Exercise : Self-Taught Learning
First, you will train your sparse autoencoder on an "unlabeled" training dataset of handwritten digits. This produces feature that are penstroke-like. We then extract these learned features from a labeled dataset of handwritten digits. These features will then be used as inputs to the softmax classifier that you wrote in the previous exercise.
Concretely, for each example in the the labeled training dataset 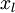 , we forward propagate the example to obtain the activation of the hidden units
, we forward propagate the example to obtain the activation of the hidden units  . We now represent this example using (the "replacement" representation), and use this to as the new feature representation with which to train the softmax classifier.
. We now represent this example using (the "replacement" representation), and use this to as the new feature representation with which to train the softmax classifier.
Finally, we also extract the same features from the test data to obtain predictions.
In this exercise, our goal is to distinguish between the digits from 0 to 4. We will use the digits 5 to 9 as our "unlabeled" dataset with which to learn the features; we will then use a labeled dataset with the digits 0 to 4 with which to train the softmax classifier.
Step 1: Generate the input and test data sets
Step 2: Train the sparse autoencoder
use the unlabeled data (the digits from 5 to 9) to train a sparse autoencoder
When training is complete, you should get a visualization of pen strokes like the image shown below:
Informally, the features learned by the sparse autoencoder should correspond to penstrokes.

Step 3: Extracting features
After the sparse autoencoder is trained, you will use it to extract features from the handwritten digit images.
Step 4: Training and testing the logistic regression model
Use your code from the softmax exercise (softmaxTrain.m) to train a softmax classifier using the training set features (trainFeatures) and labels (trainLabels).
Step 5: Classifying on the test set
Finally, complete the code to make predictions on the test set (testFeatures) and see how your learned features perform! If you've done all the steps correctly, you should get an accuracy of about 98% percent.
code
%% CS294A/CS294W Self-taught Learning Exercise % Instructions % ------------ % % This file contains code that helps you get started on the % self-taught learning. You will need to complete code in feedForwardAutoencoder.m % You will also need to have implemented sparseAutoencoderCost.m and % softmaxCost.m from previous exercises. % %% ====================================================================== % STEP 0: Here we provide the relevant parameters values that will % allow your sparse autoencoder to get good filters; you do not need to % change the parameters below. inputSize = 28 * 28; numLabels = 5; hiddenSize = 200; sparsityParam = 0.1; % desired average activation of the hidden units. % (This was denoted by the Greek alphabet rho, which looks like a lower-case "p", % in the lecture notes). lambda = 3e-3; % weight decay parameter beta = 3; % weight of sparsity penalty term maxIter = 400; %% ====================================================================== % STEP 1: Load data from the MNIST database % % This loads our training and test data from the MNIST database files. % We have sorted the data for you in this so that you will not have to % change it. % Load MNIST database files mnistData = loadMNISTImages('train-images.idx3-ubyte'); mnistLabels = loadMNISTLabels('train-labels.idx1-ubyte'); % Set Unlabeled Set (All Images) % Simulate a Labeled and Unlabeled set labeledSet = find(mnistLabels >= 0 & mnistLabels <= 4); unlabeledSet = find(mnistLabels >= 5); %%增加的一行代码 unlabeledSet = unlabeledSet(1:end/3); numTest = round(numel(labeledSet)/2);%拿一半的样本来训练% numTrain = round(numel(labeledSet)/3); trainSet = labeledSet(1:numTrain); testSet = labeledSet(numTrain+1:2*numTrain); unlabeledData = mnistData(:, unlabeledSet);%%为什么这两句连在一起都要出错呢? % pack; trainData = mnistData(:, trainSet); trainLabels = mnistLabels(trainSet)' + 1; % Shift Labels to the Range 1-5 % mnistData2 = mnistData; testData = mnistData(:, testSet); testLabels = mnistLabels(testSet)' + 1; % Shift Labels to the