因子分析后如何进行聚类分析?
一、案例说明
1.案例背景
研究短视频平台用户行为的分类情况,调查搜集了200份数据其中20项可分为品牌活动,品牌代言人,社会责任感,品牌赞助和购买意愿品牌五个维度。案例数据中还包括基本个体特征比如性别、年龄,学历,月收入等。以及短视频平台观看情况和消费情况。数据样本为200个。
2.分析目的
想要根据短视频平台调查的数据进行聚类分析,由于分析项过多,所以先进行因子分析,将得到的因子得分进行聚类分析后进行命名,以及和其他基本个体特征比如性别进行交叉分析最终得到结论。
二、SPSSAU操作
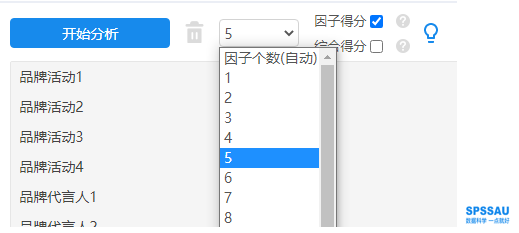
因为案例的预设维度为5所以将分析项拖拽到右侧分析框后,下拉选择因子个数为5并勾选因子得分。
三、因子分析结果
1.前提条件
KMO值与Bartlete球形检验
 分析结果来源于SPSSAU
分析结果来源于SPSSAU
使用因子分析进行信息浓缩研究,首先分析研究数据是否适合进行因子分析,从上表可以看出:KMO值为0.929,大于0.6,满足因子分析的前提要求,意味着数据可用于因子分析研究。以及数据通过Bartlett 球形度检验(p<0.05),说明研究数据适合进行因子分析。接下来查看分析项是否需要调整。
2.因子与测量项之间的关系
因子分析进行因子浓缩时,通常会经历多个重复循环,删除不合理项,并且重复多次循环,最终得到合理结果。一般出现的情形我们分为两种,一种为“张冠李戴”,一种为“纠缠不清”,具体描述如下。
(1)“张冠李戴”
一般情况下,如果20项与5个因子之间的对应关系情况,与专业知识情况不符合,比如第一项本该属于第二个因子但是被划分到了第一个因子下面,此时则说明可能该项应该被删除处理,其出现了‘张冠李戴’现象。例如案例中的“购买意愿1”和“购买意愿4”。
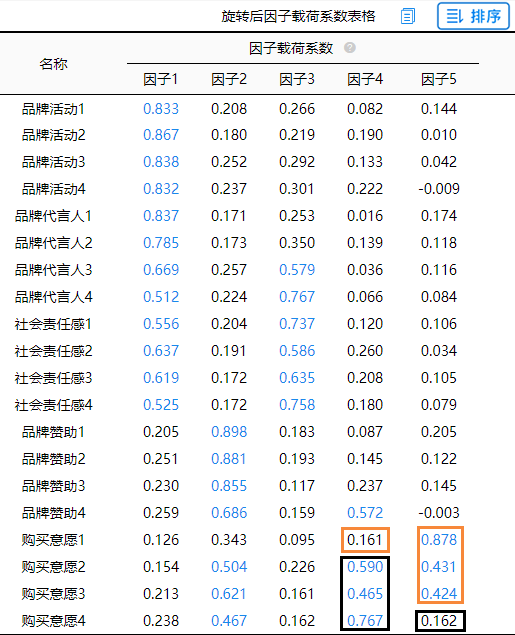 分析结果来源于SPSSAU
分析结果来源于SPSSAU
(2)“纠缠不清”
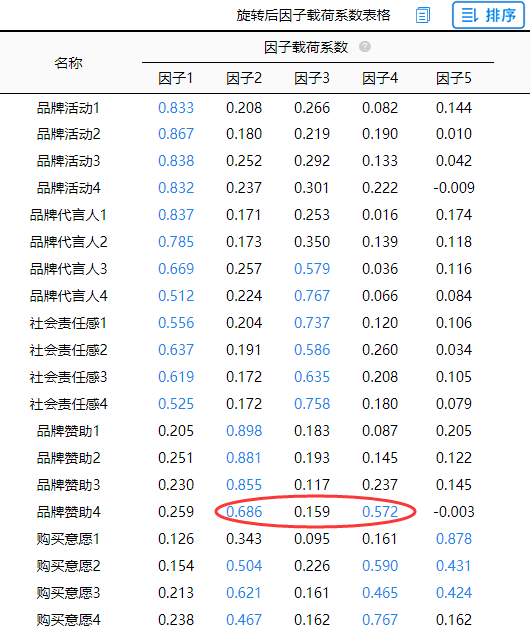
