Java IO模型
Java 的 IO 分为两大类,一类是传统的 IO(Blocking IO),一类是 NIO(New IO)。
传统的 IO 基于字节流和字符流,以阻塞式 IO 操作为主。常用的类有 FileInputStream、FileOutputStream、InputStreamReader、OutputStreamWriter 等。这些类在读写数据时,会导致执行线程阻塞,直到操作完成。
Java NIO 是 Java 1.4 版本引入的,基于通道(Channel)和缓冲区(Buffer)进行操作,采用非阻塞式 IO 操作,允许线程在等待 IO 时执行其他任务。常见的 NIO 类有 ByteBuffer、FileChannel、SocketChannel、ServerSocketChannel 等。
阻塞 IO 和非阻塞 IO
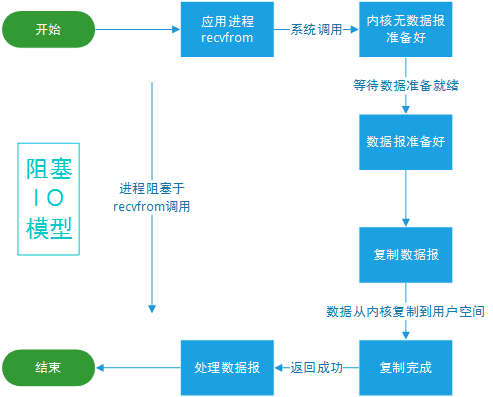
阻塞 I/O(Blocking I/O):在这种模型中,I/O 操作是阻塞的,即执行 I/O 操作时,线程会被阻塞,直到操作完成。在阻塞 I/O 模型中,每个连接都需要一个线程来处理。因此,对于大量并发连接的场景,阻塞 I/O 模型的性能较差。
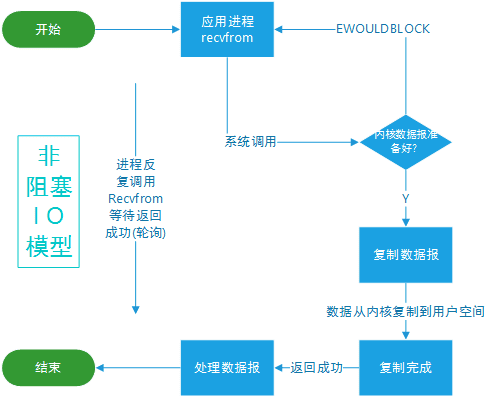
非阻塞 I/O(Non-blocking I/O):在这种模型中,I/O 操作不会阻塞线程。当数据尚未准备好时,I/O 调用会立即返回。线程可以继续执行其他任务,然后在适当的时候再次尝试执行 I/O 操作。非阻塞 I/O 模型允许单个线程同时处理多个连接,但可能需要在应用程序级别进行复杂的调度和管理。
内核空间和用户空间
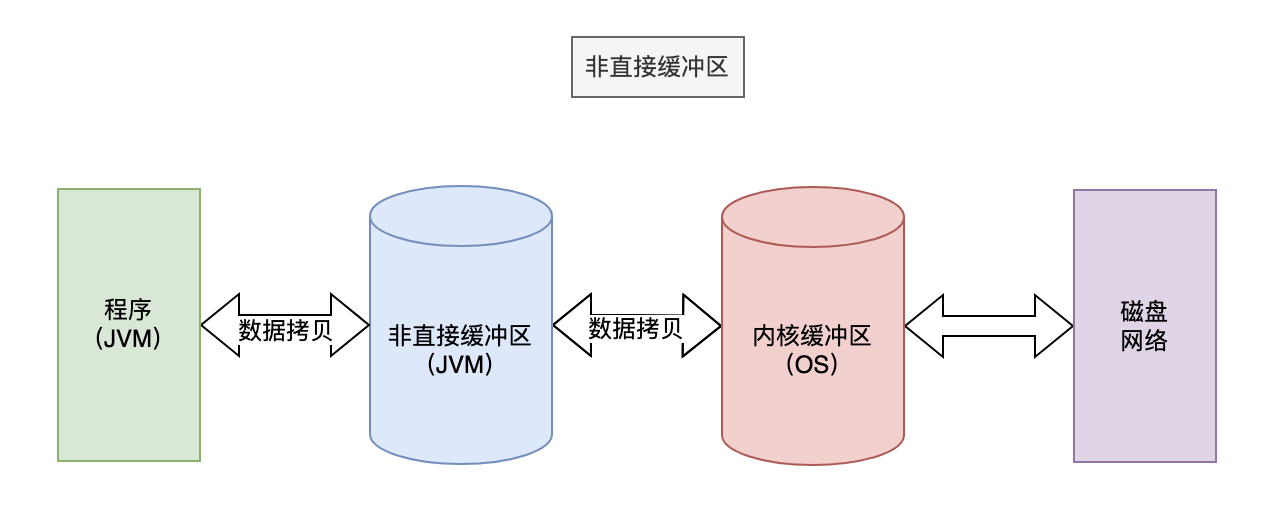
其中的非直接缓冲区(JVM)就是在用户空间中,内核缓冲区(OS)就是在内核空间上。
内核空间是操作系统内核的专用内存区域,用于存储内核代码、数据结构和运行内核级别的系统调用。内核空间具有较高的权限级别,能够直接访问硬件资源和底层系统服务。一般来说,内核空间是受到严格保护的,用户级别的程序不能直接访问内核空间,以确保操作系统的稳定性和安全性。
用户空间是为用户级别的应用程序和服务分配的内存区域。它包含了应用程序的代码、数据和运行时堆栈。用户空间与内核空间相对隔离,具有较低的权限级别,不能直接访问内核空间或硬件资源。应用程序需要通过系统调用与内核空间进行交互,请求操作系统提供的服务。
内核空间和用户空间的划分有助于操作系统实现内存保护和权限控制,确保系统运行的稳定性和安全性。当用户程序需要访问系统资源或执行特权操作时,它需要通过系统调用切换到内核空间,由内核代理执行相应的操作。这种设计可以防止恶意或错误的用户程序直接访问内核空间,从而破坏系统的稳定性和安全性。同时,这种划分也提高了操作系统的可扩展性,因为内核空间和用户空间可以独立地进行扩展和优化。
多路复用、信号驱动、异步 IO
除了前面提到的阻塞 IO 和非阻塞 IO 模型,还有另外三种 IO 模型,分别是多路复用、信号驱动和异步 IO。
