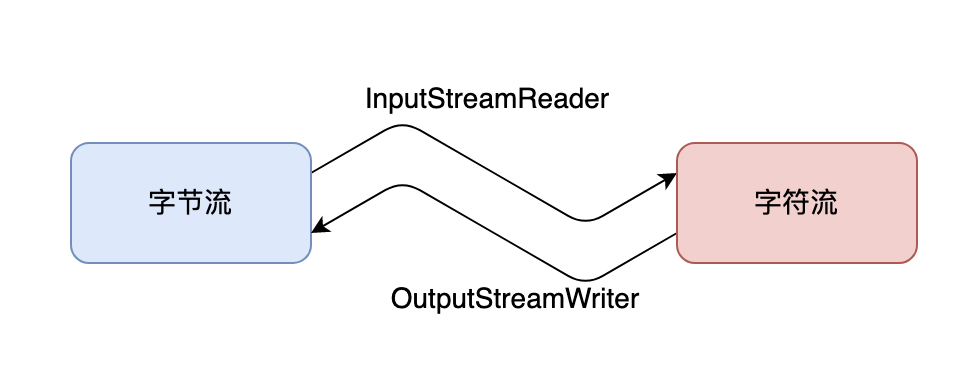
转换流
转换流主要有两种类型:InputStreamReader 和 OutputStreamWriter。
InputStreamReader 将一个字节输入流转换为一个字符输入流,而 OutputStreamWriter 将一个字节输出流转换为一个字符输出流。它们使用指定的字符集将字节流和字符流之间进行转换。常用的字符集包括 UTF-8、GBK、ISO-8859-1 等。
编码和解码
在计算机中,数据通常以二进制形式存储和传输。
- 编码就是将原始数据(比如说文本、图像、视频、音频等)转换为二进制形式。
- 解码就是将二进制数据转换为原始数据,是一个反向的过程。
常见的编码和解码方式有很多,举几个例子:
- ASCII 编码和解码:在计算机中,常常使用 ASCII 码来表示字符,如键盘上的字母、数字和符号等。例如,字母 A 对应的 ASCII 码是 65,字符 + 对应的 ASCII 码是 43。
- Unicode 编码和解码:Unicode 是一种字符集,支持多种语言和字符集。在计算机中,Unicode 可以使用 UTF-8、UTF-16 等编码方式将字符转换为二进制数据进行存储和传输。
- Base64 编码和解码:Base64 是一种将二进制数据转换为 ASCII 码的编码方式。它将 3 个字节的二进制数据转换为 4 个 ASCII 字符,以便在网络传输中使用。例如,将字符串 "Hello, world!" 进行 Base64 编码后,得到的结果是 "SGVsbG8sIHdvcmxkIQ=="。
- 图像编码和解码:在图像处理中,常常使用 JPEG、PNG、GIF 等编码方式将图像转换为二进制数据进行存储和传输。在解码时,可以将二进制数据转换为图像,以便显示或处理。
- 视频编码和解码:在视频处理中,常常使用 H.264、AVC、MPEG-4 等编码方式将视频转换为二进制数据进行存储和传输。在解码时,可以将二进制数据转换为视频,以便播放或处理。
字符集
Charset:字符集,是一组字符的集合,每个字符都有一个唯一的编码值,也称为码点。
常见的字符集包括 ASCII、Unicode 和 GBK,而 Unicode 字符集包含了多种编码方式,比如说 UTF-8、UTF-16。
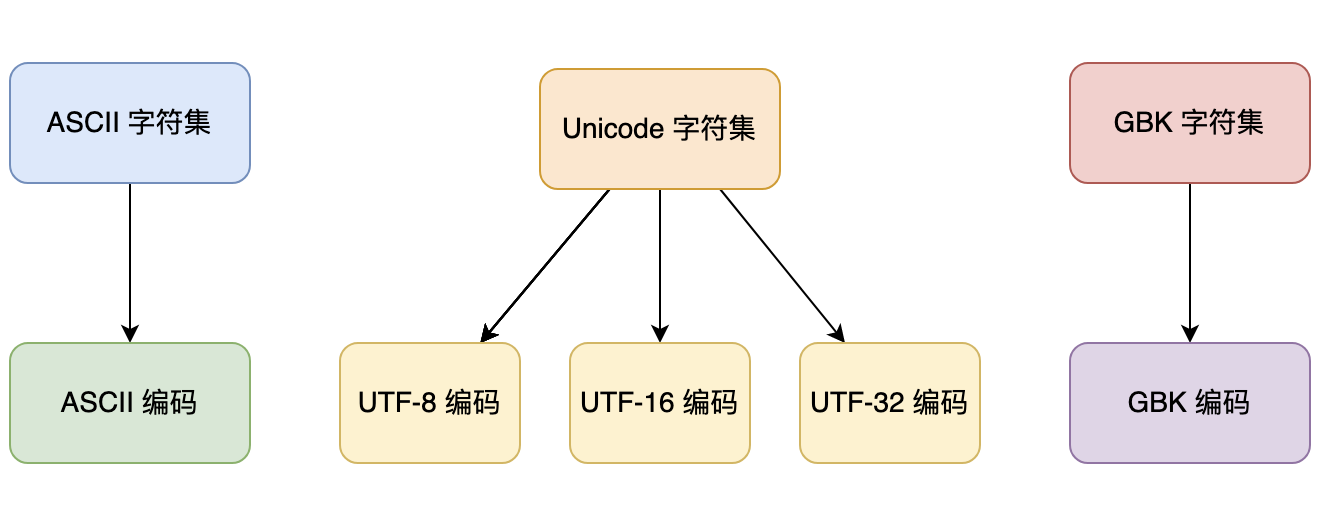
ASCII 字符集
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)字符集是一种最早的字符集,包含 128 个字符,其中包括控制字符、数字、英文字母以及一些标点符号。ASCII 字符集中的每个字符都有一个唯一的 7 位二进制编码(由 0 和 1 组成),可以表示为十进制数或十六进制数。
ASCII 编码方式是一种固定长度的编码方式,每个字符都使用 7 位二进制编码来表示。ASCII 编码只能表示英文字母、数字和少量的符号,不能表示其他语言的文字和符号,因此在全球范围内的应用受到了很大的限制
Unicode 字符集
Unicode 包含了世界上几乎所有的字符,用于表示人类语言、符号和表情等各种信息。Unicode 字符集中的每个字符都有一个唯一的码点(code point),用于表示该字符在字符集中的位置,可以用十六进制数表示。
为了在计算机中存储和传输 Unicode 字符集中的字符,需要使用一种编码方式。UTF-8、UTF-16 和 UTF-32 都是 Unicode 字符集的编码方式,用于将 Unicode 字符集中的字符转换成字节序列,以便于存储和传输。它们的差别在于使用的字节长度不同。
