模型不达标调整
一 、模型不达标调整
模型构建就是——科学的研究问题的数学表达;比如线性回归模型中的模型公式。
在进行建模时,很多同学会遇到模型不达标的问题,这种情况很常见,通常需要进行模型不达标的调整。
模型不好如何处理
模型拟合不好,我们能想到的原因主要有以下几个方面
其一:样本的多少
通常情况下,样本越多,样本的数据质量越高,那么会对模型拟合有正向的帮助;
其二:测量指标的好坏与多少
如果选取的指标不能很好地代表所研究的问题,那么指标的选取就存在问题,会影响到后续模型的拟合;同时,指标如果过少(考虑不全面,如缺少控制变量)、过多(指标冗杂、重复指标较多)都会影响到模型的好坏。
其三:模型存在潜在问题
例如:忽略了异方差和共线性的问题,导致模型不好。
其四:模型需要更换
如果无论如何调整都无法很好的拟合模型,则需要考虑更换模型。
综上所述:当模型不好时,可以从样本变化、指标变化、模型修正、模型更换四个方面进行调整。
① 样本变化
- 增加样本
数据分析中,一般来讲,样本量越多越好,样本量过少会引起数据分析结果的代表性降低;因此增加样本量,可以作为调整模型的一种方式。
增加样本可以从两方面考虑:
其一加入新样本,扩大整体样本量;
其二将缺失值进行填补
SPSSAU系统数据处理->异常值功能,可将缺失数据(null)进行填补。SPSSAU当前支持平均值、中位数、众数和随机数填补等。一般情况下,平均值、中位数或众数使用较多。
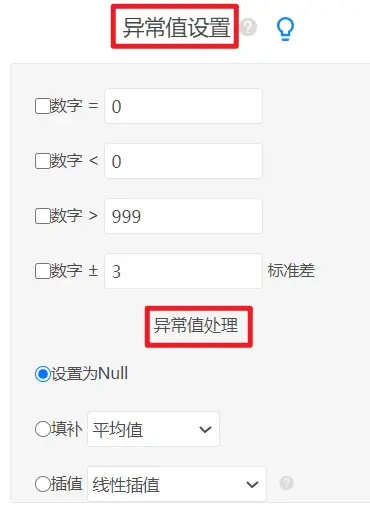
- 删减样本
如果样本数据质量不高,缺失值和异常值较多,同样会影响到模型的拟合。那么,删减样本也可以作为模型调整的一种方式。
删减样本包括无效值处理和异常值处理两方面。对于异常值,常见的处理方法比如缩尾or截尾处理;同样,可以在SPSSAU系统->数据处理板块进行操作。
② 指标变化
- 替换法
指标的选取会影响模型拟合效果,如果使用不合适的指标描述所研究问题,那么错误的指标得到的模型自然是错误的。虽然一些指标代表的意义乍一看相近,可以替换使用,但是“差之毫厘失之千里” ,所以,将指标进行替换可以作为一种模型调整方式。
例如:一般使用人均GDP而不使用GDP衡量一个地区的发展水平
- 增加指标
如果指标的选取并不全面,无法涵盖绝大部分信息,那么模型自然也是不好的,所以增加指标为指标变化调整的另一种方式。例如:研究地区经济的发展时,忽略了控制变量人口,那么就需要相应地增加控制变量(干扰变量);或者其他容易忽略的个体属性(如年龄、性别等)、遗漏变量等。
- 删除指标
将重复指标或者质量差的指标进行删除,也是模型调整的一种方式。例如:研究学生学习水平时,“ 学历 ” 和 “ 受教育年限 ” 之间一定存在很强的共线性,二者取其一即可。
③ 模型修正
模型不达标还可能是因为忽略了一些需要在意的问题,比较常见的有是否存在异方差或共线性问题。
- 异方差问题
处理异方差问题有三种办法,分别是数据处理(取对数等)、稳健标准误回归、FGLS回归。
- 共线性问题
如果出现多重共线性问题,一般可有3种解决办法:一是使用逐步回归分析(让模型自动剔除掉共线性过高项);二是使用岭回归分析(使用数学方法解决共线性问题);三是进行相关分析,手工移出相关性非常高的分析项(通过主观分析解决),然后再做线性回归分析。
④ 模型更换
如果无论如何调整都无法很好的拟合模型,则需要考虑更换模型。
例如:使用结构方程模型研究影响关系时,模型不达标,可以考虑将结构方程模型改为路径分析;或者改为研究线性回归模型。
或者,在研究线性回归模型时,可以改为研究二元logit回归(例如将收入换成“高收入和低收入”两类)。
二、减少模型不达标问题经验说明
为了尽量避免模型不达标的情况,应该从前期样本准备、指标选择就做好准备。接下来,小编将说明前期数据以及模型的一些基本准备;并使用问卷式模型以及计量式模型进行举例,分享一些模型构建的注意事项。
1、数据准备
- 数据样本量尽量多
保证样本量尽量多的目的有两个分别是:稳健性检验、防止样本有缺失
- 数据完善性
缺失样本不能过多,会影响分析结果
- 指标有预留
指标最好在开始的时候,就多预留出几个,其目的有三,分别是:用作控制变量、稳健性检验、替换作用。
说明——稳健性检验
稳健性检验通俗的讲,就是改变某个特定的参数,进行重复的实验,来观察实证结果是否随着参数设定的改变而发生变化,如果改变参数设定以后,结果发现符号和显著性发生了改变,说明不是稳健性的,需要寻找问题的所在。一般根据自己文章的具体情况选择稳健性检验 ① 从数据出发,根据不同的标准调整分类,检验结果是否依然显著 ② 从变量出发,从其他的变量替换,如:研发金额投入可以使用研发项目数量衡量 ③ 从计量方法出发,可以用OLS等进行回归,看结果是否依然显著
2、模型准备
- 在找数据时,应该大概知道模型是什么样子
带着目的找数据,可以节省时间,提高数据准确性以及与研究问题的匹配度。
- 模型尽量有备选
如果一个模型不合适,可以及时更换模型,不至于重头再来,节省时间与精力。
3、问卷式模型
例如:研究商超购物满意度模型
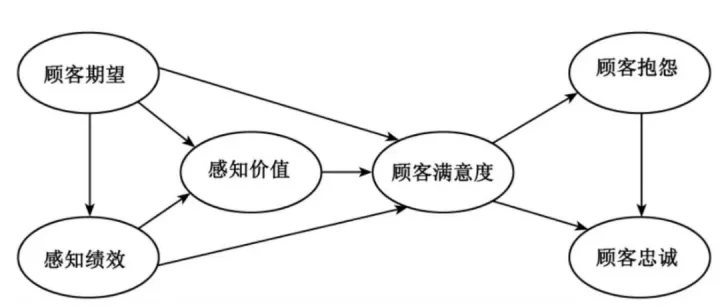
数据准备:上图中六个变量分别对应的数据
可以从样本量、样本特征、变量测量3个角度做文章
问卷设计注意事项:
- 一个指标尽量多对应问卷题目,建议4~7个
便于后续的筛选、删除;在后面的调整模型时也可能用到。
- 其他相关数据——人口统计学变量
干扰变量(控制变量)的设计可用于模型调整、丰富分析内容。

