并发容器
Java 的并发集合容器提供了在多线程环境中高效访问和操作的数据结构。这些容器通过内部的同步机制实现了线程安全,使得开发者无需显式同步代码就能在并发环境下安全使用,比如说:ConcurrentHashMap、阻塞队列和 CopyOnWrite 容器等。
java.util 包下提供了一些容器类(集合框架),其中 Vector 和 Hashtable 是线程安全的,但实现方式比较粗暴,通过在方法上加 sychronized 关键字实现。
但即便是 Vector 这样线程安全的类,在应对多线程的复合操作时也需要在客户端继续加锁以保证原子性。
public class TestVector {
private Vector<String> vector;
//方法一
public Object getLast(Vector vector) {
int lastIndex = vector.size() - 1;
return vector.get(lastIndex);
}
//方法二
public void deleteLast(Vector vector) {
int lastIndex = vector.size() - 1;
vector.remove(lastIndex);
}
//方法三
public Object getLastSysnchronized(Vector vector) {
synchronized(vector){
int lastIndex = vector.size() - 1;
return vector.get(lastIndex);
}
}
//方法四
public void deleteLastSysnchronized(Vector vector) {
synchronized (vector){
int lastIndex = vector.size() - 1;
vector.remove(lastIndex);
}
}
}
如果方法一和方法二是一个组合的话,那么当方法一获取到了vector的 size 之后,方法二已经执行完毕,这样就会导致程序出现错误。
如果方法三与方法四组合的话,就还需在内部加锁来保证 vector 上的原子性操作。
于是并发容器就应用而生了,它们是线程安全的,可以在多线程环境下高效地访问和操作数据,而不需要额外的同步措施。
并发容器类
并发 Map
ConcurrentMap 接口
ConcurrentMap 接口继承了 Map 接口,在 Map 接口的基础上又定义了四个方法:
public interface ConcurrentMap<K, V> extends Map<K, V> {
// 插入元素:如果插入的 key 相同,则不替换原有的 value 值
V putIfAbsent(K key, V value);
// 移除元素:如果要删除的 key-value 不能与 Map 中原有的 key-value 对应上,则不会删除该元素
boolean remove(Object key, Object value);
// 替换元素:如果 key-oldValue 能与 Map 中原有的 key-value 对应上,才进行替换操作
boolean replace(K key, V oldValue, V newValue);
// 替换元素:不会对 Map 中原有的 key-value 进行比较,如果 key 存在则直接替换
V replace(K key, V value);
}
ConcurrentHashMap
ConcurrentHashMap 同 HashMap 一样,也是基于散列表的 map,但是它提供了一种与 Hashtable 完全不同的加锁策略,提供了更高效的并发性和伸缩性。
ConcurrentSkipListMap
ConcurrentNavigableMap 接口继承了 NavigableMap 接口,这个接口提供了针对给定搜索目标返回最接近匹配项的导航方法。
ConcurrentNavigableMap 接口的主要实现类是 ConcurrentSkipListMap 类。从名字上来看,它的底层使用的是跳表(SkipList)。跳表是一种”空间换时间“的数据结构,可以使用 CAS 来保证并发安全性。
