问卷与量表的区别,以及量表的信效度分析应该如何测量
最近在各个平台总能收到这样一个问题 “问卷如何进行信效度分析?”每次小编提到信效度分析时都会特意强调,只有量表才需要进行信度与效度分析,普通问卷(单选、多选、填空等)并不需要。那么今天就再深入探讨一下问卷与量表的区别,以及量表的信效度分析应该如何测量。
一、问卷与量表的区别
毕业论文开始设计问卷的时候,先区分什么是问卷,什么是量表;然后根据自己的研究目的、需要获取的信息形式、以往的研究文献等,去判断自己的研究更适合使用问卷还是量表去收集数据。问卷与量表的区别可以从以下4个方面进行比较:
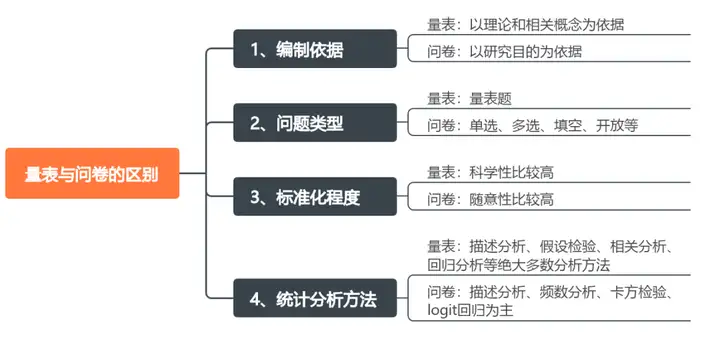
1、编制依据的区别
量表以理论和相关概念为依据,而问卷以研究目的为依据。
- 量表的编制需要以一定的理论和概念含义为基础,例如研究人性格的内向与外向,可以根据荣格的人格理论中有关内向和外向的特点来选择一些典型的行为然后编制。
- 而调查问卷则只以调查研究的目的为依据,例如调查社会特定群体的性别、年龄、月收入水平、对某事件的看法等,这些问题只围绕你的研究目的进行设计即可,不必要具有相关的理论依据。
2、问题类型的区别
量表都是“单选题”,问卷的题目类型很多种。
- 量表常用于衡量无法直接测量的指标,如焦虑、抑郁、幸福感等。例如最常用李克特量表——该量表由一组陈述组成,每一陈述有非常同意、同意、不一定、不同意、非常不同意五种回答,分别记为5、4、3、2、1,每个被调查者的态度总分就是他对各道题的回答所得分数的加总,这一总分可说明他的态度强弱或他在这一量表上的不同状态。
- 问卷的问题类型却是不同的,针对不同的题目可以设置不同数量的选项以及不同的问题类型。比如单选题、多选题、填空题、开放题、排序题等。
3、标准化程度的区别
量表的科学性比较高,问卷的“随意性”比较高。
- 量表的问题都围绕一个特定的概念或构造,量表的各个内容之间都与此主题相关,各个维度之间有着共同的含义和联系。一个成熟量表的编制过程很复杂,一般需要进行过试测、初测、预调查、正式调查,并且经过探索性因子分析(及验证性因子分析)、量表信效度检验后才形成的,科学性较高。
- 问卷题目则比较分散,想要调查了解什么,就设计什么题目,比如我们自行设计目标群体的一般资料问卷,只是为了收集基本信息。最终的问卷通常只是对前期编制时的问题进行一定的修改后直接形成的,中间不涉及信效度分析等,对于问卷的制作人来说比较“随心所欲”。
4、统计分析方法的区别
- 量表的答案会通过一套明确的计分系统转化为数字,方便进行统计分析和比较,所以可以进行的统计分析有很多种,比如描述分析、假设检验、相关分析、回归分析研究影响关系、中介效应、调节效应、聚类分析、因子分析、构建权重指标体系等等;SPSSAU中绝大多数统计分析方法都可以使用。
以量表类问卷中影响关系研究分析思路为例,常用的统计方法如下:

- 问卷的分析则以描述分析、频数分析、卡方检验为主,部分题目可以进行logistic回归分析。问卷分析一般框架如下:

二、问卷与量表的联系
问卷和量表并非完全独立,它们在某些情况下会一起使用。
例如,工作满意度的问卷中除了基本人口统计学变量外(性别、年龄、婚姻状况、教育程度、职业、收入等),还会包含一套工作满意度量表,以量化参与者的工作满意度。
这就说明了问卷和量表之间的关系,量表可以被视为问卷的一部分,但并非所有问卷都是量表。问卷是一个更广泛的概念,可以包含各种类型的问题,而量表则是一个更具体的工具,专门用于量化某个特定变量或特性。
而我们在文献中看到的信效度分析,只针对量表题进行。对于普通的问卷题目(性别、年龄、收入等)并不需要进行信效度分析。所以当一份问卷中既有基本题目又有量表题时,只对量表题进行信效度分析;只对量表题进行信效度分析;只对量表题进行信效度分析。
三、量表信效度分析
信度和效度都是衡量量表质量的重要指标,通常用于评估量表的可靠性和有效性。
1、信度分析
信度主要用于测量样本回答结果是否可靠、样本有没有真实作答量表类题项。SPSSAU提供的信度测量指标有克隆巴赫α信度系数、折半信度、McDonald's ω信度系数、theta信度系数、重测信度,下面分别进行说明。
(1)克隆巴赫α信度系数
Cronbach α系数是目前最常用的信度系数,该系数评价的是量表中各题项得分间的一致性,属于内在一致性系数。通过计算评估内部各项指标之间的相关性来衡量一致性。它基于各项指标的方差和协方差,给出一个在0到1之间的值,数值越大表示内在信度越高。
信度系数评价标准:
- α≥0.8,信度高;
- 0.7≤α<0.8,信度可以接受;
- 0.6≤α<0.7,信度一般,但仍不失其价值;
- α<0.6,信度低,需要重新设计量表。
(2)折半信度
折半信度是指将全部题项按奇项、偶项或者其他标准分为尽可能相等的两半,计算两组题项之间的相关系数,然后通过公式计算得到折半信度系数值。折半信度需要进行斯皮尔曼—布朗(Spearman-Brown)公式校正,求出整个量表的信度系数rrt。
(3)McDonald's ω信度系数
McDonald's ω信度系数的计算原理是利用因子分析浓缩信息,然后得到loading载荷系数值,进而计算。他考虑了各项指标的载荷以及测量误差的方差,与Cronbach α系数相比,McDonald's ω系数可以更准确地估计总体的可靠性,提供了一种更严格的内在信度估计方法。
(4)theta信度系数
thete内在一致性信度的一种测量方式,其原理是利用‘信息浓缩’(内部原理为因子分析且提取为1个因子),各个测量项隶属于同一维度且数据真实,那么它们应该浓缩出较高的信息,结合因子分析输出的载荷系数loading值等进一步计算,最终得到指标值。
(5)重测信度
重测信度,又称再测信度、稳定性系数,应用同一测验方法,对同一组被试者先后两次进行测查,然后计算两次测查所得分数的关系系数。该信度能表示两次测试结果有无变动,反映了测验分数的稳定程度。
2、效度分析
效度用于反映实际测量结果与预想结果的符合程度,由于无法确定目标的真实值,因此效度的评价比较复杂,常常需要与外部标准作比较才能判断。一般来讲,有4种类型的效度:内容效度、结构效度、区分效度、聚合效度。接下来,分别进行介绍。
(1)内容效度
内容效度分析是指问卷题对相关概念测量的适用性情况,即题项设计的是否合理。内容效度通常使用文字叙述形式对问卷的合理性、科学性进行说明。主要描述问卷中测量量表题有着严谨的参考依据,问卷设计是否得到专家的认可、是否对问卷进行修正等。
(2)结构效度
结构效度用于测量结果的数据结构与问卷设计是否相符。即研究所测量因子与题项之间的对应关系是否符合预期假设。测量结果的各内在成分是否与设计者打算测量的领域一致。通常使用探索性因子分析(EFA)进行验证,如果输出结果显示题项与变量对应关系基本与预期一致,则说明结构效度良好。
结构效度分析完整分析过程可查看SPSSAU帮助手册说明:效度分析
(3)区分效度
区分效度(又称判别效度、区别效度),其实质也是一种结构效度。区分效度强调本不应该在同一因子的测量项,确实不在同一因子下面。比如说,测量项A1和B1分别测量两个属性,应该分属于因子A和因子B中,如果确实是这样,那么说明区分效度很高;但是如果二者属于同一因子下,则说明区分效度不明显,量表设计的不好。
(4)聚合效度
聚合效度(又称收敛效度),是指测量同一变量的测量项会落在同一因子上,强调本应该在同一因子下的测量项,确实在同一因子下。即一个变量的测量题项之间要高度相关。从题项角度讲,聚合效度是维度内所有题项相关性要高。进行聚合效度分析的主要目的在于检验同一变量的各指标之间的相关程度。
区分效度与聚合效度都使用验证性因子分析进行研究

 浙公网安备 33010602011771号
浙公网安备 33010602011771号