- UTF-8 是一种可变长度的编码方式,对于 ASCII 字符(码点范围为
0x00~0x7F),使用一个字节表示,对于其他 Unicode 字符,使用两个、三个或四个字节表示。UTF-8 编码方式被广泛应用于互联网和计算机领域,因为它可以有效地压缩数据,适用于网络传输和存储。 - UTF-16 是一种固定长度的编码方式,对于基本多语言平面(Basic Multilingual Plane,Unicode 字符集中的一个码位范围,包含了世界上大部分常用的字符,总共包含了超过 65,000 个码位)中的字符(码点范围为
0x0000~0xFFFF),使用两个字节表示,对于其他 Unicode 字符,使用四个字节表示。 - UTF-32 是一种固定长度的编码方式,对于所有 Unicode 字符,使用四个字节表示。
GBK 字符集
GBK 包含了 GB2312 字符集中的字符,同时还扩展了许多其他汉字字符和符号,共收录了 21,913 个字符。GBK 采用双字节编码方式,每个汉字占用 2 个字节,其中高字节和低字节都使用了 8 位,因此 GBK 编码共有 2^16=65536 种可能的编码,其中大部分被用于表示汉字字符。
GBK 编码是一种变长的编码方式,对于 ASCII 字符(码位范围为 0x00 到 0x7F),使用一个字节表示,对于其他字符,使用两个字节表示。GBK 编码中的每个字节都可以采用 0x81 到 0xFE 之间的任意一个值,因此可以表示 2^15=32768 个字符。为了避免与 ASCII 码冲突,GBK 编码的第一个字节采用了 0x81 到 0xFE 之间除了 0x7F 的所有值,第二个字节采用了 0x40 到 0x7E 和 0x80 到 0xFE 之间的所有值,共 94 个值。
GB2312 的全名是《信息交换用汉字编码字符集基本集》,也被称为“国标码”。采用了双字节编码方式,每个汉字占用 2 个字节,其中高字节和低字节都使用了 8 位,因此 GB2312 编码共有 2^16=65536 种可能的编码,其中大部分被用于表示汉字字符。GB2312 编码中的每个字节都可以采用 0xA1 到 0xF7 之间的任意一个值,因此可以表示 126 个字符。
GB2312 是一个较为简单的字符集,只包含了常用的汉字和符号,因此对于一些较为罕见的汉字和生僻字,GB2312 不能满足需求,现在已经逐渐被 GBK、GB18030 等字符集所取代。
GB18030 是最新的中文码表。收录汉字 70244 个,采用多字节编码,每个字可以由 1 个、2 个或 4 个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
InputStreamReader
构造方法
InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。InputStreamReader(InputStream in, String charsetName): 创建一个指定字符集的字符流
InputStreamReader isr = new InputStreamReader(new FileInputStream("in.txt"));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("in.txt") , "GBK");
解决编码问题
String s = "hh";
try {
// 将字符串按GBK编码方式保存到文件中
