Swin-Transformer 源码学习与使用手册
拜读了VIT以及TNT以及Swin-Transformer 的论文,结合B站up主的分析,
预感Swin-Transformer具有ResNet似的跨里程碑式的意义,
因此学习Swin-Transformer源码及其使用,记录如下。
1 Run
Swin-T
python -m torch.distributed.launch --nproc_per_node 2 --master_port 12345 main.py --cfg configs/swin/swin_tiny_patch4_window7_224.yaml --data-path data --batch-size 128
Swin-S
python -m torch.distributed.launch --nproc_per_node 2 --master_port 12345 main.py --cfg configs/swin/swin_small_patch4_window7_224.yaml --data-path data --batch-size 128
Swin-B
python -m torch.distributed.launch --nproc_per_node 2 --master_port 12345 main.py --cfg configs/swin/swin_base_patch4_window7_224.yaml --data-path data --batch-size 64 --accumulation-steps 2
上述命令中,
--nproc_per_node 为指定gpu数量,
--master_port 为指定端口号
--cfg 为指定配置yaml文件,该文件中参数较为重要,如下图所示

--data_path 为数据集路径,需要将数据集命名为 train 和 val
--batch_size 为批次大小
2 config.py
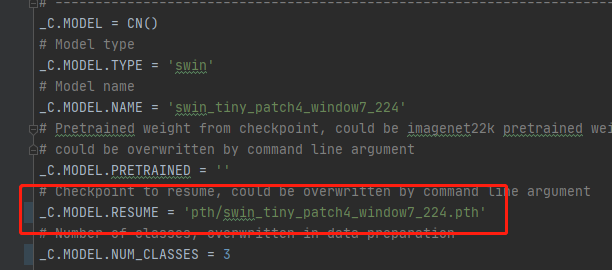
_C.MODEL.RESUME 该参数比较重要,为预训练模型的路径
预训练模型的获取在github主页,https://github.com/microsoft/Swin-Transformer,如下图所示

_C.MODEL.NUM_CLASSES 为分类类别数
_C.MODEL.TYPE = 'swin' 模型type,这里有swin 和 swin2
3 Model
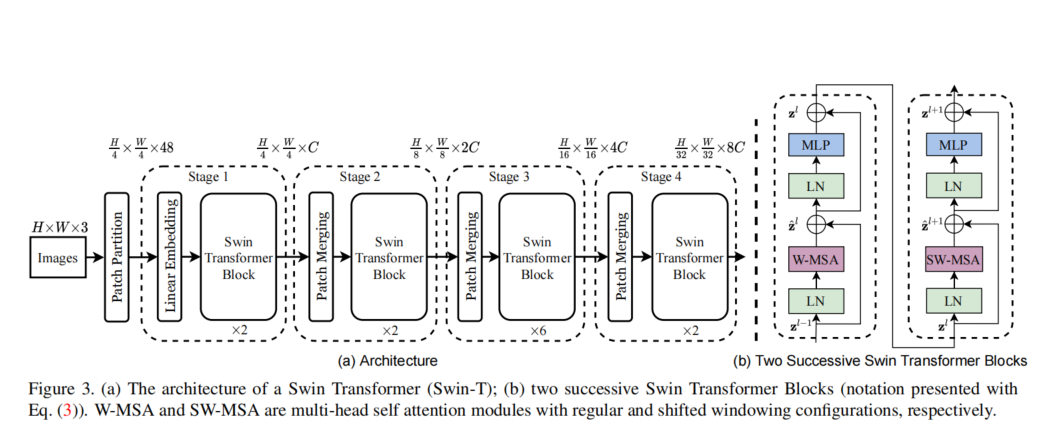
上图为Swin Transformer的网络结构图,可知,沿用了VIT的Patch思想,对图像进行分割裁剪为Patch,注意是采用卷积实现的Patch,源码实现如下图所示。

同时,Swin Transformer有两种,W-MSA和SW-MSA 与W-MSA相比,SW-MSA中的S为Shifted,为滑动窗口Shifted Window
4 迁移学习及改进策略
4.1 迁移学习
基于Transformer的模型依赖大数据集,但是实际应用中很难采集到大数据,因此,应用迁移学习解决这一问题,在Swin中,微软公司开源再imageNet上预训练的权重,
通过修改源码来完成基于预训练权重的迁移学习,整体过程如下:
(1)在config.py中修改预训练权重
(2)在utils中查看load_checkpoing方法,该方法为加载预训练权重,添加以下代码,该代码实际上是重新搭建了最后的分类层,
首先判断分类层shape与分类数是否相等,如果不等,直接new一个空的分类层,输入向量的长度为768
if checkpoint['model']['head.weight'].shape[0] != config.MODEL.NUM_CLASSES:
checkpoint['model']['head.weight'] = torch.nn.Parameter(
torch.nn.init.xavier_uniform(torch.empty(config.MODEL.NUM_CLASSES, 768)))
checkpoint['model']['head.bias'] = torch.nn.Parameter(torch.randn(config.MODEL.NUM_CLASSES))
(3)运行main.py即可开始训练迁移学习后的模型
4.2 池化策略改进-引入softpool
根据官方源码修改softpool
原始代码为:
def soft_pool1d(x, kernel_size=2, stride=None, force_inplace=False):
if x.is_cuda and not force_inplace:
x = CUDA_SOFTPOOL1d.apply(x, kernel_size, stride)
# Replace `NaN's if found
if torch.isnan(x).any():
return torch.nan_to_num(x)
return x
kernel_size = _single(kernel_size)
if stride is None:
stride = kernel_size
else:
stride = _single(stride)
# Get input sizes
_, c, d = x.size()
# Create exponential mask (should be similar to max-like pooling)
e_x = torch.sum(torch.exp(x),dim=1,keepdim=True)
e_x = torch.clamp(e_x , float(0), float('inf'))
