SPSSAU数据分析思维培养系列2:分析方法
大家好!在上篇文章中,我们一起学习了如何掌握正确的数据处理思维(文章链接:https://www.cnblogs.com/spssau/p/12523530.html)。在完成数据准备和清理工作后,就要进入到正式分析阶段,而选择什么样的数据分析方法进行分析是关键。
想要进行科学和系统化的数据分析,分析方法的思维是必备项。
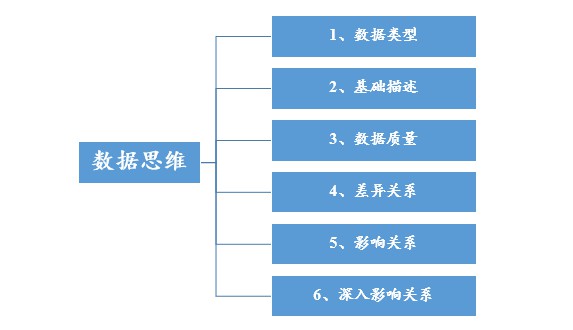
本文为SPSSAU数据分析思维培养的第2篇文章,将分别从数据类型谈起,剖析数据应该如何分析,包括数据的基础描述,数据质量的判断。除此之外,还进行差异关系,影响关系涉及的分析方法解析,最后针对更深入的影响关系进行说明。
希望通过本文帮助大家更快地掌握数学分析的思维,使用正确和科学的分析方法,完成科学的研究报告。
第1点,数据类型
进行数据分析的第一个思维,数据类型的识别。数据一般分成两类,定类和定量,如下:
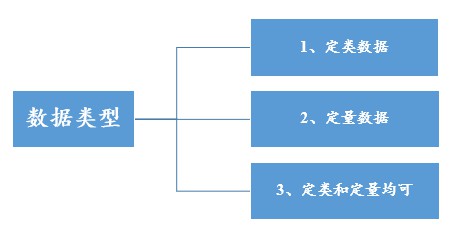
如果数据是类别,比如性别,或者医学上的阳性阴性,数字1表示男2表示女;也或者数字1表示阳性0表示阴性。数字的大小是不能进行PK对比,而只能代表类别,此类数据SPSSAU称为‘定类数据’(也称分类数据,定性数据等)。还有一类数据比如身高体重年龄,数字的大小具有实际意义可以对比大小,数字越大身高越高,体重越重,年龄越大,此类数据SPSSAU称为‘定量数据’(也称连续数据)。
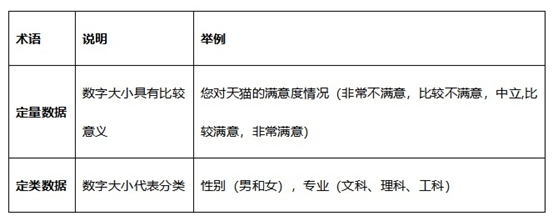
还有一种数据即像定类数据,也像定量数据。比如学历分成4组,分别是大专以下,大专,本科,本科以上,分别使用数字1,2,3,4标识。我们可以把其看成是四个类别,也可以看成是数字越大学历越高。针对此种数据在具体分析的时候需要看实际情况,一般来说把它看成定类数据更方便分析,那就看成是定类数据;如果把它看成定量数据更方便,那就看成是定量数据。
定类和定量数据的最大区别在于:定类数据一般是看频数百分比,定量数据一般是看平均值;而且分析上定类数据一般只能看差异性,定量数据一般是看影响关系。接下来的内容中会更加理解这种思维上的区别。
第2点,基础描述
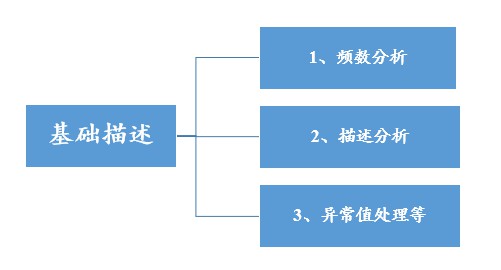
上述第1点已经说明了数据类型的鉴别方法,那么针对定类数据来讲,一般就是使用频数分析,查看选择频数和百分比;如果是定量数据一般就使用描述分析,查看平均值和中位数等。此两项分析均可在SPSSAU通用方法里面轻松地找到。

频数、描述分析-SPSSAU
得到一份数据后,通常第一步就是查看数据情况,分别对定类和定量数据做下简要的分析,以便对于数据基本特征有个大概的了解,同时可查到数据是否具有异常值情况等。比如对身高做描述分析发现最小值为负数。
如果数据中有发现异常值,此时需要及时的进行处理,如果有异常数据但没有处理,这种情况会导致后续的分析完全无用,因为异常数据对于分析的影响巨大。SPSSAU数据处理里面有异常值功能,同时生成变量也提供比如Winsor处理等。
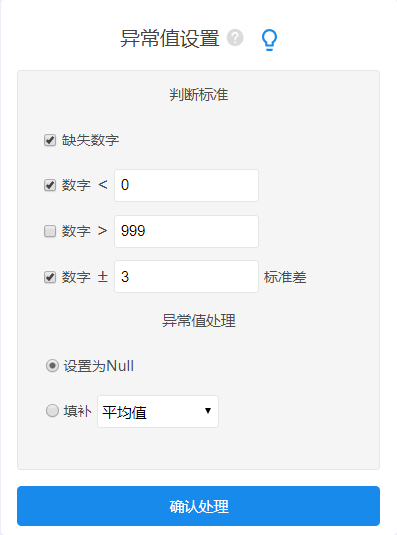
异常值处理-SPSSAU
