聚类案例分析全流程汇总
一、案例说明
1.案例背景
研究调查10名运动员的3项测试数据,其中三项分别是:肩宽/髋宽×100、胸厚/胸围×100、腿长/身长×100。其中编号为4、6、8、9的4名运动员分别是蛙、自由、仰、蝶泳四种姿势的佼佼者。预计姿势按姿势分为蝶泳、仰泳、蛙泳、自由泳4类(为简化问题仅以10名运动员的3项测试数据为例)。
2.分析目的
本案例对游泳运动员调查的数据进行聚类,以便分项,预计姿势按姿势分为蝶泳、仰泳、蛙泳、自由泳4类。 [案例来源于:SPSS统计分析(第5版)卢纹岱,朱红兵主编,案例有一些变动 具体请看分析。]
二、数据处理
1.数据检查
在数据分析之前,首先需要进行数据查看,包括数据中是否有异常值,无效样本等。如果有异常值则需要进行处理,然后再进行分析。另外如果数据中有无效样本也需要进行处理后再进行分析。无效样本会干扰分析研究,扭曲数据结论等,因而在分析前先对无效样本进行标识显示尤其必要。异常值的鉴别与处理一般分为三个部分,其中分别是判断标准,鉴别方法以及异常值的处理,以下从这三个方面进行说明。
异常值的判断标准如下:

检验数据是否有异常值的方法:
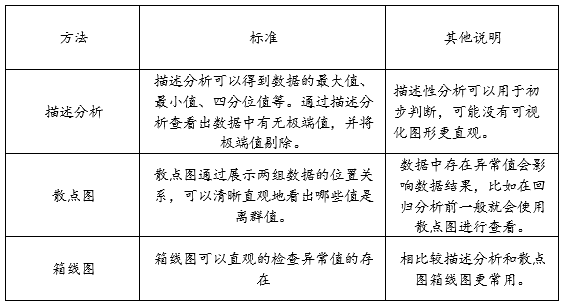
异常值处理方法:
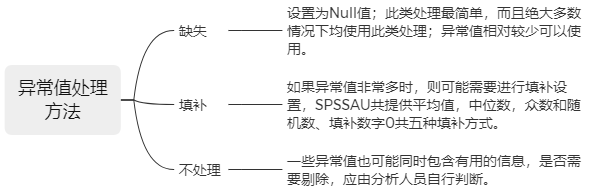
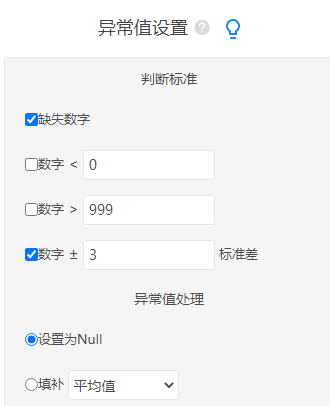
此案例对于异常值参照的标准为大于±3个标准差
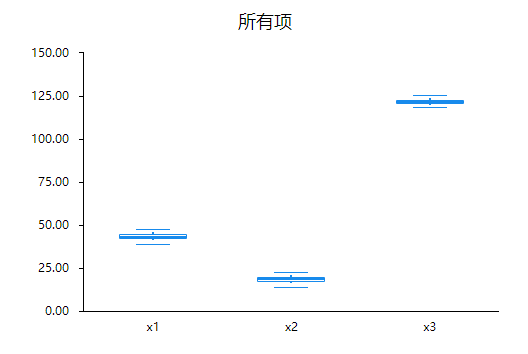
使用箱线图进行查看发现没有异常值。
除了对异常值的处理,还需要对于无效样本进行检查:如果数据来源为问卷,则很可能出现无效样本,因为填写问卷的样本是否真实填写无从判定;如果数据库下载或者使用二手数据等,也可能出现大量缺失数据等无效样本。以下从无效样本场景、SPSSAU设置标准、处理三方面进行说明。
1.常见场景
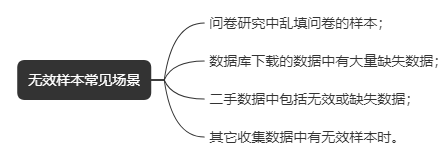
2.设置标准

3.无效样本的处理
设置好无效样本后,默认会新生成一个标题,用来标识那些样本是有效,那些是无效,在分析的时候直接进行筛选下就好。
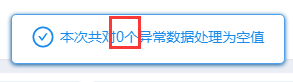
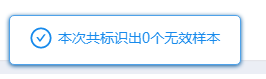
本次案例分析将以相同数字大于70%为标准进行检验,结果显示没有无效样本。
2.标题处理
将变量肩宽/髋宽×100设为x1、变量胸厚/胸围×100设为x2、变量腿长/身长×100设为x3。