# Apply mask to input and pool and calculate the exponential sum
# Tensor: [b x c x d] -> [b x c x d']
x = F.avg_pool1d(x.mul(e_x), kernel_size, stride=stride).mul_(sum(kernel_size)).div_(F.avg_pool1d(e_x, kernel_size, stride=stride).mul_(sum(kernel_size)))
return torch.clamp(x , float(0), float('inf'))
上述代码为原始softpool代码,但是Swin原始为自适应平均池化,输出降维到1,上述代码无法直接引入到Swin中,对代码进行修改如下:
class SoftPool1d(torch.nn.Module):
def __init__(self):
super(SoftPool1d, self).__init__()
self.kernel_size = 2
def forward(self, input_tensor):
_, c, d = input_tensor.size()
# Create exponential mask (should be similar to max-like pooling)
e_x = torch.sum(torch.exp(input_tensor), dim=1, keepdim=True)
e_x = torch.clamp(e_x, float(0), float('inf'))
# Apply mask to input and pool and calculate the exponential sum
# Tensor: [b x c x d] -> [b x c x d']
kernel_size = _single(self.kernel_size)
x = F.adaptive_avg_pool1d(input_tensor.mul(e_x), output_size=1).mul_(sum(kernel_size)).div_(
F.adaptive_avg_pool1d(e_x, output_size=1).mul_(sum(kernel_size)))
return torch.clamp(x, float(0), float('inf'))
同时对args命令行参数进行修改,引入pool,来区分pool_type,在构建池化层时进行判断
if pool_type == 'avgpool':
self.avgpool = nn.AdaptiveAvgPool1d(1)
elif pool_type == 'softpool':
self.softpool = SoftPool1d()
if self.pool_type == 'avgpool':
x = self.avgpool(x.transpose(1, 2)) # B C 1
print(x)
elif self.pool_type == 'softpool':
x = self.softpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
4.3 swin改进实验记录
| 序号 | swin预训练权重 | 是否固定 | convnext预训练权重 | 是否固定 | swin pool_type | 特征融合 | acc1_val | acc1_test | save_path |
| 4.3.1 | imageNet22k | √ | imageNet | √ | avg_pool | cat | 91.7 | 87.667 | swinConNext_swin_frozen |
| 4.3.2 | imageNet22k | × | imageNet | √ | avg_pool | cat+softmax | 93.85 | 89.000 | swinConNext_swin_softmax |
| 4.3.3 | imageNet22k | √ | imageNet | √ | avg_pool | cat+softmax | 91.1538 | swinConNext_swin_frozen_softmax | |
4.3.1
python -m torch.distributed.launch --nproc_per_node 1 --master_port 12345 main.py --cfg configs/swin/swin_tiny_patch4_window7_224.yaml --data-path data --batch-size 256 --output swinConNext_swin_frozen --resume pth/swin_tiny_patch4_window7_224_22k.pth --swin_frozen True
说明:convnext使用预训练权重,固定权重,作为特征提取器,将输出的向量拉平进行cat操作,对swin2使用imageNet22k预训练权重,不固定权重。
class ConvNext(nn.Module):
def __init__(self):
super(ConvNext, self).__init__()
self.convnext = self.get_model()
def forward(self, x):
x = self.convnext(x)
return x
def get_model(self):
model = convnext_base(pretrained=True)
layer_name = 'avgpool'