多路复用
I/O 多路复用(I/O Multiplexing)模型使用操作系统提供的多路复用功能(如 select、poll、epoll 等),使得单个线程可以同时处理多个 I/O 事件。当某个连接上的数据准备好时,操作系统会通知应用程序。这样,应用程序可以在一个线程中处理多个并发连接,而不需要为每个连接创建一个线程。
select是 Unix 系统中最早的 I/O 多路复用技术。它允许一个线程同时监视多个文件描述符(如套接字),并等待某个文件描述符上的 I/O 事件(如可读、可写或异常)。select 的主要问题是性能受限,特别是在处理大量文件描述符时。这是因为它使用一个位掩码来表示文件描述符集,每次调用都需要传递这个掩码,并在内核和用户空间之间进行复制。poll是对 select 的改进。它使用一个文件描述符数组而不是位掩码来表示文件描述符集。这样可以避免 select 中的性能问题。然而,poll 仍然需要遍历整个文件描述符数组,以检查每个文件描述符的状态。因此,在处理大量文件描述符时,性能仍然受限。epoll是 Linux 中的一种高性能 I/O 多路复用技术。它通过在内核中维护一个事件表来避免遍历文件描述符数组的性能问题。当某个文件描述符上的 I/O 事件发生时,内核会将该事件添加到事件表中。应用程序可以使用 epoll_wait 函数来获取已准备好的 I/O 事件,而无需遍历整个文件描述符集。这种方法大大提高了在大量并发连接下的性能。
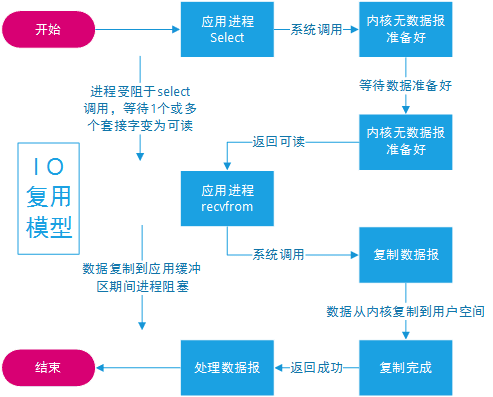
在 Java NIO 中,I/O 多路复用主要通过 Selector 类实现。Selector 能够监控多个 Channel(通道)上的 I/O 事件,如连接、读取和写入。这使得一个线程可以处理多个并发连接,提高了程序的性能和可伸缩性。
以下是 Java NIO 中 I/O 多路复用的应用:
①、首先,需要创建一个 Selector 对象。
Selector selector = Selector.open();
②、然后,需要将 Channel 注册到 Selector。每个 Channel 必须配置为非阻塞模式,才能与 Selector 一起使用。在注册 Channel 时,还需要指定感兴趣的 I/O 事件,如 SelectionKey.OP_ACCEPT(接受连接)、SelectionKey.OP_READ(读取数据)等。
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.configureBlocking(false);
serverChannel.bind(new InetSocketAddress(8080));
// 注册感兴趣的事件
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
