如何处理多重共线性问题
一、说明
当回归模型中两个或者两个以上的自变量高度相关(比如相关系数大于0.7)时,则称为多重共线性。虽然在实际分析中,自变量高度相关是很常见的,但是在回归分析中存在多重共线性可能会导致一些问题,比如相关分析是负相关回归分析时影响关系是正影响等,所以针对多重共线性问题需要去解决。
二、判断标准与处理办法
1.判断标准
那么如何去解决多重共线性问题?首先对多重共线性的常见判断标准进行说明:
一般有3种方法可以检测多重共线性。
-
较常使用的是回归分析中的VIF值,VIF值越大,多重共线性越严重。一般认为VIF大于10时(严格是5),代表模型存在严重的共线性问题。
-
有时候也会以容差值作为标准,容差值=1/VIF,所以容差值大于0.1则说明没有共线性(严格是大于0.2),VIF和容差值有逻辑对应关系,两个指标任选其一即可。
-
除此之外,直接对自变量进行相关分析,查看相关系数和显著性也是一种判断方法。如果一个自变量和其他自变量之间的相关系数显著,则代表可能存在多重共线性问题。
2.处理办法
多重共线性是普遍存在的,通常情况下,如果共线性情况不严重(VIF<5),不需要做特别的处理。如存在严重的多重共线性问题,可以考虑使用以下几种方法处理:
(1)手动移除出共线性的变量
先做下相关分析,如果发现某两个自变量X(解释变量)的相关系数值大于0.7,则移除掉一个自变量(解释变量),然后再做回归分析。此方法是最直接的方法,但有的时候我们不希望把某个自变量从模型中剔除,这样就要考虑使用其他方法。
(2)逐步回归法
让系统自动进行自变量的选择剔除,使用逐步回归将共线性的自变量自动剔除出去。此种解决办法有个问题是,可能算法会剔除掉本不想剔除的自变量,如果有此类情况产生,此时最好是使用岭回归进行分析。
(3)增加样本容量
增加样本容量是解释共线性问题的一种办法,但在实际操作中可能并不太适合,原因是样本量的收集需要成本时间等。
(4)岭回归
上述第1和第2种解决办法在实际研究中使用较多,但问题在于,如果实际研究中并不想剔除掉某些自变量,某些自变量很重要,不能剔除。此时可能只有岭回归最为适合了。岭回归是当前解决共线性问题最有效的解释办法。
三、案例说明
