SQL Server(00):技巧:删除表中的重复数据
create table Student( ID varchar(10) not null, Name varchar(10) not null, ); insert into Student values('1', 'zhangs'); insert into Student values('2', 'zhangs'); insert into Student values('3', 'lisi'); insert into Student values('4', 'lisi'); insert into Student values('5', 'wangwu');
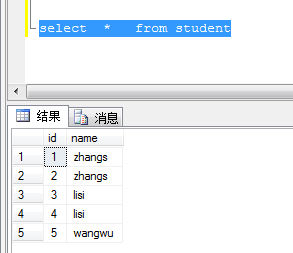
删除Name重复多余的行,每个Name仅保留1行数据
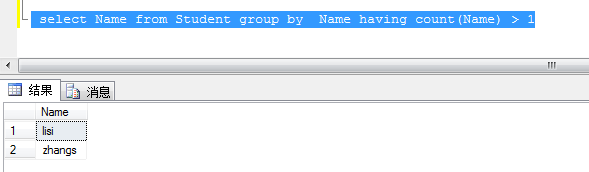
1、查询表中Name 重复的数据
select Name from Student group by Name having count(Name) > 1
2、有唯一列,通过唯一列最大或最小方式删除重复记录
检查表中是否有主键或者唯一值的列,当前可以数据看到ID是唯一的,可以通过Name分组排除掉ID最大或最小的行
delete from Student where Name in( select Name from Student group by Name having count(Name) > 1) and ID not in(select max(ID) from Student group by Name having count(Name) > 1 )
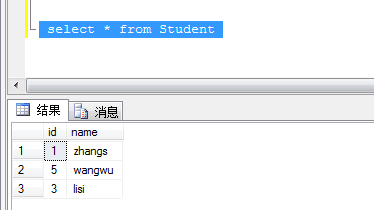
执行删除脚本后查询
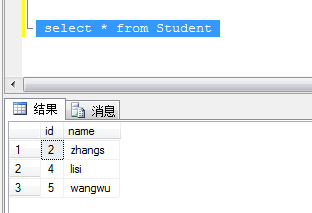
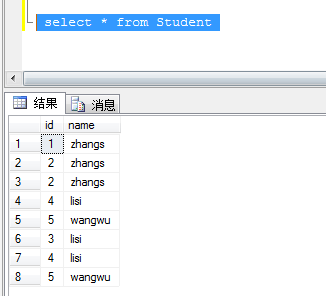
3、无唯一列使用ROW_NUMBER()函数删除重复记录
如果表中没有唯一值的列,可以通过row_number 来删除重复数据
重复执行插入脚本,查看表数据,表中没有唯一列值
Delete T From (Select Row_Number() Over(Partition By [Name] order By [ID]) As RowNumber,* From Student)T Where T.RowNumber > 1
小知识点
语法:ROW_NUMBER() OVER(PARTITION BY COLUMN ORDER BY COLUMN)
表示根据COLUMN分组,在分组内部根据 COLUMN排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)
函数“Row_Number”必须有 OVER 子句。OVER 子句必须有包含 ORDER BY
Row_Number() Over(Partition By [Name] order By [ID]) 表示已name列分组,在每组内以ID列进行升序排序,每组内返回一个唯一的序号
执行删除脚本后查询表数据
posted on 2019-01-29 15:54 springsnow 阅读(25615) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号