与 ConcurrentHashMap 的读密集操作相比,ConcurrentSkipListMap 的读和写操作的性能相对较低。这是由其数据结构导致的,因为跳表的插入和删除需要更复杂的指针操作。然而,ConcurrentSkipListMap 提供了有序性,这是 ConcurrentHashMap 所没有的。
ConcurrentSkipListMap 适用于需要线程安全的同时又需要元素有序的场合。如果不需要有序,ConcurrentHashMap 可能是更好的选择,因为它通常具有更高的性能。
并发 Queue
JDK 并没有提供线程安全的 List 类,因为对 List 来说,很难去开发一个通用并且没有并发瓶颈的线程安全的 List。因为即使简单的读操作,比如 contains(),也需要再搜索的时候锁住整个 list。
所以退一步,JDK 提供了队列和双端队列的线程安全类:ConcurrentLinkedQueue 和 ConcurrentLinkedDeque。因为队列相对于 List 来说,有更多的限制。这两个类是使用 CAS 来实现线程安全的。
并发 Set
ConcurrentSkipListSet 是线程安全的有序集合。底层是使用 ConcurrentSkipListMap 来实现。
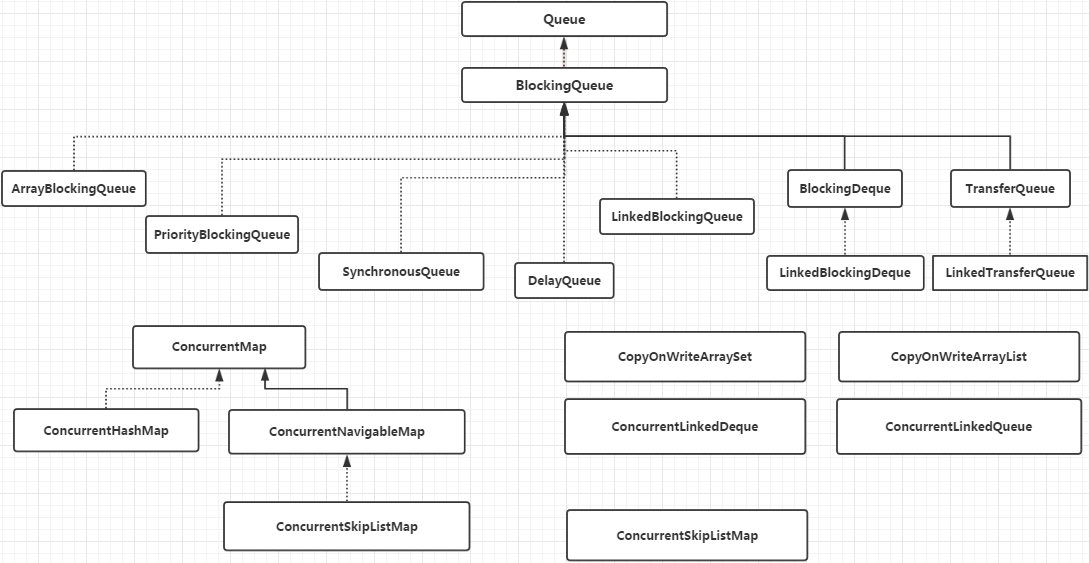
阻塞队列
我们假设一种场景,生产者一直生产资源,消费者一直消费资源,资源存储在一个缓冲池中,生产者将生产的资源存进缓冲池中,消费者从缓冲池中拿到资源进行消费,这就是大名鼎鼎的生产者-消费者模式。
该模式能够简化开发过程,一方面消除了生产者类与消费者类之间的代码依赖性,另一方面将生产数据的过程与使用数据的过程解耦简化负载。
自己 coding 实现这个模式的时候,因为需要让多个线程操作共享变量(即资源),所以很容易引发线程安全问题,造成重复消费和死锁,尤其是生产者和消费者存在多个的情况。另外,当缓冲池空了,我们需要阻塞消费者,唤醒生产者;当缓冲池满了,我们需要阻塞生产者,唤醒消费者,这些个等待-唤醒逻辑都需要自己实现。
BlockingQueue 一般用于生产者-消费者模式,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程,不用担心多线程环境下存、取共享变量的线程安全问题。BlockingQueue 就是存放元素的容器。
BlockingQueue 的操作方法
阻塞队列提供了四组不同的方法用于插入、移除、检查元素:
| 方法\处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove() | poll() | take() | poll(time,unit) |
| 检查方法 | element() | peek() | - | - |
- 抛出异常:如果操作无法立即执行,会抛异常。当阻塞队列满时候,再往队列里插入元素,会抛出
IllegalStateException(“Queue full”)异常。当队列为空时,从队列里获取元素时会抛出 NoSuchElementException 异常 。 - 返回特殊值:如果操作无法立即执行,会返回一个特殊值,通常是 true / false。
- 一直阻塞:如果操作无法立即执行,则一直阻塞或者响应中断。
- 超时退出:如果操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功,通常是 true / false。
注意:
- 不能往阻塞队列中插入 null,会抛出空指针异常。
- 可以访问阻塞队列中的任意元素,调用
remove(o)可以将队列之中的特定对象移除,但并不高效,尽量避免使用。
BlockingQueue 的实现类
ArrayBlockingQueue
由数组结构组成的有界阻塞队列。内部结构是数组,具有数组的特性。
public ArrayBlockingQueue(int capacity, boolean fair){
//..省略代码