基于结构方程模型的黑龙江冰雪旅游游客满意度研究-成春蕾
- 必填题目设置——用于模型调整和稳健性检验使用
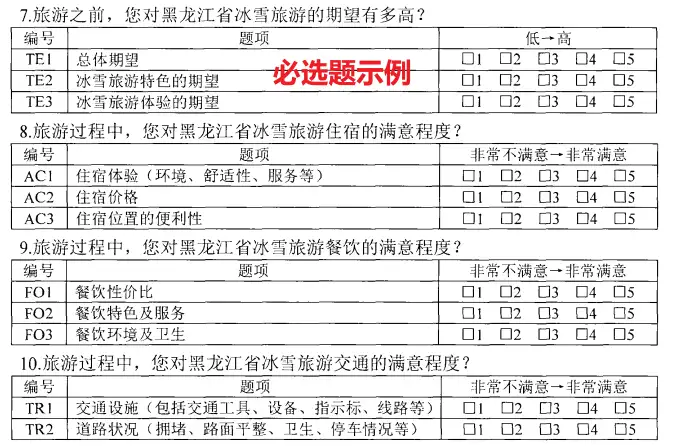
基于结构方程模型的黑龙江冰雪旅游游客满意度研究-成春蕾
- 筛选题设置——用于筛选适合样本
例如:消费次数1次/年,2~5次/年,5~10次/年,10次以上/年;如果填写问卷的参与调查的人在该商超的消费次数过低,自然应该被排除在外,不属于我们研究的合适样本。同时,筛选题的设置可用于后续模型的调整和模型稳健性检验使用。