除了“张冠李戴”现象,有时候会出现‘纠缠不清’现象,比如案例中的“品牌赞助4”可归属为因子2,同时也可归属到因子4,这种情况较为正常(称作‘纠缠不清’),需要结合实际情况处理即可,可将该项删除,也可不删除,这时,分析带有一定主观性。
Step1: 第一次分析
本例子中共20个分析项,此20个分析项共分为5个维度,因此在分析前可主动告诉SPSSAU,此20项是五个因子,否则SPSSAU会自动判断多少个因子(通常软件自动判断与实际情况有很大出入,所以建议主动设置因子个数)。如下图:
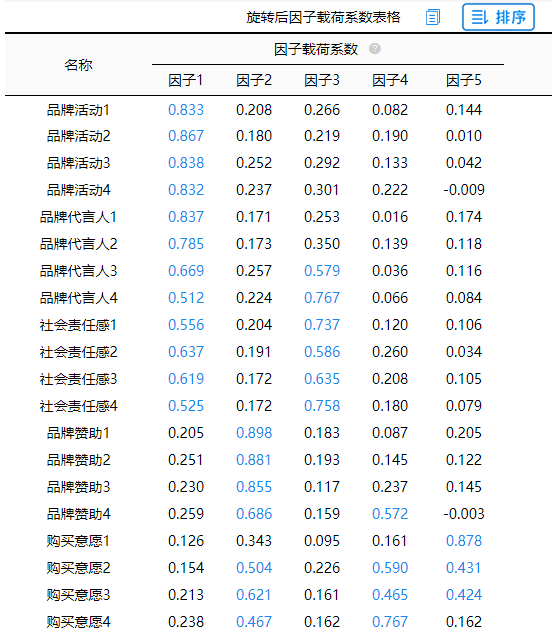
从上图中可以看出:
品牌活动1-4这4项,它们全部对应着因子1,因子载荷系数值均高于0.4,说明此4项应该同属于一个维度,即逻辑上品牌活动1-4这4项,并没有出现 “张冠李戴”现象。4个分析项值隶属于因子1一个维度也没有出现“纠缠不清”的情况。
品牌代言人1-4共4项,它们全部对应着因子1,但是品牌代言人3、品牌代言人4同时又属于因子3,属于“纠缠不清”,暂不处理。
“社会责任感1-4”共4项,此4项均对应着因子1或因子3,此3项并没有出现‘张冠李戴’问题,但是出现了“纠缠不清”。
“品牌赞助1-4”共4项,它们全部对应着因子2,“品牌赞助4”既对应因子2又对应因子4出现了“纠缠不清”,应该给予关注。
“购买意愿1-4”共四项,当他们对应因子4则“购买意愿1”出现“张冠李戴”若对应因子5则“购买意愿4”出现“张冠李戴”。
总结上述分析可知:“购买意愿1”或者“购买意愿4”这两项出现“张冠李戴”,应该首先将此两项中的一项删除;而其他出现“纠缠不清”现象的,暂时不处理(进行关注即可)。此次将“购买意愿1”进行删除后重新分析(将“购买意愿4”删除也是可以的,由研究者自己决定)。
Step2: 第二次分析
将“购买意愿1”这项删除后,进行第二次分析。结果如下:
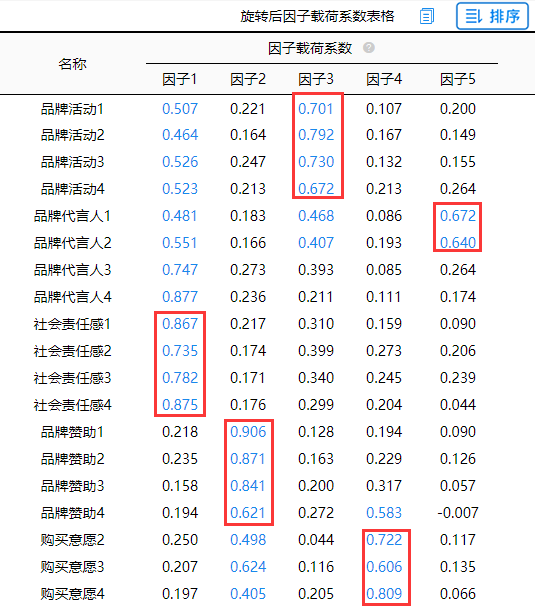 分析结果来源于SPSSAU
分析结果来源于SPSSAU
从上图可知“品牌代言人3”、“品牌代言人4”出现‘张冠李戴’现象,应该删除,以及“品牌活动1-4”、“品牌代言人1-2”等出现‘纠缠不清’现象,暂不处理,但应该给予关注。总结可知:应该将“品牌代言人3”、“品牌代言人4”先删除后再次进行第3次分析。