}
可以初始化队列大小,一旦初始化将不能改变。构造方法中的 fair 表示控制对象的内部锁是否采用公平锁,默认是非公平锁。
LinkedBlockingQueue
由链表结构组成的有界阻塞队列。内部结构是链表,具有链表的特性。默认队列的大小是Integer.MAX_VALUE,也可以指定大小。此队列按照先进先出的原则对元素进行排序。
DelayQueue
该队列中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。注入其中的元素必须实现 java.util.concurrent.Delayed 接口。
DelayQueue 是一个没有大小限制的队列,因此往队列中插入数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞。
PriorityBlockingQueue
基于优先级的无界阻塞队列(优先级的判断通过构造函数传入的 Compator 对象来决定),内部控制线程同步的锁采用的是非公平锁。
public PriorityBlockingQueue(int initialCapacity,
Comparator<? super E> comparator) {
this.lock = new ReentrantLock(); //默认构造方法-非公平锁
...//其余代码略
}
SynchronousQueue
这个队列比较特殊,没有任何内部容量,甚至连一个队列的容量都没有。并且每个 put 必须等待一个 take,反之亦然。
需要区别容量为 1 的 ArrayBlockingQueue、LinkedBlockingQueue。
以下方法的返回值,可以帮助理解这个队列:
iterator()永远返回空,因为里面没有东西peek()永远返回 nullput()往 queue 放进去一个 element 以后就一直 wait 直到有其他 thread 进来把这个 element 取走。offer()往 queue 里放一个 element 后立即返回,如果碰巧这个 element 被另一个 thread 取走了,offer 方法返回 true,认为 offer 成功;否则返回 false。take()取出并且 remove 掉 queue 里的 element,取不到东西他会一直等。poll()取出并且 remove 掉 queue 里的 element,只有到碰巧另外一个线程正在往 queue 里 offer 数据或者 put 数据的时候,该方法才会取到东西。否则立即返回 null。isEmpty()永远返回 trueremove()&removeAll()永远返回 false
注意
PriorityBlockingQueue不会阻塞数据生产者(因为队列是无界的),而只会在没有可消费的数据时阻塞数据的消费者。因此使用的时候要特别注意,生产者生产数据的速度绝对不能快于消费者消费数据的速度,否则时间一长,会最终耗尽所有的可用堆内存空间。*对于使用默认大小的*LinkedBlockingQueue也是一样的。
CopyOnWrite容器
CopyOnWrite 是计算机设计领域的一种优化策略,也是一种在并发场景下常用的设计思想——写入时复制。
就是当有多个调用者同时去请求一个资源数据的时候,有一个调用者出于某些原因需要对当前的数据源进行修改,这个时候系统将会复制一个当前数据源的副本给调用者修改。
CopyOnWrite 容器即写时复制的容器,当我们往一个容器中添加元素的时候,不直接往容器中添加,而是将当前容器进行 copy,复制出来一个新的容器,然后向新容器中添加我们需要的元素,最后将原容器的引用指向新容器。
这样做的好处在于,我们可以在并发的场景下对容器进行"读操作"而不需要"加锁",从而达到读写分离的目的。从 JDK 1.5 开始 Java 并发包里提供了两个使用 CopyOnWrite 机制实现的并发容器,分别是 CopyOnWriteArrayList 和 CopyOnWriteArraySet(不常用)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号