基于结构方程模型的黑龙江冰雪旅游游客满意度研究-成春蕾
- 样本量
收集的问卷有效样本量应该在问卷题目个数的5倍以上,若样本数据偏离正态分布,则样本量最好为问卷题目数的10倍以上,以便模型数据更具有说服力。
问卷研究常用方法:
在SPSSAU系统中,提供多种主流问卷研究方法,常见的主要有信度分析、效度分析、多选题分析、调节作用、中介作用、路径分析、结构方程模型等方法。
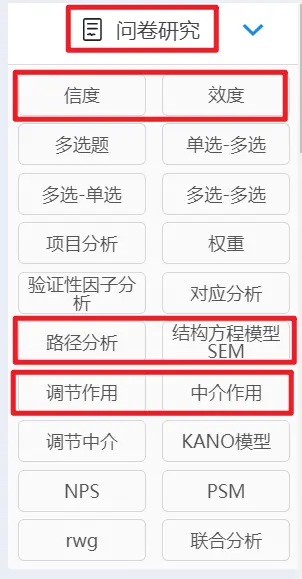
同学们可结合自己所研究问题,进行方法的选择。如果不知道自己应该进行哪种分析,还可以在SPSSAU官网右上角客服中心联系人工客服,会有专业老师解答问题。
4、计量式模型
例如:高管团队特征对企业创新投入的影响

编辑切换为居中
添加图片注释,不超过 140 字(可选)
- 数据准备:各个变量分别对应的数据
- 样本量、指标变化、模型更换
- 确定自变量、控制变量、因变量
自变量(解释变量):女性高管人数、高管团队任期、高管团队受教育水平(受教育年限)等
控制变量:企业资产、企业盈利指标ROA、政府补贴等
因变量(被解释变量):研发投入金额
注意事项:
- 数据尽量多
例如:使用多个年份、多个行业(国有企业、外资企业等)的数据
可以达到样本筛选、模型调整、稳健性检验、丰富研究、异常数据清理的目的。

高管团队特征对企业创新的影响研究——王彩虹
- 指标更换
例如:高管团队任期替换为高管团队更换频率
受教育水平替换为受教育年限
研发投入金额替换为研发项目数量等等
指标更换对应数据准备中的指标有预留,为的是后续进行模型不达标调整、稳健性检验等等。

高管团队特征对企业创新的影响研究——王彩虹
- 模型更换
例如:OLS回归->robust回归
OLS回归->面板模型
OLS回归->是否加入控制变量 / 控制变量的变化等等
模型更换是进行模型不达标调整的最后底线
计量研究常用方法:
在计量经济研究中,可选择的方法更多,需要结合所研究内容以及自身专业进行判断,可以在SPSSAU官网查看每种方法的帮助手册进行方法的学习,常见的研究方法如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号