Step3: 第三次分析
将“品牌代言人3”、“品牌代言人4”删除后再次分析结果如下:
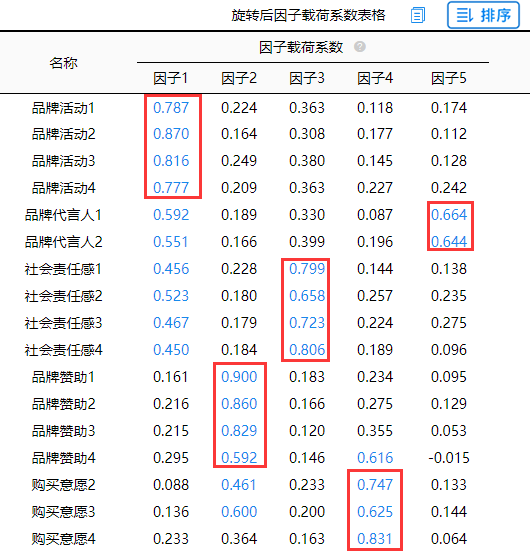 分析结果来源于SPSSAU
分析结果来源于SPSSAU
从上图可知“品牌代言人1-2”可同时出现在因子1和因子5下面,但考虑到因子5当前仅余下2项,因而表示可以接受,以及“社会责任感1-4”是一样的,最终找出五个因子,它们分别与项之间的对应关系良好。因子分析结束。
3.调整因子后的结果
(1)KMO 和 Bartlett 的检验
 分析结果来源于SPSSAU
分析结果来源于SPSSAU
使用因子分析进行信息浓缩研究,首先分析研究数据是否适合进行因子分析,从上表可以看出:KMO值为0.915,大于0.6,满足因子分析的前提要求,意味着数据可用于因子分析研究。以及数据通过Bartlett 球形度检验(p<0.05),说明研究数据适合进行因子分析。
(2)因子载荷系数表
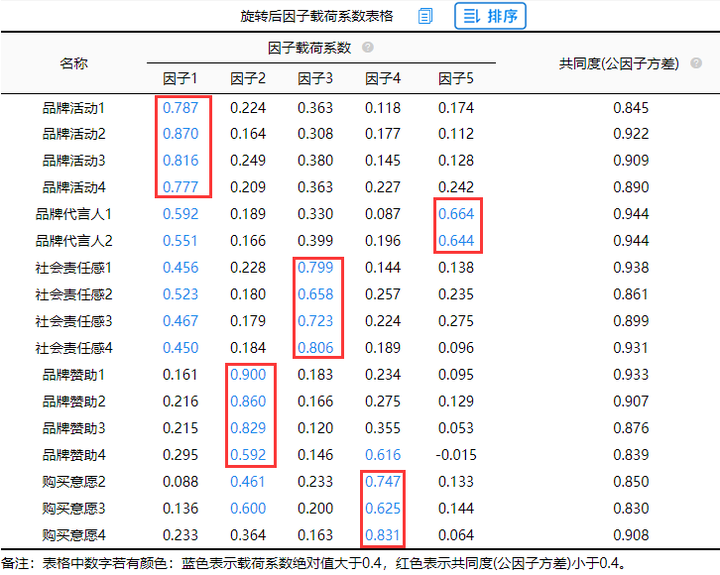 分析结果来源于SPSSAU
分析结果来源于SPSSAU
从上图可知“品牌代言人1-2”可同时出现在因子1和因子5下面,但考虑到因子5当前仅余下2项,因而表示可以接受,以及“社会责任感1-4”是一样的,最终找出五个因子,它们分别与项之间的对应关系良好。分析项不需要进一步调整,接下来进行查看因子的提取个数以及信息浓缩情况。
4.因子提取
(1)方差解释率
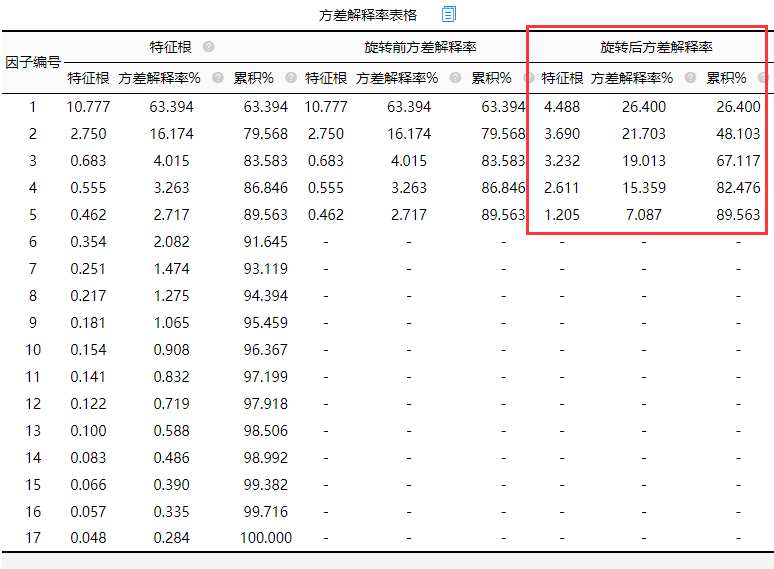 分析结果来源于SPSSAU
分析结果来源于SPSSAU
方差解释率可以说明因子包含原数据信息的多少,方差解释率越大说明因子包含的信息越多。因子分析中,主要关注旋转后的数据部分。由上图可以显示17个指标中,五个因子方差解释率分别为26.400%、21.703%、19.013%、15.359%以及7.087%,累积方差解释率由五项相加为89.563%,累积方差解释率这个值没有固定标准,一般超过60%都可以接受。特征根对于因子的提取有什么作用,以下展开来说。
(2)特征根
