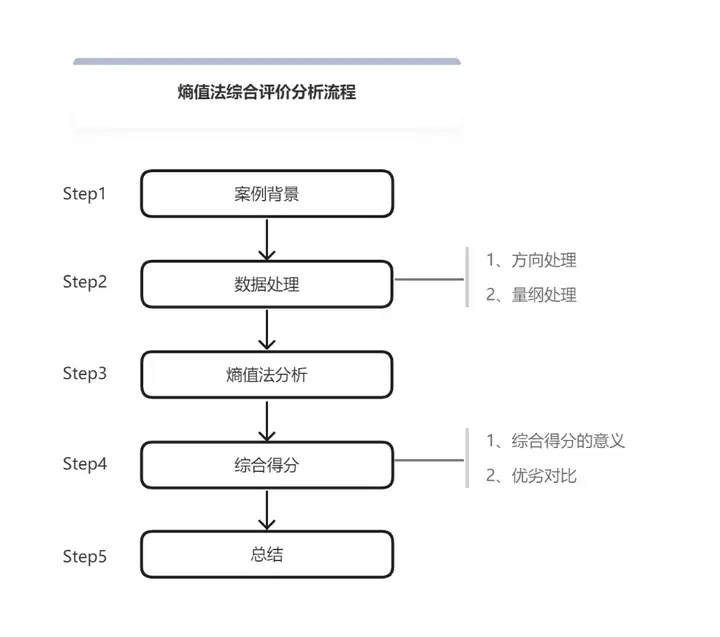
熵值法综合评价分析流程
熵值法综合评价分析流程
一、案例背景
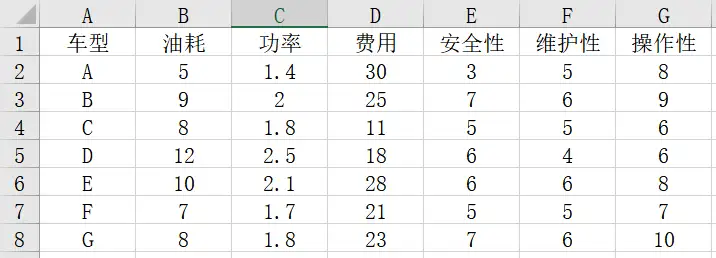
当前有一份数据,是各品牌车各个维度的得分情况,现在想要使用熵值法进行综合评价,得到各品牌车的综合得分,从而进行车型优劣对比,为消费者提供购车依据。
数据如下(数据虚构,无实际意义):
二、数据处理
使用熵值法进行分析,需要对数据进行处理,包括数据方向处理和数据量纲处理。
(1)方向处理
当数据方向不一致时,需要进行方向处理,消除数据方向不同的影响。数据按照方向不同,可分为正向指标和负向指标,正向指标是指数据越大越好的指标,比如GDP;负向指标是指数据越小越好的指标,比如空气污染指数。进行方向处理就是将正向指标进行正向化处理、负向指标进行逆向化处理,这样处理后,数据方向就完全一致了。
案例中车辆的油耗、费用,对于消费者来讲,一般希望越小越好,故这2个指标为负向指标,需要进行逆向化处理;而车辆的功率、安全性、维护性、操作性,一般都希望越大越好,这4个指标为正向指标,需要进行正向化处理。
SPSSAU中可以使用生成变量->正向化/逆向化处理功能,操作如下:
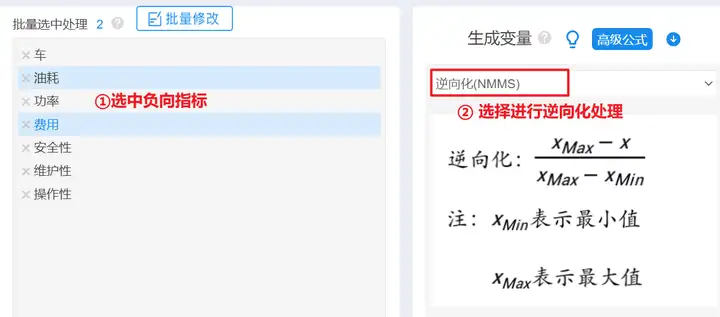
上图展示了负向指标逆向化处理操作,正向指标正向化处理操作同上。
(2)量纲处理
消除数据方向的影响后,还需要消除由于数据单位不同造成的影响,即进行量纲处理,SPSSAU提供十几种量纲处理方法,这里推荐使用数据归一化进行处理。
本案例因为上述分析中已经进行了正向/逆向此两种处理,而正向/逆向化处理可同时解决方向和量纲问题,所以不需要再次进行归一化处理。数据处理完成之后,接下来进行熵值法分析。
三、熵值法分析
熵值法是客观赋权法当中的一种,熵值是对不确定性的一种度量。熵值法用以确定指标权重的根据是各项指标在数值层面的变异程度,由于对客观数据有着高度依赖,熵值法的运用过程中避免了人为因素对指标权重结果可能造成的偏差。熵值法利用信息熵计算出各指标的权重值,为多指标综合评价提供依据。
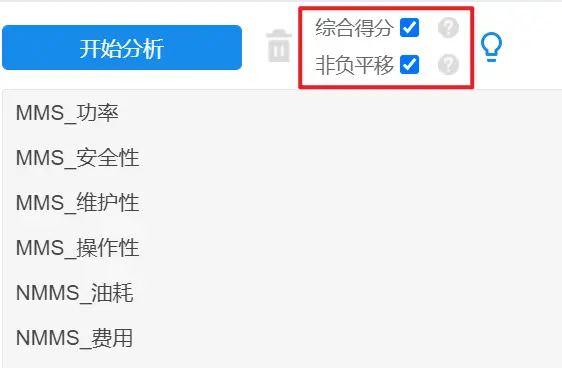
将处理好的数据,使用SPSSAU熵值法进行分析,分析前勾选【综合得分】,SPSSAU会在分析时自动保存各变量的综合得分,最后用于综合评价。分析前还需要勾选【非负平移】,原因在于熵值法计算过程中,含有对数运算,而当数据存在0或负数时,无法进行对数运算,所以SPSSAU提供非负平移功能,如果数据小于等于0,此时平移单位为:最小值的绝对值+0.01,保证数据全部为正数可正常计算。SPSSAU操作如下:
熵值法计算权重结果如下表:
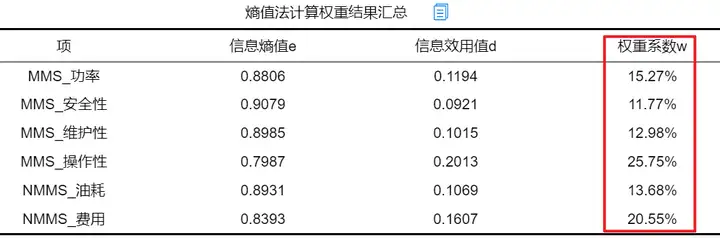
从上表可以看出,使用熵值法计算得到功率、安全性、维护性、操作性、油耗、费用的权重值分别为0.153, 0.118, 0.130, 0.257, 0.137, 0.206。
熵值法计算公式:
(1)信息熵值e
①计算第j项指标下第i个样本值占比重
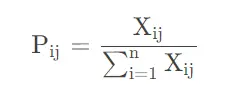
②计算各指标的信息熵(列)
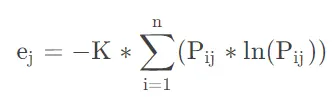
其中,k=1/ln(n);
(2)信息效用值d
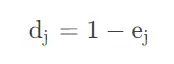
(3)权重系数值w
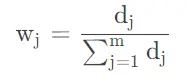
得到的权重值,将用于后续综合得分计算。
四、综合得分
(1)综合得分的意义
综合得分是熵值法用于最终综合评价的决定性指标。得到各指标权重后,将各指标数据与对应的权重相乘后进行累加,即为“综合得分”。综合得分可用于衡量各样本的综合水平,综合得分越高的样本越优秀。
这个指标并不需要手动计算,因为在分析前,勾选了【综合得分】,所以SPSSAU会自动完成计算并保存到【我的数据】中。
(2)优劣对比
SPSSAU生成的综合得分数据如下:
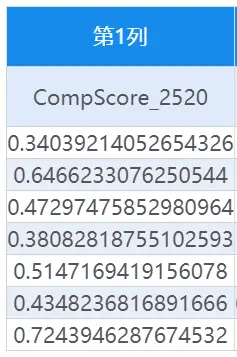
分析人员将数据下载至本地,将综合得分进行排序,进行样本之间的优劣对比。也可使用SPSSAU生成变量中的Rank排名功能,对综合得分进行排名。操作如下:
最终,将数据下载后使用Excel整理得到各品牌车综合得分排名如下:
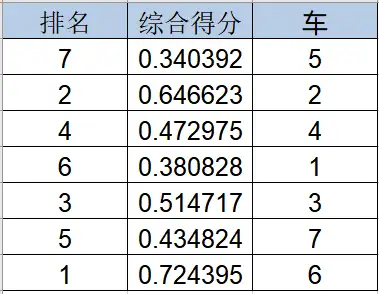
从分析结果来看,本次参与分析的7辆品牌车,综合得分最高的为车辆6,综合得分最低的为车辆5。说明车辆6在这7辆车中各方面维度是最优的,最差的是车辆5。
六、总结
本次分析使用熵值法对7类品牌车辆进行综合评价,在进行熵值法分析之前,首先对数据进行了方向处理和量纲处理,消除由于方向不统一和单位不统一的影响。然后使用SPSSAU进行熵值法分析,得到各指标权重值以及各样本综合得分值,经过对综合得分进行排名对比,得到各方面最优车辆为车辆6,最差的为车辆5,分析完毕。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号