OutputStreamWriter outUtf8 = new OutputStreamWriter(
new FileOutputStream("logs/test_utf8.txt"), "GBK");
outUtf8.write(s);
outUtf8.close();
// 将字节流转换为字符流,使用GBK编码方式
InputStreamReader isr = new InputStreamReader(new FileInputStream("logs/test_utf8.txt"), "GBK");
// 读取字符流
int c;
while ((c = isr.read()) != -1) {
System.out.print((char) c);
}
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
OutputStreamWriter
java.io.OutputStreamWriter 是 Writer 的子类,字面看容易误以为是转为字符流,其实是将字符流转换为字节流,是字符流到字节流的桥梁。
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。OutputStreamWriter(OutputStream in, String charsetName):创建一个指定字符集的字符流。
OutputStreamWriter isr = new OutputStreamWriter(new FileOutputStream("a.txt"));
OutputStreamWriter isr2 = new OutputStreamWriter(new FileOutputStream("b.txt") , "GBK");
通常为了提高读写效率,我们会在转换流上再加一层缓冲流:
try {
// 从文件读取字节流,使用UTF-8编码方式
FileInputStream fis = new FileInputStream("test.txt");
// 将字节流转换为字符流,使用UTF-8编码方式
InputStreamReader isr = new InputStreamReader(fis, "UTF-8");
// 使用缓冲流包装字符流,提高读取效率
BufferedReader br = new BufferedReader(isr);
// 创建输出流,使用UTF-8编码方式
FileOutputStream fos = new FileOutputStream("output.txt");
// 将输出流包装为转换流,使用UTF-8编码方式
OutputStreamWriter osw = new OutputStreamWriter(fos, "UTF-8");
// 使用缓冲流包装转换流,提高写入效率
BufferedWriter bw = new BufferedWriter(osw);
// 读取输入文件的每一行,写入到输出文件中
String line;
while ((line = br.readLine()) != null) {
bw.write(line);
bw.newLine(); // 每行结束后写入一个换行符
}
// 关闭流
br.close();
bw.close();
} catch (IOException e) {
e.printStackTrace();
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号