③、接下来,使用 Selector 的 select() 方法等待 I/O 事件。select() 方法会阻塞,直到至少有一个 Channel 上的事件发生。当有事件发生时,可以通过调用 selectedKeys() 方法获取已准备好进行 I/O 操作的 Channel 的 SelectionKey 集合。
while (true) {
int readyChannels = selector.select();
if (readyChannels == 0) continue;
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// 处理接受连接事件
} else if (key.isReadable()) {
// 处理读取数据事件
} else if (key.isWritable()) {
// 处理写入数据事件
}
keyIterator.remove();
}
}
④、最后,根据 SelectionKey 的状态,执行相应的 I/O 操作。例如,如果 SelectionKey 表示 Channel 已准备好接受新的连接,可以调用 ServerSocketChannel 的 accept() 方法。如果 SelectionKey 表示 Channel 已准备好读取数据,可以从 SocketChannel 中读取数据。
if (key.isAcceptable()) {
SocketChannel socketChannel = serverSocketChannel.accept();
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ);
System.out.println("客户端连接上了: " + socketChannel.getRemoteAddress());
}
信号驱动
信号驱动 I/O(Signal-driven I/O)模型中,应用程序可以向操作系统注册一个信号处理函数,当某个 I/O 事件发生时,操作系统会发送一个信号通知应用程序。应用程序在收到信号后处理相应的 I/O 事件。这种模型与非阻塞 I/O 类似,也需要在应用程序级别进行事件管理和调度。
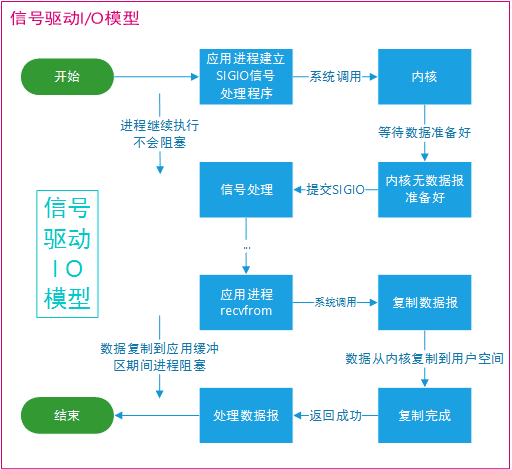
多路复用和信号驱动的差别主要在事件通知机制和引用场景上。
多路复用模型允许一个线程同时管理多个 I/O 连接。这是通过使用特殊的系统调用(如 select、poll 和 epoll)实现的,它们能够监视多个文件描述符上的 I/O 事件。当某个 I/O 事件发生时,这些系统调用会返回,通知应用程序执行相应的 I/O 操作。I/O 多路复用模型适用于高并发、低延迟和高吞吐量的场景,因为它能够有效地减少线程数量和上下文切换开销。
信号驱动模型依赖于信号(如 SIGIO)来通知应用程序 I/O 事件的发生。在这个模型中,应用程序首先设置文件描述符为信号驱动模式,并为相应的信号注册处理函数。当 I/O 事件发生时,内核会发送一个信号给应用程序,触发信号处理函数的执行。然后,应用程序可以在信号处理函数中执行相应的 I/O 操作。I/O 信号驱动模型适用于低并发、低延迟和低吞吐量的场景,因为它需要为每个 I/O 事件创建一个信号和信号处理函数。
