三种数据类型的区分
面板数据、截面数据、时间序列数据对比说明如下:
一、截面数据
(1)概念
截面数据是指由同一时间、不同个体的一个或多个指标所组成的数据。截面数据强调同一时间的数据,常见的人口普查数据、工业普查数据都是截面数据。
例如:2022年,各省份人口数构成的一组数据为截面数据。
(2)适用范围
不同个体在同一时间下由于个体不同而产生的数据。绝大多数统计分析方法都可以分析截面数据,可根据分析目的和截面数据类型进行分析方法的选择。比如定量数据可以进行描述性分析;如果有多个指标可以进行聚类分析、因子分析、主成分分析、回归分析等。不同类别之间的数据还可以进行方差分析、t检验、卡方检验等差异性分析。
二、时间序列数据
(1)概念
时间序列数据是指不同时间、同一个体的一个或多个指标组成的数据。时间序列数据强调不同时间,并且数据严格按照时间顺序排序,如:年、月、日、小时等等。
例如:2013年-2021年北京市人口数。

(2)适用范围
同一个体随时间变化产生的数据。时间序列数据存在先后顺序,一般用来研究事物的发展变化规律,在经济学中非常常见。时间序列数据有专门的时间序列预测模型,比如ARIMA模型、指数平滑法预测等。还可以用来查看总体变化趋势、周期性、季节性变化趋势等。
三、面板数据
(1)概念
面板数据是不同时间、不同个体的一个或多个指标组成的数据,具有个体和时间两个维度,是二维数据。面板数据可以理解为在截面上的个体在不同时间的重复观测数据。
例如:2013-2021年各省份人口数

(2)适用范围
不同个体随时间变化产生的数据,是截面数据和时间序列数据的综合,可以进行面板模型分析。
(3)面板模型分析
使用SPSSAU系统进行面板模型分析,操作如下:
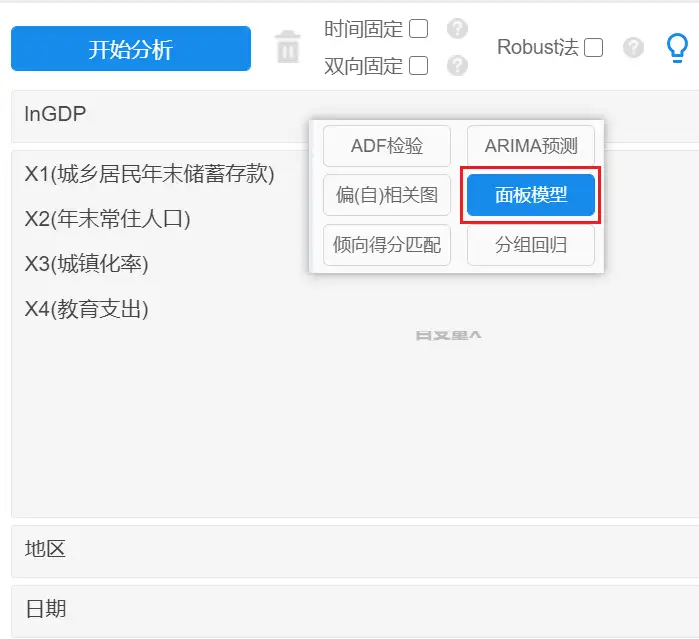
面板模型可继续分为三种类型,分别是固定效应模型(FE),混合估计模型(POOL)和随机效应模型(RE)。最终应该选择哪个模型,可通过各个检验进行判断。SPSSAU分别进行F检验,BP检验和Hausman检验(豪斯曼检验),以判断出最终应该使用哪个模型。
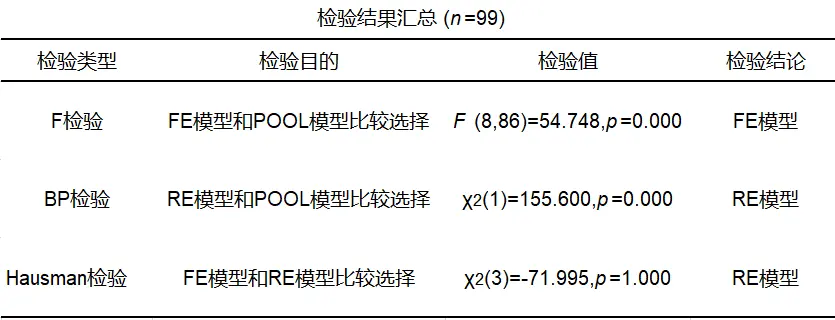
从上表分析,SPSSAU建议最终以RE模型作为最终结果。
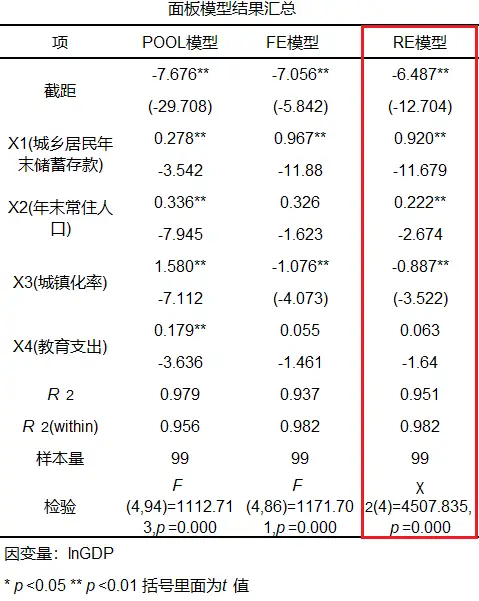
本研究以RE模型作为最终结果,从上表可知:针对X1(城乡居民年末储蓄存款)而言,其呈现出0.01水平的显著性(-11679.p=0.0.0<0.01),并且回归系数值为0.920>0,说明×1(城乡居民年末储蓄存款)对nGDP会产生显著的正向影响关系。针对X2(年末常住人口)而言,其呈现出0.01水平的显著性(=2.674,p=0.0094001),并且回归系数值为0.222>0,说明X2(年未常住人口)对nGDP会产生显著的正向影响关系。针对×3(城镇化率)而言,其呈现出0.10水平的显著性(-3.51.p=0.001<0.01),并且回归系数值为-0.887<O,说明X3(城镇化率)对nGDP会产生显著的负向影响关系。针对X4(教育支出)而言,其并没有呈现出显著性(=1.840,p=0.104>0.05),因而说明X4(教育支出)对InGDP不会产生影响关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号