Range 1-5 % Output Some Statistics fprintf('# examples in unlabeled set: %d\n', size(unlabeledData, 2)); fprintf('# examples in supervised training set: %d\n\n', size(trainData, 2)); fprintf('# examples in supervised testing set: %d\n\n', size(testData, 2)); %% ====================================================================== % STEP 2: Train the sparse autoencoder % This trains the sparse autoencoder on the unlabeled training % images. % Randomly initialize the parameters theta = initializeParameters(hiddenSize, inputSize); %% ----------------- YOUR CODE HERE ---------------------- % Find opttheta by running the sparse autoencoder on % unlabeledTrainingImages opttheta = theta; addpath minFunc/ options.Method = 'lbfgs'; options.maxIter = 400; options.display = 'on'; [opttheta, loss] = minFunc( @(p) sparseAutoencoderLoss(p, ... inputSize, hiddenSize, ... lambda, sparsityParam, ... beta, unlabeledData), ... theta, options); %% ----------------------------------------------------- % Visualize weights W1 = reshape(opttheta(1:hiddenSize * inputSize), hiddenSize, inputSize); display_network(W1'); %%====================================================================== %% STEP 3: Extract Features from the Supervised Dataset % % You need to complete the code in feedForwardAutoencoder.m so that the % following command will extract features from the data. trainFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ... trainData); testFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ... testData); %%====================================================================== %% STEP 4: Train the softmax classifier softmaxModel = struct; %% ----------------- YOUR CODE HERE ---------------------- % Use softmaxTrain.m from the previous exercise to train a multi-class % classifier. % Use lambda = 1e-4 for the weight regularization for softmax lambda = 1e-4; inputSize = hiddenSize; numClasses = numel(unique(trainLabels));%unique为找出向量中的非重复元素并进行排序 % You need to compute softmaxModel using softmaxTrain on trainFeatures and % trainLabels % You need to compute softmaxModel using softmaxTrain on trainFeatures and % trainLabels options.maxIter = 100; softmaxModel = softmaxTrain(inputSize, numClasses, lambda, ... trainFeatures, trainLabels, options); %% ----------------------------------------------------- %%====================================================================== %% STEP 5: Testing %% ----------------- YOUR CODE HERE ---------------------- % Compute Predictions on the test set (testFeatures) using softmaxPredict % and softmaxModel [pred] = softmaxPredict(softmaxModel, testFeatures); %% ----------------------------------------------------- % Classification Score fprintf('Test Accuracy: %f%%\n', 100*mean(pred(:) == testLabels(:))); % (note that we shift the labels by 1, so that digit 0 now corresponds to % label 1) % % Accuracy is the proportion of correctly classified images % The results for our implementation was: % % Accuracy: 98.3% % %
function [activation] = feedForwardAutoencoder(theta, hiddenSize, visibleSize, data) % theta: trained weights from the autoencoder % visibleSize: the number of input units (probably 64) % hiddenSize: the number of hidden units (probably 25) % data: Our matrix containing the training data as columns. So, data(:,i) is the i-th training example. % We first convert theta to the (W1, W2, b1, b2) matrix/vector format, so that this % follows the notation convention of the lecture notes. W1 = reshape(theta(1:hiddenSize*visibleSize), hiddenSize, visibleSize); b1 = theta(2*hiddenSize*visibleSize+1:2*hiddenSize*visibleSize+hiddenSize); %% ---------- YOUR CODE HERE -------------------------------------- % Instructions: Compute the activation of the hidden layer for the Sparse Autoencoder. activation = sigmoid(W1*data+repmat(b1,[1,size(data,2)])); %------------------------------------------------------------------- end %------------------------------------------------------------------- % Here's an implementation of the sigmoid function, which you may find useful % in your computation of the costs and the gradients. This inputs a (row or % column) vector (say (z1, z2, z3)) and returns (f(z1), f(z2), f(z3)). function sigm = sigmoid(x) sigm = 1 ./ (1 + exp(-x)); end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号