三、操作
首先对初始计划进行分析得到模型如下:
 分析结果来源于SPSSAU
分析结果来源于SPSSAU
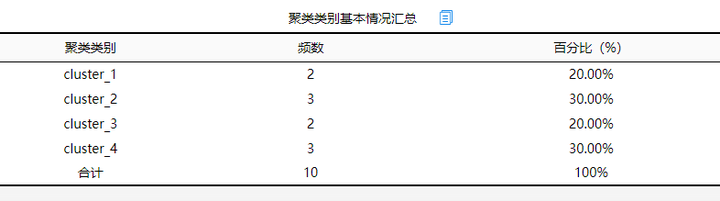
从上表可以看出:最终聚类得到4类群体, 4类人群分布较为均匀,整体说明聚类效果较好。如果分析人员没有预设聚类个数也可以利用该方法对数据类别进行初步判断,若该案例数据聚类个数为3,结果如下:

从结果来看,若分为三类,数据中第三个类别占比较多,不如分为4类的结果均匀,综合结果对比聚类个数选择4,但是就此案例说明,若研究者的预设聚类个数为3,也是可以接受的。
总结来讲,不需要对模型进行调整,重复进行案例模型的构建。
聚类分析往往是一个主观判断的过程,需要根据分析结果及个人专业知识判断,聚为几类更合适。这里结合SPSSAU输出结果,提供几个判断聚类效果的方法:
 分析结果来源于SPSSAU
分析结果来源于SPSSAU
接下来将对此一一说明。
四、结果输出及分析
首先要查看数据分布是否均匀,一般来说,每个类别的样本比例应分布均匀,如果出现某一类占比过大或过小,可以考虑重新设置聚类类别个数。
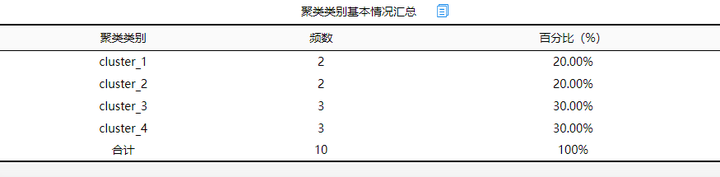
1.聚类基本情况
 分析结果来源于SPSSAU
分析结果来源于SPSSAU
使用聚类分析对样本进行分类,使用Kmeans聚类分析方法,从上表可以看出:最终聚类得到4类群体,此4类群体的占比分别是20.00%, 20.00%, 30.00%, 30.00%。整体来看, 4类人群分布较为均匀,整体说明聚类效果较好。
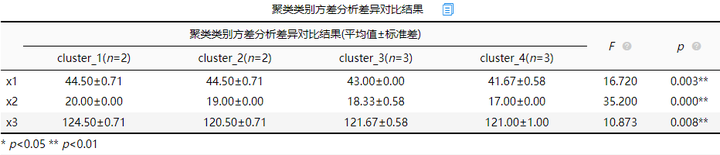
2.方差分析
 分析结果来源于SPSSAU
分析结果来源于SPSSAU
聚类类别与聚类分析项进行交叉分析,如果呈现出显著性(p<0.05),意味着聚类得到的不同类别样本,在相同指标上有明显的差异。这说明参与聚类分析的3个变量能够很好的区分类别,类间差异足够大,其中p值越小说明明类别之间的差异越大,表中显示自变量x2的类别之间差异性最大。
对不同类别进行均值比较除了可以查看方差分析还可以进行查看聚类项重要性对比。
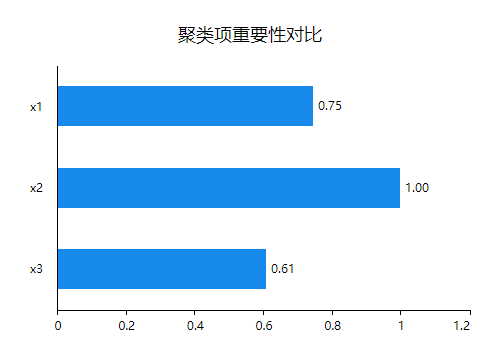 分析结果来源于SPSSAU
分析结果来源于SPSSAU
如果某个指标重要性较低,考虑移出该指标。从上述结果看,所有研究项均呈现出显著性,说明不同类别之间的特征有明显的区别,聚类的效果较好。
3.聚类效果的图示化