特征根一般是指标旋转前每个因子的贡献程度。此值的总和与项目数匹配,此值越大,代表因子贡献越大。当然因子分析通常需要综合自己的专业知识综合判断,即使是特征根值小于1,也一样可以提取因子。在进行因子分析时,研究者没有预设因子数,系统就会以特征根“大于1”为标准进行划分。因为此案例在分析前的预设因子个数为4所以也同样可以进行分析。除了特征根之外SPSSAU还提供了更加直观的碎石图帮助判断。
(3)碎石图
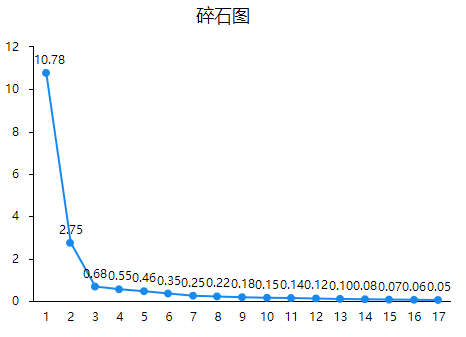 分析结果来源于SPSSAU
分析结果来源于SPSSAU
从图中可以看出,横轴表示指标数,纵轴表示特征根值,当提取前5个因子时,特征根值变化较明显,对解释原有变量的贡献较大;当提取5个以后的因子时,特征根变化也相对平稳,对原有变量贡献相对较小,由此可见提取前5个因子对原变量有的显著作用。碎石图仅辅助决策因子个数,如果由此图分析三个因子也是可以的。
此案例按专业知识来看提取5个因子,如果没有预设因子个数也可以默认让系统进行决策。提取后要观察因子的信息浓缩程度。
5.信息浓缩
旋转后因子载荷系数表
分析结果来源于SPSSAU
旋转后因子载荷系数可以用于判断因子与题项之间的对应关系,如果出现“张冠李戴”或者“纠缠不清”的情况需要关注,上述结果已经是处理后的结果,以及各个题项的共同度。如果某分析项对应的多个因子载荷系数绝对值均低于0.4,可考虑删除该项。上图分析中均大于0.4。所以不用删除调整。
从结果中可以看出,使用因子分析对14个项进行浓缩处理,浓缩为四个因子。因子与题项对应关系如下:
其中品牌活动1-4在因子1上有较高的载荷,说明因子1可以解释这几个分析项,它们主要反映了短视频平台进行品牌传播中的品牌活动;品牌赞助1-4在因子2上有较高的载荷,它们主要反映了短视频平台进行品牌传播中的品牌赞助活动;社会责任感1-4在因子3上有较高的载荷,它们主要反映了短视频平台进行品牌传播的社会责任等;购买意愿2-4在因子4上有较高的载荷,它们主要反映了短视频平台某品牌用户的购买意愿,品牌代言人1-2在因子5上有较高的载荷,它们主要反映了短视频平台某品牌用的代言人受众情况。