previous_model = nn.Sequential()
for name, module in model.named_children():
if name == layer_name:
previous_model.add_module(name, module)
break
previous_model.add_module(name, module)
for param in previous_model.parameters():
param.requires_grad = False
return previous_model
class SwinConvNext(nn.Module):
def __init__(self, swin, swin_frozen=False, softmax_weights=False):
super(SwinConvNext, self).__init__()
self.swin = self.get_swin(swin, swin_frozen)
self.convnext = ConvNext()
self.fc = nn.Linear(1792, 3)
self.softmax_weights = softmax_weights
def forward(self, x):
swin_output = self.swin(x.clone())
convnext_output = self.convnext(x)
swin_output = torch.flatten(swin_output, 1)
convnext_output = torch.flatten(convnext_output, 1)
x = torch.cat((swin_output, convnext_output), dim=1)
if self.softmax_weights:
weights = torch.softmax(x, dim=1)
x = x * weights
x = self.fc(x)
return x
def get_swin(self, swin, swin_frozen):
if swin_frozen:
for param in swin.parameters():
param.requires_grad = False
return swin
评估代码
python -m torch.distributed.launch --nproc_per_node 1 main_simmim_ft.py --eval --cfg configs/swin/swin_tiny_patch4_window7_224.yaml --resume swinConNext_swin_frozen/swin_tiny_patch4_window7_224/default/ckpt_epoch_13.pth --data-path ../CUMT-BelT
4.3.2
python -m torch.distributed.launch --nproc_per_node 1 --master_port 12345 main.py --cfg configs/swin/swin_tiny_patch4_window7_224.yaml --data-path data --batch-size 128 --output swinConNext_swin_softmax --resume pth/swin_tiny_patch4_window7_224_22k.pth --softmax_weights True
评估代码
python -m torch.distributed.launch --nproc_per_node 1 main_simmim_ft.py --eval --cfg configs/swin/swin_tiny_patch4_window7_224.yaml --resume swinConNext_swin_softmax/swin_tiny_patch4_window7_224/default/ckpt_epoch_12.pth --data-path ../CUMT-BelT --softmax_weights True
4.3.3
nohup python -m torch.distributed.launch --nproc_per_node 1 --master_port 12345 main.py --cfg configs/swin/swin_tiny_patch4_window7_224.yaml --data-path data --batch-size 256 --output swinConNext_swin_frozen_softmax --resume pth/swin_tiny_patch4_window7_224_22k.pth --softmax_weights True --swin_frozen True > test.log &
评估代码
python -m torch.distributed.launch --nproc_per_node 1 main_simmim_ft.py --eval --cfg configs/swin/swin_tiny_patch4_window7_224.yaml --resume swinConNext_swin_frozen_softmax/swin_tiny_patch4_window7_224/default/ckpt_epoch_99.pth --data-path ../CUMT-BelT --softmax_weights True

 浙公网安备 33010602011771号
浙公网安备 33010602011771号