韧性评估研究
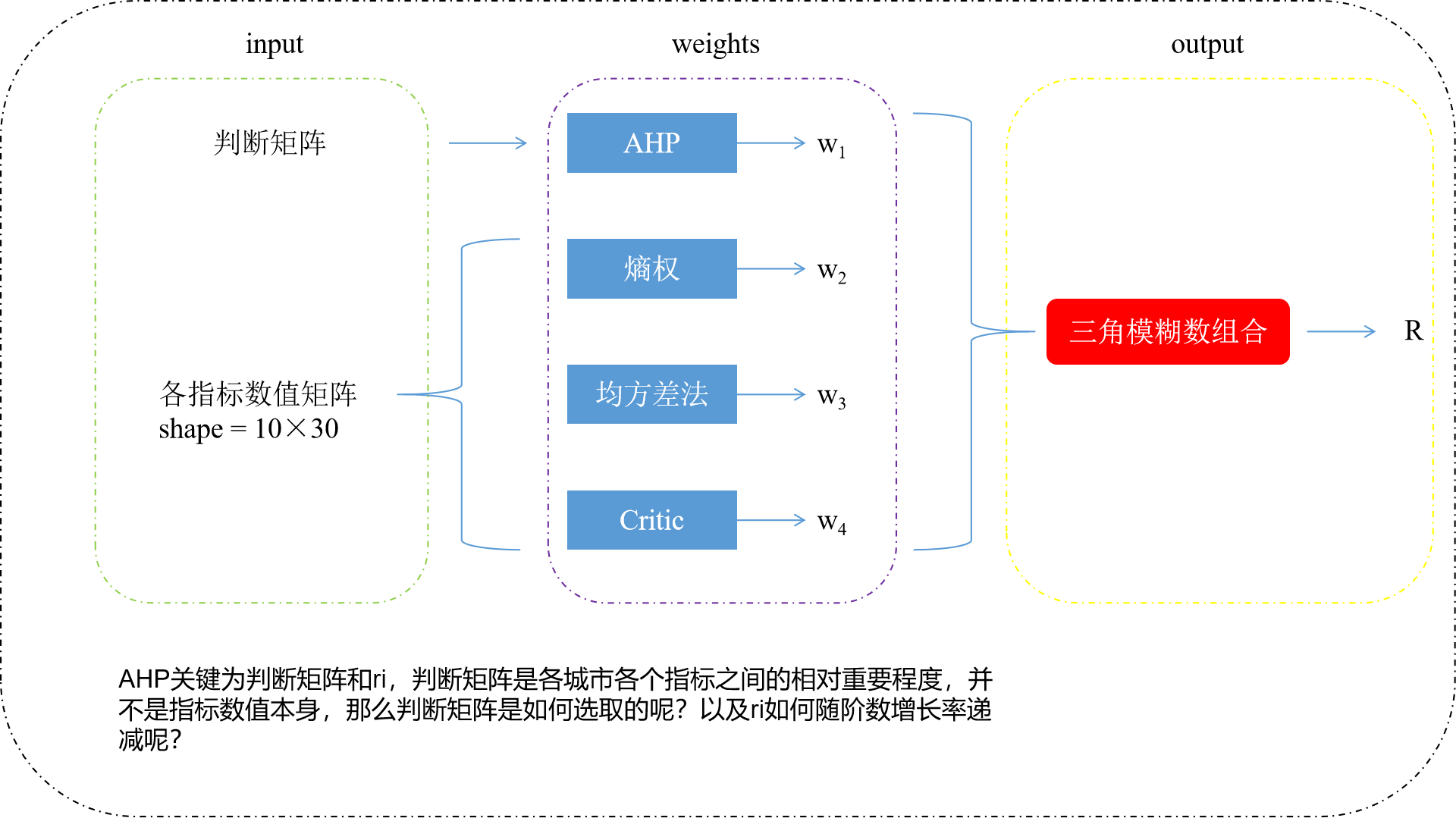
整体框架
AHP算法的实现
import numpy as np
import pandas as pd
# 定义 AHP 方法
def ahp(matrix):
# 计算比较矩阵的列向量和与归一化矩阵
col_sum = np.sum(matrix, axis=0)
norm_matrix = matrix / col_sum
# 计算加权平均向量和一致性比率
weight = np.mean(norm_matrix, axis=1)
lamda_max = np.max(np.linalg.eigvals(matrix))
ci = (lamda_max - matrix.shape[0]) / (matrix.shape[0] - 1)
ri = [0, 0, 0.58, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49, 1.51, 1.48, 1.56, 1.57, 1.59]
if matrix.shape[0] > 13:
ri += [1.59 + 0.01 * (matrix.shape[0] - 13)]
if matrix.shape[0] > 27:
ri += [ri[-1] + 0.01]
cr = ci / ri[matrix.shape[0]-1]
return weight, cr
# 示例数据
data = pd.DataFrame(np.random.rand(10, 28))
# 构建比较矩阵
pairwise_matrix = np.zeros((data.shape[1], data.shape[1]))
for i in range(data.shape[1]):
for j in range(data.shape[1]):
if i != j:
pairwise_matrix[i, j] = np.sum(data.iloc[:, i] > data.iloc[:, j])
pairwise_matrix[j, i] = np.sum(data.iloc[:, j] > data.iloc[:, i])
# 计算特征层的权重
feature_weight, cr = ahp(pairwise_matrix)
# 输出结果
print(f'Feature weights: {feature_weight}')
print(f'Consistent ratio: {cr}')
上述代码中,实现了关于AHP计算权重的方法,但是由于不知道比较矩阵如何给定的,我随机生成了一个28×28的矩阵,