从上表可知:所有研究项对应的共同度值均高于0.4,意味着研究项和因子之间有着较强的关联性,因子可以有效的提取出信息。因为本篇案例是想得到因子得分后进行聚类分析进行命名得到有效结论用于公司决策。所以对于因子分析权重方面不进行赘述,如想了解,可以点击文末链接进行查看。
6.因子得分
因子分析往往是预处理步骤,后续还需要结合具体研究目的进行分析,如回归分析、聚类分析等。此时,可能需要用到因子得分,返回分析页面勾选[因子得分]即可生成因子得分。因为本篇案例的研究目的是利用因子得分进行聚类分析,所以需要勾选[因子得分],以及对因子得分进行命名。
5个维度命名分别为品牌活动、品牌赞助、社会责任感、购买意愿以及品牌代言人如下:
接下来利用因子得分进行聚类分析,聚类分析将从,聚类基本情况,方差分析,聚类效果的图示化以及聚类命名来说明。
四、聚类分析结果
首先要查看数据分布是否均匀,一般来说,每个类别的样本比例应分布均匀,如果出现某一类占比过大或过小,可以考虑重新设置聚类类别个数。
1.聚类基本情况
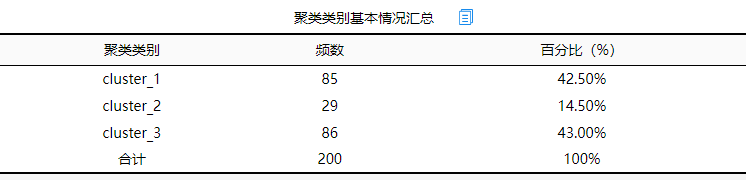 分析结果来源于SPSSAU
分析结果来源于SPSSAU
使用聚类分析对样本进行分类,使用Kmeans聚类分析方法,从上表可以看出:最终聚类得到3类群体,此3类群体的占比分别是42.50%, 14.50%, 43.00%。整体来看,3类人群分布较为均匀,整体说明聚类效果较好。
2.方差分析
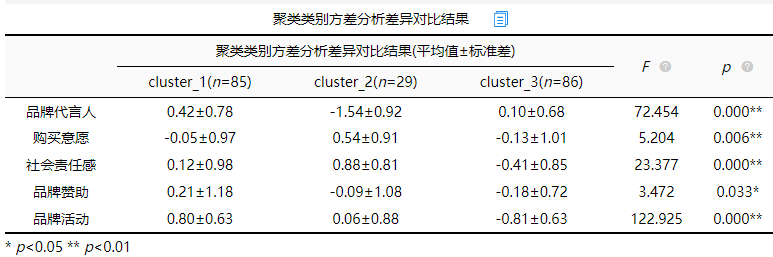 分析结果来源于SPSSAU
分析结果来源于SPSSAU
聚类类别与聚类分析项进行交叉分析,如果呈现出显著性(p<0.05),意味着聚类得到的不同类别样本,在相同指标上有明显的差异。这说明参与聚类分析的5个变量能够很好的区分类别,类间差异足够大,其中p值越小说明明类别之间的差异越大。
对不同类别进行均值比较除了可以查看方差分析还可以进行查看聚类项重要性对比。
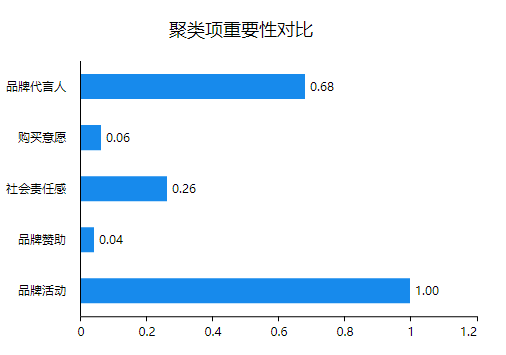 分析结果来源于SPSSAU
分析结果来源于SPSSAU
如果某个指标重要性较低,考虑移出该指标。从上述结果看,所有研究项均呈现出显著性,说明不同类别之间的特征有明显的区别,聚类的效果较好。
3.聚类效果的图示化