一家大型商业银行在多个地区设有分行,其业务主要是进行基础设施建设、国家重点项目建设、固定资产投资等项目的贷款。近年来,该银行的贷款额平稳增长,但不良贷款额也有较大比例的提高,这给银行业务的发展带来较大压力。(案例参考来源:统计学 第7版 中国人民大学出版社)为了弄清不良贷款形成原因,管理者希望利用银行业务的有关数据进行分析,以便参考不良贷款对该银行所属的25家分行进行分析发现自变量之间存在较高的相关性,因而查看vif值发现存在多重共线性,案例选择岭回归模型进行处理。具体分析如下:
四、判断多重共线性
该案例利用相关分析和检验VIF值两个方面进行验证多重共线性。首先进行相关分析以及进一步查看VIF值。
1.相关分析
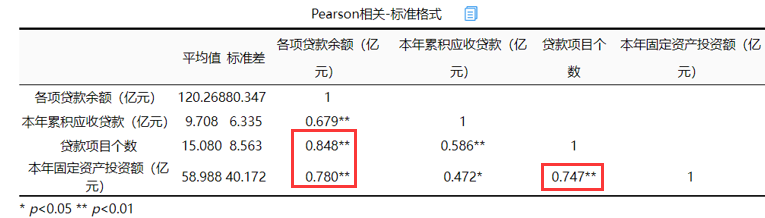
添加图片注释,不超过 140 字(可选)
从图片上来看“各项贷款余额”与“贷款项目个数”、“本年固定资产投资额”以及“贷款项目个数”与“本年固定资产投资额”高度相关相关系数都分别约为0.848、0.780以及0.747都大于0.7,说明可能存在共线性问题进一步查看vif值进行确定。
2.VIF值
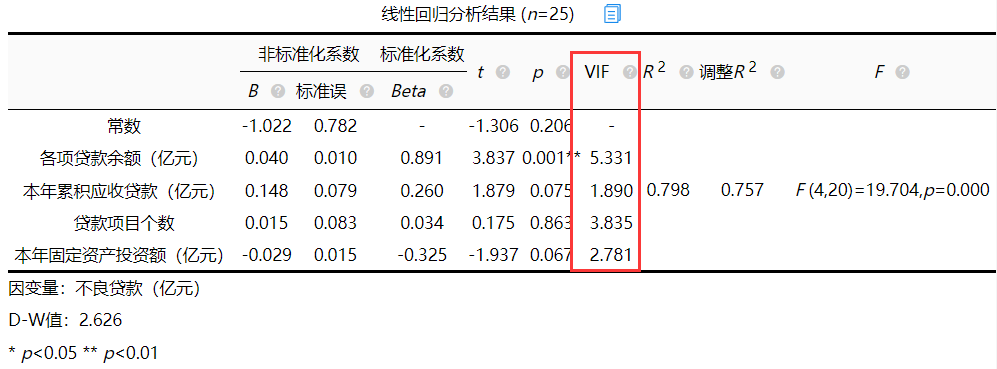
添加图片注释,不超过 140 字(可选)
从结果中可以看出,分析项中VIF值存在大于5的现象从严格意义来讲存在多重共线性,并且相关分析发现自变量之间存在较高的相关性。如果研究者也遇到此类问题,结果并不影响分析则不需要处理。所以该案例分析场景认为存在多重共线性,因为不想剔除自变量所以使用岭回归更合适。用岭回归进行分析后就不需要担心共线性的问题了。
五、岭回归
首先岭回归分析前需要结合岭迹图确认K值。首先拖拽分析项到分析框,不输入K值,SPSSAU会默认生成岭迹图,同时给出智能分析建议。
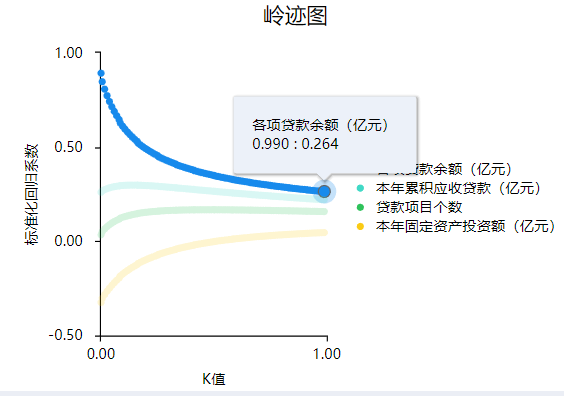
添加图片注释,不超过 140 字(可选)
图中可以看到,当K值为0.99时,此时自变量的标准化回归系数趋于稳定,因而SPSSAU建议设置最佳K值取为0.99。
本案例中K值取0.99,返回分析界面,输入K值,得出岭回归模型估计。输出结果如下:
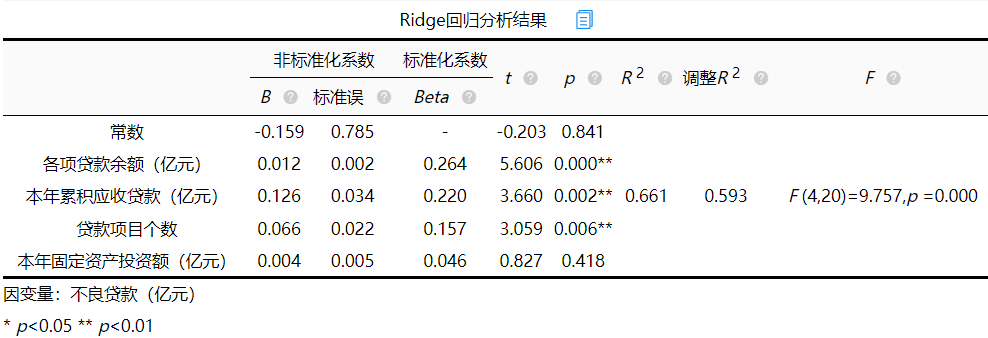
添加图片注释,不超过 140 字(可选)
从模型效果和模型结果两个方面进行说明:其中模型效果包括F检验和模型拟合优度。
