条件Logistic回归案例说明
在医学研究中,为了控制一些重要的混杂因素,经常会把病例和对照按年龄,性别等条件进行配对,形成多个匹配组。各匹配组的病例数和对照人数是任意的,比如一个病例和若干个对照匹配即1:1,在医学上称作“1:1病历对照研究”,常见还有1:M(M <=3),即1个病例和1或2或3个对照匹配。
病历对照研究或者倾向得分匹配研究(一种将研究数据处理成‘随机对照实验数据’的方法)中常使用条件Logistic回归进行分析。其与普通的二元logistic回归区别在于,多出配对ID,即将配对组纳入考虑范畴。
1、案例背景
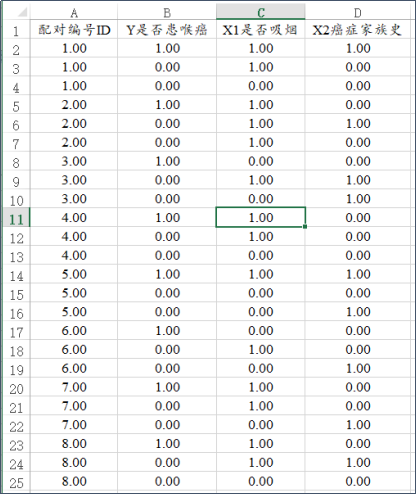
某北方城市研究喉癌发病的危险因素,使用1:2匹配的病例对照研究方法进行调查。共有25对配对数据(每对3个,即25*3=75行数据)。现研究两个影响因素分别是:是否吸烟和是否有癌症家族史。数据格式(部分)如下表:
提示:
条件logistic回归时,数据中一定需要记录配对编号,比如1:2的配对(1个病例配对2个对照,且共有20个组,组别编号从1到20,那么同时会有3个1,3个2,3个3,类似下去),而且在分析时将配对编号放入对应框中。
配对编号ID:共有25对配对,编号从1~25,每个数字会重复3次(分别对应病例或对照组);
Y是否患喉癌:数字1表示病例组即患喉癌,数字0表示对照组即没有患喉癌;
X1是否吸烟:数字1表示吸烟,数字0表示不吸烟;
X2癌症家族史:数字1表示有家族患喉癌史,数字0表示没有家族患喉癌史。
在做条件logistic回归时,因变量只能为0和1二分类数据。数字中只能包括0和1,如果不是,可使用[数据处理]->[数据编码]进行设置。
2、操作
本例子操作截图如下:
3、结果分析
SPSSAU共输出三个表格,分别是:“条件logit回归模型似然比检验结果”,“条件logit回归模型分析结果汇总”,“条件logit回归模型分析结果汇总”。
① 第一个表格:条件logit回归模型似然比检验结果
模型似然比检验,用于分析模型是否有效;

在分析上,首先需要模型通过似然比检验,其原定假设为不加入X和加入X模型无明显差异,如果对应的p值小于0.05,意味着拒绝原假设,也即说明模型有意义。
从上表可知:此处模型检验的原定假设为:是否放入自变量(X1是否吸烟, X2癌症家族史)两种情况时模型质量均一样;从上表可知,模型拒绝原定假设(chi=6.319,p=0.042 <0.05),即说明本次构建模型时,放入的自变量具有有效性,本次模型构建有意义。
② 第二个表格:条件logit回归模型分析结果汇总
包括模型的回归系数,R方值等数据;
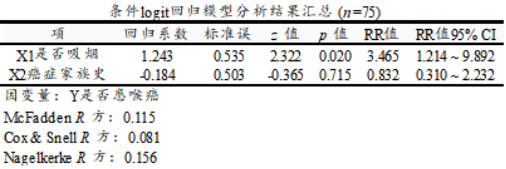
从上表可知:模型McFadden R方值为0.115,意味着是否吸烟, 癌症家族史共2项可解释是否患喉癌的11.5%原因。
具体来看:X1是否吸烟的回归系数值为1.243,并且呈现出0.05水平的显著性(z=2.322,p=0.020 <0.05),意味着X1是否吸烟会对Y是否患喉癌产生显著的正向影响关系。以及 (RR值,exp(b)值)为3.465(95% CI:1.214~9.892),意味着相对不吸烟群体,吸烟群体患喉癌的风险倍数会加大3.465倍。
X2癌症家族史的回归系数值为-0.184,但是并没有呈现出显著性(z=-0.365,p=0.715>0.05),意味着是否有癌症家族史并不会对患喉癌产生影响。
4、总结
分析过程涉及以下几个关键点:
(1)条件logistic回归时,数据中一定需要记录下配对编号,比如1:2的配对(1个病例配对2个对照,且共有20个组,组别编号从1到20,那么同时会有3个1,3个2,3个3,类似下去),而且在分析时将配对编号放入对应框中。
(2)条件logistic回归时,因变量只能为0和1二分类数据,数字中只能包括0和1,如果不是,可使用数据处理->数据编码进行设置。
「更多内容登录SPSSAU官网了解」

 浙公网安备 33010602011771号
浙公网安备 33010602011771号