可通过散点图直观展示聚类效果,使用任意两个聚类指标进行散点图绘制(可视化模块里面的散点图),并且在‘颜色区分(定类)[可选]框中放入‘聚类类别’项,以查看不同类别时,两两指标的散点效果。
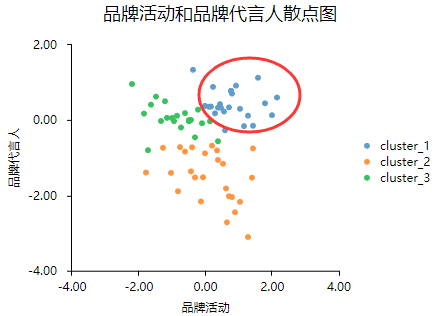 分析结果来源于SPSSAU
分析结果来源于SPSSAU
从图中可以发现各个类别之间有明显的区别,聚类的效果较好。其中发现第一个类别品牌活动与品牌代言人都比较大,建议研究时可以更加关注。
4.聚类类别命名
研究者也可以观察折线图趋势进行命名。参考如下:
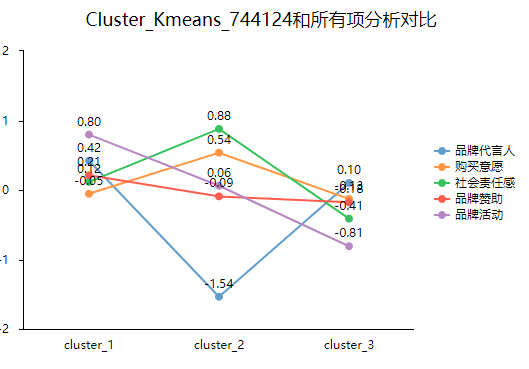 分析结果来源于SPSSAU
分析结果来源于SPSSAU
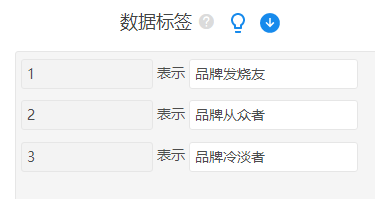
通过上图可知,第一类人群在每个指标上的得分都比较高,可以命名为旅“品牌发烧友”。第二类人群在社会责任感、购买意愿得分较高,品牌代言人、品牌赞助得分较低,品牌活动介于二者之间,可命名为“品牌从众友”。第三类各项得分都较低,命名为“品牌冷淡者”。
将三类命名:SPSSAU‘数据处理’- ‘数据标签’。
5.聚类后的差异分析
得到聚类类别之后,接着需要对比不同类别群体的差异性;如在“性别”、“年龄”上的差异性。最常见与个人信息情况做交叉分析,可以得到不同类型的人群分布情况便于结合不同群体提出针对性的建议措施。本次案例将聚类类别与“年龄”进行交叉分析,如下进行阐述。
 分析结果来源于SPSSAU
分析结果来源于SPSSAU
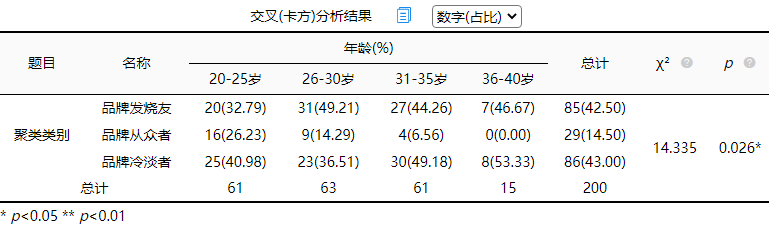
从上表可知,利用卡方检验(交叉分析)去研究年龄对于聚类类别共1项的差异关系,从上表可以看出:不同年龄样本对于聚类类别共1项呈现出显著性(p<0.05),意味着不同年龄样本对于聚类类别共1项均呈现出差异性,具体建议可结合括号内百分比进行差异对比。
