
西夏文检测实录
背景:最近一直在准备公务员考试和光伏发电数据分析,今天抽出空来做一下西夏文的识别工作。
首先大量了解西夏文识别的研究进展,主要是:
(1)以柳长青为团体的研究者,他们的识别只是单字的识别,就是通过对图像做特征处理,然后做欧式距离,实际上就是图到图的检索,在现有语料库(汉字-西夏文图像)基础上,对西夏文图像进行图到图的匹配,进而得到单字西夏文图片对应的汉字,但我觉得这种方法缺陷就是效率问题,一个单字西夏文图片去和语料库中做相似度计算??,显然效率很低,正如我的猜想,柳长青的论文中实验数据只有很少一部分西夏字,大概200多字,这种方法取均值的准确率达到了80以上,但是短板也很明显。
(2)西夏文處理系統 | 古今文字集成 (ccamc.co) 这个网站也是给出了翻译,视频中是输入西夏文来检索汉字,但是目前我还没有解决西夏文在浏览器和代码编辑器显示的问题,今天也是研究了ttf文件的内部结构,还没有解决西夏文在编辑器和浏览器运作的问题。
我的思路:
首先柳长青对单字图像做特征处理,然后计算该图像与语料库中单字图像的相似度,是可行的,实际上也可以做深度学习的图到图的匹配,所以目前可以采用将整个文本卷书,进行文本检测,提取出单字的图像区域,然后采用柳长青的思路走下去,通过单字的检索来完成整个文本卷书的识别。
图像去噪处理
通过实验,去噪对文本检测的影响较大,好的去噪决定了文本检测的精度,所以对比了经典方法的去噪方法,如下所示。
原始图像

均值滤波去噪 中值滤波去噪


高斯滤波去噪 非局部平均去噪


非局部平均去噪参数优化
templateWindowSize = 7 templateWindowSize = 3


小波变化去噪 二维一级分解

实际上,但从肉眼看,非局部平均去噪是效果最好的,实际上肯定的,NL-means把空间域和变换域的降噪方法结合起来,在对图像进行降噪处理,由于传统空间域和变换域的降噪方法,实际上传统方法中最优的是BM3D,但是目前我还没实现代码,所以没有去做这个。
实际上,深度学习在图像降噪也是早有研究,下一步就计划做深度学习的图像降噪,基于自编码器的图像降噪。
对于深度学习图像降噪需要大量数据集,通过自己生成中文数据集,然后加入噪声,来训练我们的自编码器降噪模型,然后通过迁移学习,应用到西夏文图像降噪处理。
基于CRAFT文本检测模型:
文本检测也是采用迁移学习,将预训练在中文数据集上表现不错的模型拿来,做西夏文检测
具体采用CRAFT,出自2019年的cvpr,目前的检测效果如下

又经过了一下午的实验,优化了检测模型,效果如下:

可以看到,效果已经非常好,完全满足了分割需求,我们通过检测输出的坐标对文本进行分割,

分割效果如上,可以看到202个西夏文没有出现一个错误,基本可以应用该方法
基于图匹配的西夏文识别
在前面的工作中,我们已经完成了西夏文的单字分割,实际上我们已经有了西夏文语料库,在语料库中我们的数据存储形式是,单字的西夏文图片对应中文汉字,所以说:
(1)我们已经完成了整页西夏文->单字西夏文的分割
(2)语料库中 存有 单字西夏文图片->汉字
(3)我们只需要做图到图的匹配,即可完成最后的西夏文识别,也就是将整页分割后的单字西夏文图片与语料库中的单字西夏文图片进行图匹配,找到相似度最大的即可完成识别。
(4)图匹配的算法可以借鉴柳长青的思路,或者采用深度学习方法,对比选择最好的,完成最后的识别工作。
基于图匹配,计算相似度效果不佳。测试了80个字,目测连50准确率都达不到,还是很难呀!!
基于深度学习(图像分类)的西夏文识别
计算相似度的方法效果不好,决定试试图像分类,将文字识别视为图像分类问题,进行单字的分类,不过我发现整个处理流程实际上是俩阶段的OCR算法,好low,目前比较新的方法都是端到端的。我们采用俩阶段的思路
1. 基于AutoAugment的数据增强 2022.01.06 19.58
这是一种常用的图像增强方法,可有效提高识别准确率且扩充数据集合。结果如下:
样例1