第3点,数据质量
除了对数据基础情况有所了解外,还需要分析下数据的质量情况,如果数据中有量表,那么信度分析和效度分析最好不过。效度分析时可使用EFA和CFA,即探索性因子和验证性因子分析方法进行。信度或者效度分析等都是针对量表问卷一类的数据。

信度、效度分析-SPSSAU
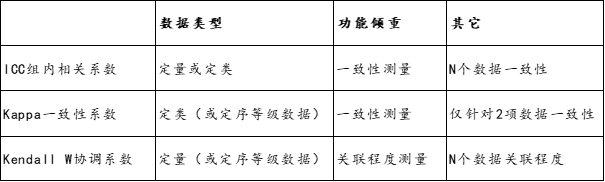
如果是实验数据,也或者专家打分数据等,此类数据不能做问卷式的信度和效度分析,但是可用于评定数据的一致性情况等,当然也是用于验证数据的有效可靠性等。此时可使用相关的方法比如ICC组内相关系数,Kappa系数,Kendall系数,也或者使用相关系数方法等,具体一致性检验方法的区别和使用情况,建议查看SPSSAU手册,医学/实验研究方法里面均有提供对应的研究方法。
第4点,差异关系
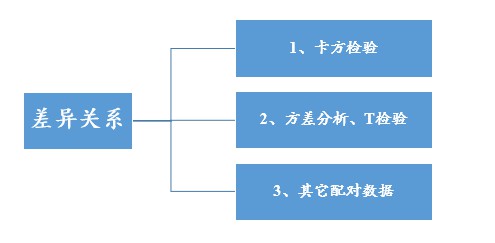
上述已经提及数据的类型,数据质量判断,当所有数据都准备完善,去除掉无效样本,异常值之后,数据质量也达标后。那么进入正式的分析就显得顺其自然。什么是差异关系呢,接下来举例说明:
|
举例 |
解析 |
方法 |
|
性别分布是否有差异? |
1个定类数据差异性。 |
卡方拟合优度检验 |
|
性别和是否吸烟的差异? |
2个定类数据差异性。 |
卡方检验 |
|
体重是否明显等于1.8米? |
1个定量数据差异性。 |
单样本T检验/单样本Wilcoxon检验 |
|
不同性别的体重是否有差异? |
1个定类和1个定量差异性。 |
方差分析/T检验/非参数检验 |
|
配对实验数据等 |
|
配对卡方、配对T检验、配对Wilcoxon检验 |
如果是定类数据的差异性,那么可使用卡方拟合优度检验。比如想研究阳性和阴性这两个组别的样本比例是否有差异性。如果是研究2个定类数据的差异性,则需要使用卡方检验,SPSSAU有两个按钮均可进行卡方检验,包括通用方法里面的交叉卡方和医学研究里面的卡方检验,区别在于后者可提供更多深入指标以及支持加权数据格式。
如果是定量数据的差异性,比如想研究样本群体平均身高是否等于1.8,一般是使用单样本T检验,但如果身高数据并不符合正态性时,此时可使用单样本Wilcoxon检验。
如果是研究定类和定量数据的差异性,比如想研究不同性别群体的体重上是否有明显的差异性,那么方差分析或T检验均可,区别在于方差可对比多重(比如东北、西南、东南三个地区的差异),而T检验只对比两组(比如男和女)的差异性。除此之外,如果这里体重这个数据严重的不正态时,最好使用非参数检验进行,SPSSAU通用方法里面有提供此方法。
如果是配对实验数据,比如实验前患病状态(阳性和阴性),与实验后患病状态(阳性和阴性)的差异对比,明显的是实验数据且为定类数据差异对比,此时需要使用配对卡方。如果是实验前成绩和实验后成绩的对比,那么是实验数据且定量数据差异对比,此时使用配对T检验较多,当然如果说成绩这个定量数据严重的不正态,此时使用配对Wilcoxon检验也许更优。
特别提示一点,实验数据是指‘实验前和实验后’,也或者‘同一个样本分别测量两次’这种情况。常见的实验组和对照组数据并不是绝对的实验数据,对比差异时一般是使用普通的T检验,而不是配对T检验。