年龄对于聚类类别呈现出0.05水平显著性(chi=14.335, p=0.026<0.05),通过百分比对比差异可知,26-30岁选择品牌发烧友的比例49.21%,会明显高于平均水平42.50%。20-25岁选择品牌从众者的比例26.23%,会明显高于平均水平14.50%。36-40岁选择品牌冷淡者的比例53.33%,会明显高于平均水平43.00%。31-35岁选择品牌冷淡者的比例49.18%,会明显高于平均水平43.00%。可以根据数据结果进一步决策。也可以和“性别”、“学历”等进行交叉分析。这里不进行过多描述。
五、其它
1.聚类中心
整体说明聚类效果较好
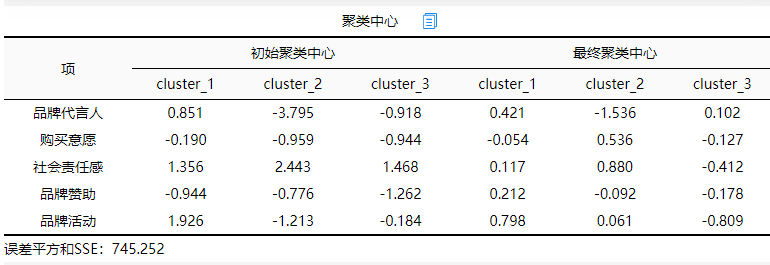
上表为经过迭代后类中心的变化,数据是经过标准化后的,至于数据是否需要标准化,聚类算法是根据距离进行判断类别,因此一般需要在聚类之前进行标准化处理,SPSSAU默认是选中进行标准化处理。数据标准化之后,数据的相对大小意义还在(比如数字越大GDP越高),但是实际意义消失了。
2.SSE
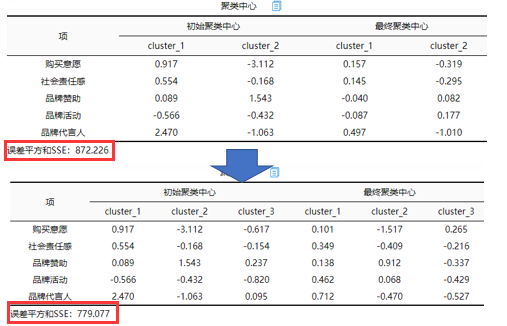
对于聚类中心的SSE指标说明如下:
在进行Kmeans聚类分析时SPSSAU默认输出误差平方和SSE值,该值可用于测量各点与中心点的距离情况,理论上是希望越小越好,而且如果同样的数据,聚类类别越多则SSE值会越小(但聚类类别过多则不便于分析)。SSE指标可用于辅助判断聚类类别个数,建议在不同聚类类别数量情况下记录下SSE值,然后分析SSE值的减少幅度情况,如果发现比如从2个聚类到3个6类别时SSE值减少幅度明显很大,那么此时选择3个聚类类别较好。比如该案例若聚类数为2,此时SSE值为872.226,但是当聚类数为3时此时SSE值为779.077,发现SSE减少幅度较大。所以可以看出选择3个聚类类别较好。
六、总结
本篇案例结合了线性回归与聚类分析,由于分析项过多,先进行因子分析,通过因子分析发现存在“张冠李戴”的情况,需要调整因子,调整因子后分析因子提取、信息浓缩情况,并且得到因子得分,进一步进行聚类分析,发现初步结果较好,将结果进行图示化展示,可以看出各个类别之间有明显的区别,将类别命名后,进行交叉分析,发现类别与年龄之间存在差异,并且具体描述,对公司或者平台对后续决策中提供有效结论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号