同时ri取值在13阶之前依次为 [0, 0, 0.58, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.51, 1.48, 1.56, 1.57, 1.59],13阶之后 按照1.59+ 0.01*(当前阶数-13)递增。
之后我调研了AHP算法的发展和研究现状,目前主流的方法 AHP -》ANP -》DEMATEL -》DEMATEL-ANP ,是否可以应用DEMATEL-ANP? 但是这个比较矩阵是专家主观给定的,具有局限性,很迷幻
还有一个问题,假设一次性检验结果大于0.1,按照惯例,需要重新构建比较矩阵,感觉不具有实际应用性,这个比较矩阵是从哪获取的呢?
FCM替换三角模糊组合可以么?
得到四个w后,采用三角模糊组合对四个变量进行组合生成一个新的变量,这里可以应用FCM么,将聚类结果的隶属度求平均,作为新变量值?
FCM实现
import numpy as np
import pandas as pd
import skfuzzy as fuzz
df = pd.read_csv('weights.csv', sep=' ', header=None)
df = df.set_index(0)
# 将DataFrame转换为NumPy数组
data = df.to_numpy()
print(type(data))
print(data)
# 训练FCM模型
n_clusters = 2
max_iter = 100,
cntr, u, _, _, _, _, _ = fuzz.cluster.cmeans(data.T, n_clusters, 2, error=0.005, maxiter=max_iter, init=None)
# 计算每个样本的新变量值
new_feature = []
for i in range(len(data)):
weights = u[:, i]
new_value = np.zeros(n_clusters)
for j in range(n_clusters):
new_value[j] = np.dot(weights, cntr[:, j]) / np.sum(weights)
new_feature.append(np.mean(new_value))
# 将新变量值添加到DataFrame中
df['new_feature'] = new_feature
print(df)
# 输出结果
print(len(df))
我这里直接采用了论文中输出的4个w的权重表格,然后类簇选取为2,计算每个特征在每个类簇的隶属度,将其求平均,作为新的输出
然后我调研了一下,FCM有需要改进 如WFCM、PCM 可以应用,是否可以强行应用呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号