
学习心得:
这章对编码的讲解超级赞,现在对于编码终于有一点认知了,但还没有大彻大悟,还需要更加细心的琢磨一下Alex博客和视频,以前真的是被编码折磨死了,因为编码的问题而浪费的时间很多很多,现在终于感觉看到了一点光明,哈哈!
笔记:
print(bin(343)) #0b101010111 返回整数的二进制表示
python2默认支持的编码是ASCII
python3默认支持的编码是UTF8
科学计数法:
print(1.2395e8) #123950000.0 e8代表10的8次方,这个e换成大E也是OK的
浮点数:
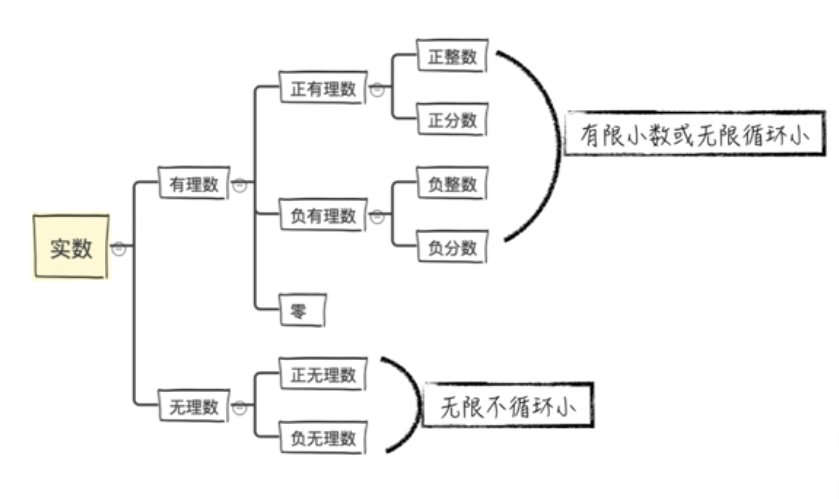
浮点精确度问题:
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的而浮点数运算则可能会有四舍五入的误差。
python默认的17位精度,也就是小数点后16位,尽管有16位,但是这个精确度却是越往后越不准的。
如果想要使用更精确的浮点数就可引入decimal模块的“getcontext”和“decimal”方法。
列表操作:
li=['python','PHP',888,'java','abc',888,'python','alex'] li.insert(1,666) print(li) #['python', 666, 'PHP', 888, 'java', 'abc', 888, 'python', 'alex'] num=li.index("PHP") print(num) #2 num=li.count("python") print(num) #2 n=li[-4:-1] #切片括号里面的数字从小到大 print(n) #['abc', 888, 'python'] li.remove(888) #如果有重复,删除的是从左面数的第一个,括号内必须要有参数,pop可以没有参数 print(li) #['python', 'PHP', 'java', 'abc', 888, 'python', 'alex'] n=li.pop() #不加索引,删除的是最后一个,并将删除的元素返回 n2=li.pop(0) #删除指定索引元素 print(n) #alex print(n2) #python print(li) #['PHP', 'java', 'abc', 888, 'python']
#sort()方法是对列表本身做排序,里面可以加一个reverse参数
li.clear() #清空列表
print(li) #[]
range() 方法得到的也是一个列表。
列表中的每一个元素都对应着一个内存地址,用id()方法看内存地址。
列表-练习题


1.创建一个空列表,命名为names,往里面添加old_driver,rain,jack,shanshan,peiqi,black_girl 元素 2.往names列表里black_girl前面插入一个alex 3.把shanshan的名字改成中文,姗姗 4.往names列表里rain的后面插入一个子列表,[oldboy, oldgirl] 5.返回peiqi的索引值 6.创建新列表[1,2,3,4,2,5,6,2],合并入names列表 7.取出names列表中索引4-7的元素 8.取出names列表中索引2-10的元素,步长为2 9.取出names列表中最后3个元素 10.循环names列表,打印每个元素的索引值,和元素 11.循环names列表,打印每个元素的索引值,和元素,当索引值 为偶数时,把对应的元素改成-1 12.names里有3个2,请返回第2个2的索引值。不要人肉数,要动态找(提示,找到第一个2的位置,在此基础上再找第2个) 13.现有商品列表如下: products = [ ['Iphone8',6888],['MacPro',14800], ['小米6',2499],['Coffee',31],['Book',80],['Nike Shoes',799] ] 需打印出这样的格式: ---------商品列表---------- 0. Iphone8 6888 1. MacPro 14800 2. 小米6 2499 3. Coffee 31 4. Book 80 5. Nike Shoes 799 14. 写一个循环,不断的问用户想买什么,用户选择一个商品编号,就把对应的商品添加到购物车里, 最终用户输入q退出时,打印购物车里的商品列表
解题:
字符串操作:
s="my name is alex" s1=s.capitalize() #首字母大写 print(s1) #My name is alex s2=s.title() #标题就是所有字母第一个字符都大写 print(s2) #My Name Is Alex s3=s.rjust(50) #50为包括字符串在内的总长度,不加填充符默认填充空格 print(s3) #" my name is alex" s3=s.rjust(50,"*") print(s3) #***********************************my name is alex s4=s.ljust(50,"-") print(s4) #my name is alex----------------------------------- s5=s.center(50) #默认填充的也是空格,长度也中包含字符串的总长度 print(s5) #" my name is alex " print(len(s5)) print(s.isidentifier()) #False,判断是不是一个合法的变量名 s.split() #按空格或其它字符将字符串分开,并以列表的形式返回 s.splitlines() #按行将字符串分开,并以列表的形式返回 #总结:字符串不像列表,列表的方法是直接对列表本身操作,而字符串的方法不对本身操作,使用后自身不变,需要将结果赋给一个变量
字符串格式化的另一种操作:
s3="my name is {0},i am {1} years old" s3.format("alex",22) s3="my name is {name},i am {age} years old" s3.format(name="alex",age=22)
哈希函数:hash()
可哈希的一定是不可变数据类型,可变数据类型不可哈希。
不可变数据类型:数字、字符串、元组
可变数据类型:列表、字典
思考:之所以字符串使用方法后自身不变,就是因为字符串是不可变类型,列表使用方法后自身改变,也是同样的道理。
字典:
key-value结构
key必须可哈希,且必须为不可变数据类型,必须唯一
可存放任意多个值、可修改、可以不唯一
无序
查找速度快
dic= {"name":"alex","age":18,"sex":"male","hobby":"baskeball"}
#获取值有两种方式,get在键不存在的时候返回None,而后一种会报错,为了减少报错,用get
print(dic.get("name")) #alex
print(dic.get("add")) #None
print(dic["name"]) #alex
print(dic["add"]) #报错,KeyError: 'add'
#判断键是否在字典中
print("name" in dic) #True
dic.pop("name") #括号里面必须要有参数
print(dic)
dic.popitem() #随机删除一个
print(dic)
a=dic.keys() #获取字典的键
print(a) #dict_keys(['age', 'name', 'hobby', 'sex'])
# print(a[0]) #TypeError: 'dict_keys' object does not support indexing,这个值不是一个列表,不能被查询
b=dic.values()
print(b) #dict_values(['male', 'baskeball', 18, 'alex'])
c=dic.items()
print(c) #dict_items([('hobby', 'baskeball'), ('sex', 'male'), ('age', 18), ('name', 'alex')])
dic.setdefault("age","30") #增键值对,如果存在,则不更新,不存在,则更新
print(dic) #{'age': 18, 'hobby': 'baskeball', 'sex': 'male', 'name': 'alex'}
dic.setdefault("add","beijing")
print(dic) #{'add': 'beijing', 'age': 18, 'hobby': 'baskeball', 'sex': 'male', 'name': 'alex'}
print(dic.fromkeys(["a","b","c"])) #{'a': None, 'b': None, 'c': None},创建一个新的字典,而不是更改之前的字典
print(dic) #{'age': 18, 'hobby': 'baskeball', 'add': 'beijing', 'sex': 'male', 'name': 'alex'}
dic2={"add":"beijing","department":"IT","age":30}
dic.update(dic2) #合并两个字典,如果存在相同的,则更新
print(dic) #{'hobby': 'baskeball', 'department': 'IT', 'age': 30, 'sex': 'male', 'name': 'alex', 'add': 'beijing'}
集合:
集合是一个无序的、不重复的数据组合,它的主要作用如下:
(1)去重,把一个列表变成集合就自动去重了
(2)关系测试,测试两组数据之前的交集、差集、并集等关系
集合操作:
s={} #如果是空的,就是字典,如果里面有值且是非键值对的形式,就是集合
s1={1,2} #创建集合
name={"alex","wupeiqi","龙婷","姗姗"}
name.pop() #随机删除一个元素,括号内不能加参数
print(name) #{'龙婷', '姗姗', 'alex'}
# name.remove("alex")
# print(name)
# name.remove("alex") #KeyError: 'alex'
# name.discard("alex")
#小结:remove和discard都是删除一个元素,区别是remove中的参数如果不存在会报错,而discard不会
set2={233,"python"}
name.update(set2) #将两个集体合并
print(name) #{'wupeiqi', 233, 'alex', '姗姗', 'python'}
name.update('ops') #将括号中的对象当成一个序列,将序列中的每个元素分别添加到集合
name.update([12,'eee']) #update添加多少元素
set2.add(888)
print(set2) #{888, 'python', 233}
set1={[111],"alex"} #TypeError: unhashable type: 'list'
集合小特性:
集合的元素必须是一个可哈希的值,所以列表、字典、集合(可变集合)都不能做为集合的元素。因为这个特性,所以集合中的元素可以做为字典的键。
set1={[111],"alex"} #TypeError: unhashable type: 'list'
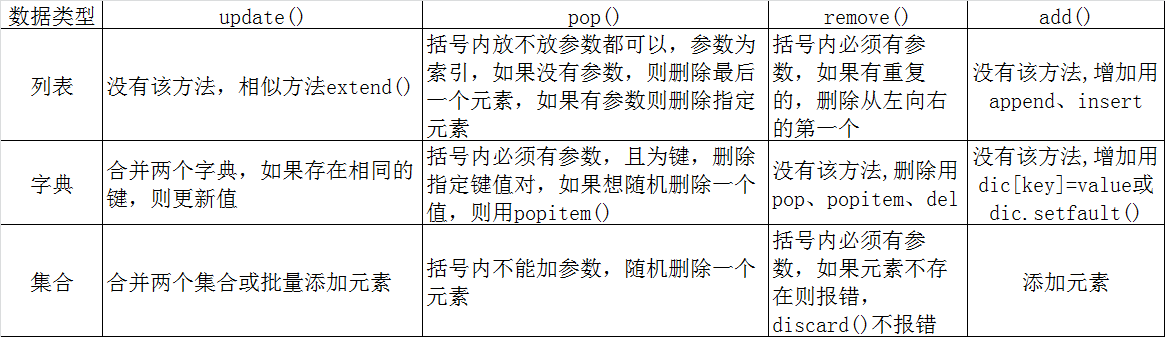
相似方法总结:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号