除此之外,有时候实验数据的对比,比如同一个病例进行3次测量,测量1、测量2、测量3的对比差异性,此时可使用比如Friedman检验等。
关于差异关系的方法区别可查看SPSSAU之前的文章:https://zhuanlan.zhihu.com/p/57756620
第5点,影响关系
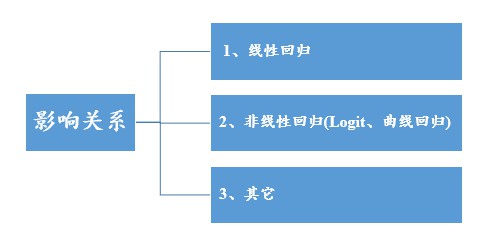
上述讲完差异关系,差异系数研究时,基本上都会有定类数据。因为定类数据是不同的类别,不同类别间只能说类别A和类别B是否有明显的不一样,也就是差异性。定量数据能说越怎么样越怎么样,比如身高越高体重越重。因此定量数据更容易进行影响关系,即带‘回归’二字的影响关系研究。
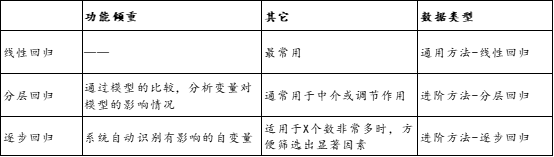
影响关系是研究X影响Y;如果Y是定量数据,那么一般是使用线性回归;线性回归的使用频率最高而且深入最高,其延迟出来还有比如分层线性回归、逐步回归等等,其实质上就是线性回归,只是另外一种变形(为了解决特定问题而产生)而已。
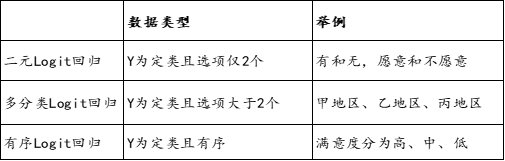
如果Y是定类数据,那么就应该使用Logit回归等。Logit回归还可分为3类,如果Y是二分类(比如是和否),那么就叫二元Logit回归;如果Y是多个类别,那么就叫多分类Logit回归。如果说Y是定类数据(但同时又可看成是定量数据),那么可使用有序多分类Logit回归。
除此之外,如果研究的回归影响关系是曲线的,比如二次曲线,三次曲线等,那么就可以使用曲线回归。
针对X对于Y的研究上,一般情况下是多个X对于1个Y的影响;如果是研究多个X对于多个Y的影响,那么可选的方法包括PLS回归、典型相关等。
第6点,深入影响关系
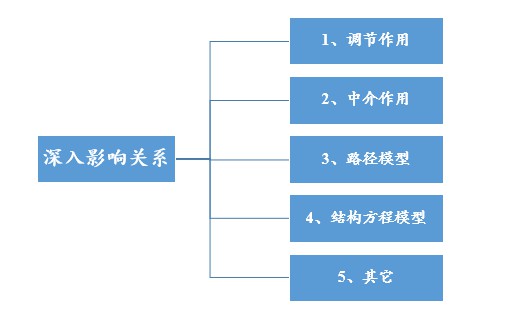
除上一部分的影响关系研究外,还有更深入的影响关系拓展。比如心理学、管理学上的调节作用或中介作用研究等,其实质上就是线性回归的升华和拓展,它们是分析方法的实质应用,比如调节作用和中介作用,一般就是使用分层线性回归进行验证。
当然当前还有更深入的研究,比如多个X和多个Y之间的影响关系情况研究,可使用路径模型,结构方程模型等进行深入分析。否则的话就需要重复进行多次线性回归分析。

路径分析、结构方程模型-SPSSAU
除此之外,当前还有一些更深入的影响关系研究,比如面板回归模型,岭回归等,其实质上依旧是影响关系研究。但区别在于比如面板回归模型,它是特定对于面板数据进行的回归影响关系研究。岭回归是特定解决数据的共线性问题共诞生的研究方法而已,全部在SPSSAU平台里面均能找到。
总结
数据分析思维的培训上,最关键的是数据类型的区别,接着针对数据的清理(即通过基础描述和数据质量的分析),并且区分数据类型后,采用差异研究和影响关系,也或者更深入的影响关系研究,最终为实际研究服务。
一文无法全部概括所有的研究,希望对数据分析思维有所引导。比如数据其实还有其它的研究,包括数据浓缩(主成分或因子分析)、数据聚类(Kmeans聚类、分层聚类)等等,在后续的文章中均会单独进行说明。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号