Linux 的内核将所有外部设备都看做一个文件来操作,对一个文件的读写操作会调用内核提供的系统命令(api),返回一个 file descriptor(fd,文件描述符)。而对一个Socket的读写也会有响应的描述符,称为 socket fd(Socket文件描述符),描述符就是一个数字,指向内核中的一个结构体(文件路径,数据区等一些属性)。
在Linux下对文件的操作是利用文件描述符(file descriptor)来实现的。
异步 IO
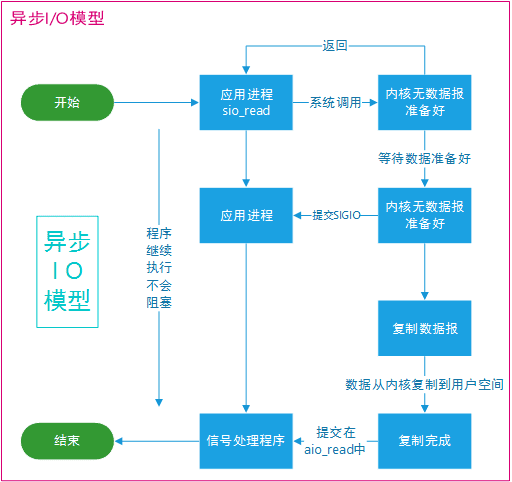
异步 I/O(Asynchronous I/O)模型与同步 I/O 模型的主要区别在于,异步 I/O 操作会在后台运行,当操作完成时,操作系统会通知应用程序。应用程序不需要等待 I/O 操作的完成,可以继续执行其他任务。这种模型适用于处理大量并发连接,且可以简化应用程序的设计和开发。
- 同步:在执行 I/O 操作时,应用程序需要等待操作的完成。同步操作会导致线程阻塞,直到操作完成。同步 I/O 包括阻塞 I/O、非阻塞 I/O 和 I/O 多路复用。
- 异步:在执行 I/O 操作时,应用程序不需要等待操作的完成。异步操作允许应用程序在 I/O 操作进行时继续执行其他任务。异步 I/O 模型包括信号驱动 I/O 和异步 I/O。
假设你现在是个大厨:
- 同步/阻塞:你站在锅边,一直等到汤炖好,期间不能做其他事情,直到汤炖好才去处理其他任务。
- 同步/非阻塞:你不断地查看锅里的汤,看是否炖好。在检查的间隙,你可以处理其他任务,如切菜。但你需要不断地切换任务,确保汤炖好了就可以处理。
- 异步/信号驱动:你给锅安装一个传感器,当汤炖好时,传感器会发出信号提醒你。在此期间,你可以处理其他任务,而不用担心错过汤炖好的时机。
- 异步 I/O:你请了一个助手,让他负责炖汤。当汤炖好时,助手会通知你。你可以专心处理其他任务,而无需关心炖汤的过程。
总结
IO 模型主要有五种:阻塞 I/O、非阻塞 I/O、多路复用、信号驱动和异步 I/O。
- 阻塞 I/O:应用程序执行 I/O 操作时,会一直等待数据传输完成,期间无法执行其他任务。
- 非阻塞 I/O:应用程序执行 I/O 操作时,如果数据未准备好,立即返回错误状态,不等待数据传输完成,可执行其他任务。
- 多路复用:允许一个线程同时管理多个 I/O 连接,适用于高并发、低延迟和高吞吐量场景,减少线程数量和上下文切换开销。
- 信号驱动:依赖信号通知应用程序 I/O 事件,适用于低并发、低延迟和低吞吐量场景,需要为每个 I/O 事件创建信号和信号处理函数。
- 异步 I/O:应用程序发起 I/O 操作后,内核负责数据传输过程,完成后通知应用程序。应用程序无需等待数据传输,可执行其他任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号