可通过散点图直观展示聚类效果,使用任意两个聚类指标进行散点图绘制(可视化模块里面的散点图),并且在‘颜色区分(定类)[可选]框中放入‘聚类类别’项,以查看不同类别时,两两指标的散点效果。
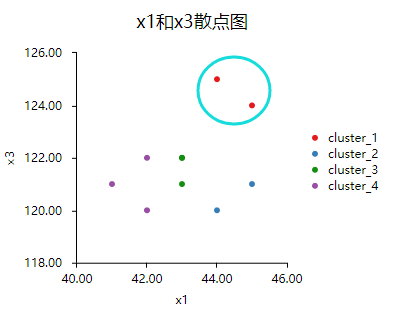 分析结果来源于SPSSAU
分析结果来源于SPSSAU
从图中可以发现各个类别之间有明显的区别,聚类的效果较好。其中发现第一个类别x1、x3都比较大,建议研究时可以更加关注。
4.聚类类别实际意义
根据编号为4、6、8、9的4名运动员分别是蛙、自由、仰、蝶泳四种姿势的佼佼者。
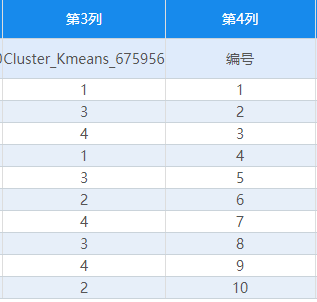
可以将第一类命名为蛙泳,第二类命名为自由泳,第三类命名为仰泳,第四类命名为蝶泳。
研究者也可以观察折线图趋势进行命名。参考如下:
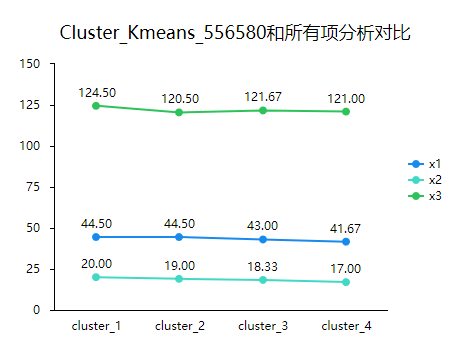 分析结果来源于SPSSAU
分析结果来源于SPSSAU
五、其它
1.聚类中心
整体说明聚类效果较好
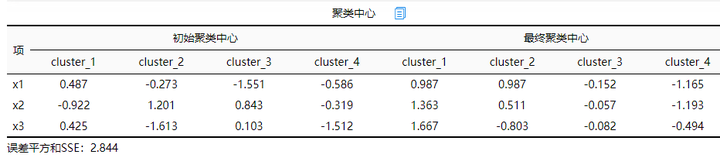 分析结果来源于SPSSAU
分析结果来源于SPSSAU
上表为经过迭代后类中心的变化,数据是经过标准化后的,至于数据是否需要标准化,聚类算法是根据距离进行判断类别,因此一般需要在聚类之前进行标准化处理,SPSSAU默认是选中进行标准化处理。数据标准化之后,数据的相对大小意义还在(比如数字越大GDP越高),但是实际意义消失了。
2.SSE
对于聚类中心的SSE指标说明如下:
在进行Kmeans聚类分析时SPSSAU默认输出误差平方和SSE值,该值可用于测量各点与中心点的距离情况,理论上是希望越小越好,而且如果同样的数据,聚类类别越多则SSE值会越小(但聚类类别过多则不便于分析)。SSE指标可用于辅助判断聚类类别个数,建议在不同聚类类别数量情况下记录下SSE值,然后分析SSE值的减少幅度情况,如果发现比如从3个聚类到4个类别时SSE值减少幅度明显很大,那么此时选择4个聚类类别较好。比如该案例若聚类数为3,此时SSE值为7.451,但是当聚类数为4时此时SSE值为2.844,发现SSE减少幅度较大。所以可以看出选择4个聚类类别较好。

六、总结
对案例数据首先进行数据的检查,没有发现缺失值与异常值,针对聚类的基本情况分析,发现数据可以进行聚类,以及对聚类类别的选择,最后对于输出的结果进行分析,得到结论。如果有定类数据,或使用分层聚类方法分析,分析思路也是如此。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号