-
模型效果
首先对F检验进行查看与说明。
-
F检验

添加图片注释,不超过 140 字(可选)
回归方程的显著性检验中,统计量F=9.757,对应的p值小于0.05,通过检验,说明模型显著。然后对模型拟合优度进行简单查看。
(2)拟合优度

添加图片注释,不超过 140 字(可选)
从上表可以看出,模型R方值为0.661,意味着各项贷款余额, 本年累积应收贷款, 贷款项目个数, 本年固定资产投资额可以解释不良贷款的66.12%变化原因。说明模型拟合较好,接下来对模型结果进行分析。
-
模型结果
接下来对模型结果进行分析。其中包括模型公式,分析结果以及影响关系及大小。
-
模型公式与结果
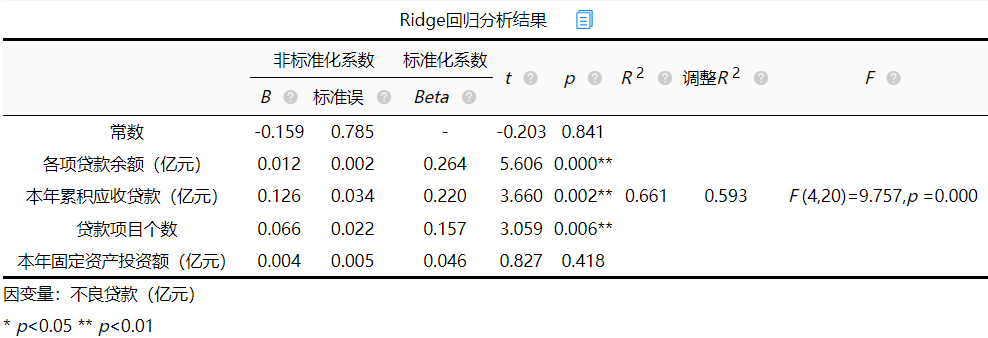
添加图片注释,不超过 140 字(可选)
从上表可知, 模型公式为:不良贷款(亿元)=-0.159 + 0.012*各项贷款余额(亿元) + 0.126*本年累积应收贷款(亿元) + 0.066*贷款项目个数 + 0.004*本年固定资产投资额(亿元)。 模型的结果为: 各项贷款余额、本年累积应收贷款、贷款项目个数三个自变量p值均小于0.05,具有显著性差异,而本年固定资产投资额p值为0.418大于0.05,不具有统计学意义。
-
影响关系及大小
如果说自变量X已经对因变量Y产生显著影响(P<0.05),还想对比影响大小,建议可使用标准化系数值的大小对比影响大小,上图所示,显著的自变量中,各项贷款余额、本年累积应收贷款、贷款项目个数的标准化系数分别为0.264、0.220、0.157。所以各项贷款余额标准化系数最大,进而看出模型中各项贷款余额对不良贷款影响较大。
六、结论
通过对数据进行简单查看,发现数据具有多重共线性所以对数据进行处理,处理的方式选择岭回归,对岭回归分模型效果和模型结果两个方面进行阐述,最后得到公式为:不良贷款(亿元)=-0.159 + 0.012*各项贷款余额(亿元) + 0.126*本年累积应收贷款(亿元) + 0.066*贷款项目个数 + 0.004*本年固定资产投资额(亿元)。以及管理者进行决策时可以多关注“各项贷款余额”这个指标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号