样例2

样例3

样例4

样例5

2. 基于densNet的西夏文字符识别 2022.02.17 23.15
尝试了很多图像分类算法,效果十分不好。
今天跑了 torch版本的densNet121网络,该网络是在一个比赛上用的分类网络,今天尝试在西夏文识别的问题上。
问题描述:200类别的分类问题。1.数据集中类别中样本数量分布不均。
实验1:所有数据集训练,样本不均
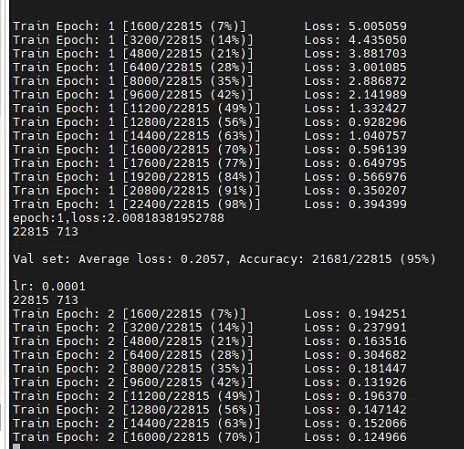
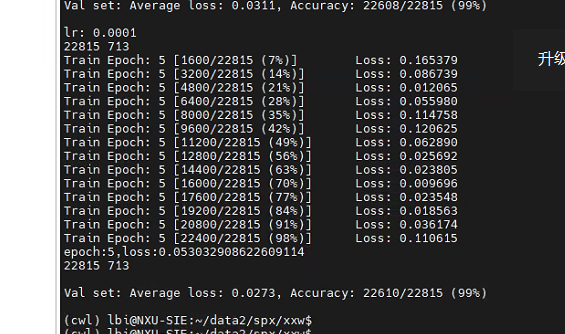
可达95准确率,训练样本22815,没有划分测试集合,该准确率为训练集(时)准确率
实验2:每个类别100样本,训练样本20000
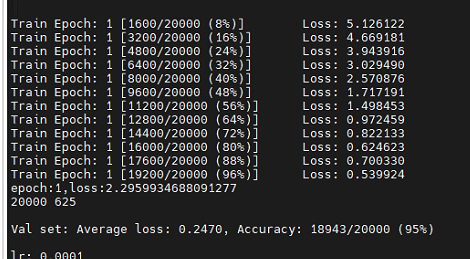
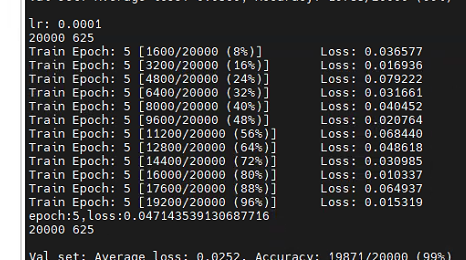
可达95准确率,训练样本20000,没有划分测试集合,该准确率为训练集(时)准确率
实验3:每个类别150样本,100原始+50增强
测试集采用剩下的原始50样本
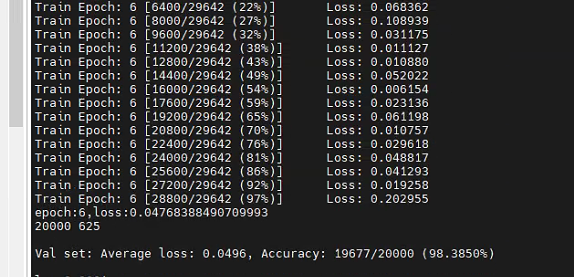
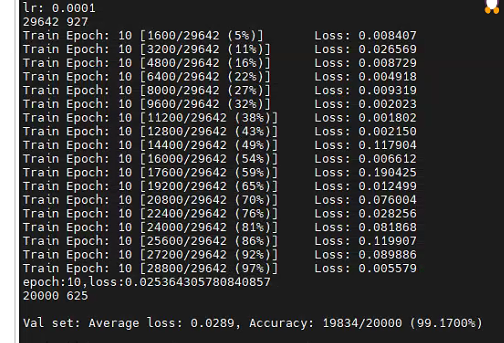
3. 不同网络模型的对比(每个类别150样本,100原始+50增强)
(1)densent201
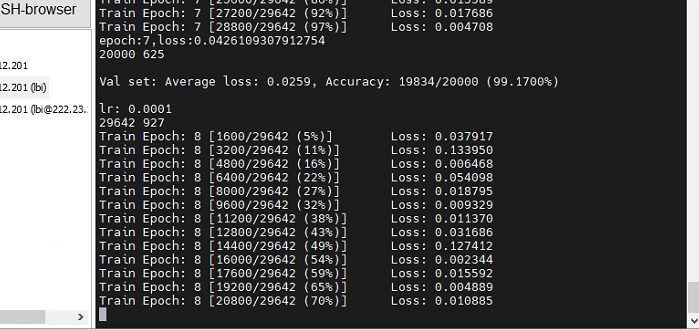
(2)efficientent_b5

