕和文件:
python使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口;
handler将(logger创建的)日志记录发送到合适的目的输出;
filter提供了细度设备来决定输出哪条日志记录;
fromatter决定日志记录的最终输出格式