

MySQL数据文件类型:
数据文件、索引文件
重做日志、撤消日志、二进制日志、错误日志、查询日志、慢查询日志、(中继日志)
DDL & DML:
索引管理:
按特定数据结构存储的数据;
索引类型:
聚集索引、非聚集索引:数据是否与索引存储在一起;
主键索引、辅助索引
稠密索引、稀疏索引:是否索引了每一个数据项;
B+ TREE、HASH、 R TREE
简单索引、组合索引
左前缀索引
覆盖索引
管理索引的途径:
创建索引:创建表时指定;CREATE INDEX
创建或删除索引:修改表的命令
删除索引:DROP INDEX
注:创建或删除索引有两种方式,一种是在创建或修改表时指定,另外一种是单独使用CREATE/DROP INDEX命令。索引没必要修改,因为修改和创建没有区别,都要重建索引。
查看表上索引:
SHOW {INDEX | INDEXES | KEYS}
{FROM | IN} tbl_name
[{FROM | IN} db_name]
[WHERE expr]
视图:VIEW
视图中的数据事实上存储于“基表”中,因此,其修改操作也会针对基表实现;其修改操作受基表限制;
DML:
INSERT,DELETE,UPDATE,SELECT
INSERT:
一次插入一行或多行数据;
INSERT tb1_name [(col1,...)] VALUES (val1,...),(val2,...)
DELETE:
注意:一定要有限制条件,否则将清空表中的所有数据;
限制条件:
WHERE
LIMIT
UPDATE:
SELECT:
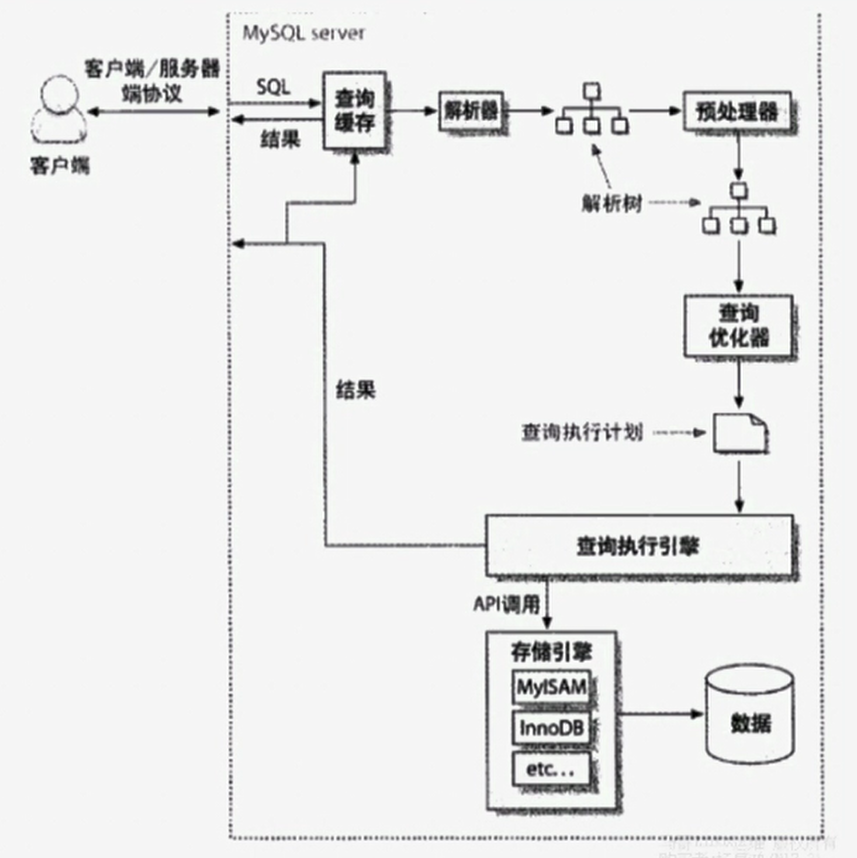
查询执行路径中的组件:查询缓存、解析器、预处理器、优化器、查询执行引擎、存储引擎
SELECT语句的执行流程:
FROM Clause --> WHERE Clause --> GROUP BY --> HAVING Clause --> ORDER BY --> SELECT --> LIMIT
单表查询:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[SQL_CACHE | SQL_NO_CACHE]
select_expr [, select_expr ...]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
DISTINCT:数据去重;
SQL_CACHE:显示指定存储查询结果于缓存之中;
SQL_NO_CACHE:显示查询结果不予缓存;
query_cache_type的值为‘ON’时,查询缓存功能打开;
SELECT的结果符合缓存条件即会缓存,否则,不予缓存;
显式指定SQL_NO_CACHE,不予缓存;
query_cache_type人值为‘DEMAND'时,查询缓存功能按需进行;
显示指定SQL_CACHE的SELECT语句才会缓存;其它均不予缓存;
字段显示可以使用别名:
col1 AS alias1,col2 AS alias2,...
WHERE子句:指明过滤条件以实现“选择”的功能:
过滤条件:布尔型表达式;
算术操作符:+,-,*,/,%
比较操作符:=,!=,<>,<=>,>,>=,<,<=
BETWEEN min_num AND max_num
IN (elemnet1,element2,...)
IS NULL
IS NOT NULL
LIKE:
%:任意长度的任意字符;
_:任意单个字符;
RLIKE:
REGEXP:匹配字符串可用正则表达式书写模式;
逻辑操作符:
NOT
AND
OR
GROUP:根据指定的条件把查询结果进行“分组”以用于做“聚合”运算;
avg(),max(),min(),count(),sum()
HAVING:对分组聚合运算后的结果指定过滤条件;
ORDER BY:根据指定的字段对查询结果进行排序;
升序:ASC
降序:DESC
LIMIT[[offset,]row_count]:对查询的结果进行输出行数数量限制;
对查询结果中的数据请求施加“锁”:
FOR UPDATE:写锁,排他锁;
LOCK IN SHARE MODE:读锁,共享锁
练习:导入ehllodb.sql生成数据库
(1) 在students表中,查询年龄大于25岁,且为男性的同学的名字和年龄;
(2) 以ClassID为分组依据,显示每组的平均年龄;
(3) 显示第2题中平均年龄大于30的分组及平均年龄;
(4) 显示以L开头的名字的同学的信息;
(5) 显示TeacherID非空的同学的相关信息;
(6) 以年龄排序后,显示年龄最大的前10位同学的信息;
(7) 查询年龄大于等于20岁,小于等于25岁的同学的信息;用三种方法;
多表查询:
交叉连接:笛卡尔乘积;
内连接:
等值连接:让表之间的字段以“等值”建立连接关系;
不等值连接
自然连接
自连接
外连接:
左外连接:
FROM tb1 LEFT JOIN tb2 ON tb1.col=tb2.col
右外连接
FROM tb1 RIGHT JOIN tb2 ON tb1.col=tb2.col
子查询:在查询语句嵌套着查询语句
基于某语句的查询结果再次进行的查询
用在WHERE子句中的子查询:
(1) 用于比较表达式中的子查询:子查询仅能返回单个值;
SELECT Name,Age FROM students WHERE Age>(SELECT avg(Age) FROM students);
(2) 用于IN中的子查询:子查询应该单键查询并返回一个或多个值从构列表;
SELECT Name,Age FROM students WHERE Age IN (SELECT Age FROM teachers);
(3) 用于EXISTS;
用于FROM子句中的子查询:
联合查询:UNION
SELECT Name,Age FROM students UNION SELECT Name,Age FROM teachers;

