朴素贝叶斯进行新闻分类
数据来源
通过爬虫,爬取腾讯新闻三个分类每个分类大约1000条左右数据,存入excel

以上是大体的数据,三列分别为title、content、class;由于这里讲的的不是爬虫,爬虫部分省略
项目最终结构
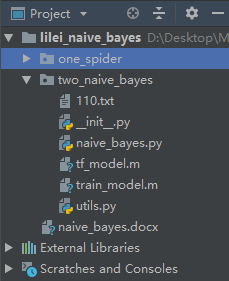
其中主要逻辑在native_bayes.py文件中实现,utils.py为部分工具函数,tr_model.m为tf_idf模型,train_model为我们用朴素贝叶斯训练出来的分类模型。110.txt为预测时的文章内容
使用
通过run方法,来训练一个模型,predict方法去预测输入新闻的类别,代码的大部分解释都在注释里
代码实现
native_bayes.py
1 import os 2 import pandas as pd 3 from sklearn.feature_extraction.text import TfidfVectorizer 4 from sklearn.model_selection import train_test_split 5 from sklearn.naive_bayes import MultinomialNB 6 from sklearn.externals import joblib 7 8 from two_naive_bayes.utils import cut_word, rep_invalid_char 9 10 11 class NaiveBayes(object): 12 """朴素贝叶斯进行新闻分类,现阶段只支持(科技、娱乐、时尚)三个类别的数据分类""" 13 def __init__(self, title, content): 14 print('__init__') 15 self.excel_reader = os.path.join(os.path.join(os.path.pardir, 'one_spider'), 'tx.xlsx') 16 self.data = cut_word([rep_invalid_char(str(title)+str(content))]) 17 18 def read(self): 19 """读取数据,返回特征值与目标值的列表""" 20 print('read.....') 21 df = pd.read_excel(self.excel_reader, 'Sheet') 22 title_list = df['title'].tolist() 23 content_list = df['content'].tolist() 24 target = df['class'].tolist() 25 data = [(str(title_list[i])+str(content_list[i])) for i in range(len(title_list))] 26 data = cut_word(data) 27 return data, target 28 29 def data_split(self, data, target): 30 """ 31 将数据分割成数据集与测试集 32 :param data: 特征值 33 :param target: 目标值 34 :return: 数据集的特征值,测试集的特征值,数据集的目标值,测试集的目标值 35 """ 36 print('data_split.....') 37 x_train, x_test, y_train, y_test = train_test_split(data, target) 38 return x_train, x_test, y_train, y_test 39 40 def feature_extraction(self, x_train): 41 """对训练集进行特征抽取,返回TfIdf处理后的数据和tf""" 42 print('feature_extraction.....') 43 tf = TfidfVectorizer() 44 x_train = tf.fit_transform(x_train) 45 self.tf = tf # 保存此tf,后面进行特征抽取都要用到 46 joblib.dump(tf, 'tf_model.m') 47 return x_train 48 49 def bayes(self, x_train, y_train): 50 """贝叶斯建模""" 51 print('bayes.....') 52 mlt = MultinomialNB() 53 mlt.fit(x_train, y_train) 54 return mlt 55 56 def test(self, mlt, x_test, y_test): 57 """ 58 预测,返回准确率 59 :param mlt: 朴素贝叶斯训练的模型 60 :param x_test: 测试集的原始数据 61 :param y_test: 测试集的目标值 62 :return: 模型的准确率,每次运行的结果是不一样的 63 """ 64 print('test.....') 65 x_test = self.tf.transform(x_test) # 这里用fit_transform数据集的tf,保证维度等的统一 66 y_predict = mlt.predict(x_test) 67 same_num = 0 68 for i in range(len(y_test)): 69 if y_predict[i] == y_test[i]: 70 same_num += 1 71 return float(same_num/len(y_test)) 72 73 def predict(self): 74 """根据传入的文章标题和内容,预测该文章属于哪一个类别""" 75 print('predict.....') 76 # 如果本地模型存在,则从本地模型读取,否则重新进入训练过程,训练并保存模型,得出准确率,并输出文章类别 77 condition_one = os.path.exists(os.path.join(os.path.curdir, 'train_model.m')) 78 condition_two = os.path.exists(os.path.join(os.path.curdir, 'tf_model.m')) 79 if all([condition_one, condition_two]) : 80 model = joblib.load('train_model.m') 81 self.tf = joblib.load('tf_model.m') 82 else: 83 data, target = self.read() 84 x_train, x_test, y_train, y_test = self.data_split(data, target) 85 x_train = self.feature_extraction(x_train) 86 model = self.bayes(x_train, y_train) 87 joblib.dump(model, 'train_model.m') # 保存训练出来的模型 88 number = self.test(model, x_test, y_test) 89 print('模型预测的准确率为:', number) 90 91 data = self.tf.transform(self.data) 92 predict = model.predict(data) 93 print('预测该文章的类别为:', predict[0]) 94 95 def run(self): 96 """ 97 run方法用来训练模型并保存至本地,和评估准确率,predict方法虽然也有这个功能, 98 但是为了训练处一个正确率较大的模型,就需要用run方法反复训练比较后得出最佳的 99 模型保存至本地,在之后的预测中就不用重新训练模型而浪费时间了 100 训练对比模型时,可传入空的title和content即可 101 """ 102 # todo: ======================================================= 103 # 1.读取爬虫爬取的excel表数据 104 # 2.使用jieba分词进行中文分词,得到总的特征值与目标值 105 # 3.进行数据分割,分为数据集与测试集 106 # 4.对数据集进行特征抽取 TfIdf,测试集作为测试数据也需要特征抽取 107 # 5.以训练集中的列表进行重要性统计 108 # 6.朴素贝叶斯算法训练模型 109 # 7.模型对测试集进行预测,得出准确率 110 print('run.....') 111 data, target = self.read() 112 x_train, x_test, y_train, y_test = self.data_split(data, target) 113 x_train = self.feature_extraction(x_train) 114 model = self.bayes(x_train, y_train) 115 joblib.dump(model, 'train_model.m') # 保存训练出来的模型 116 number = self.test(model, x_test, y_test) 117 print('模型预测的准确率为:', number) 118 119 120 121 if __name__ == '__main__': 122 # 需要预测的文章标题和文章内容(可更改) 123 title = '蔚来与Mobileye结盟,合作产品将于2022年面世' 124 with open('110.txt', 'r') as f: 125 content = f.read() 126 # title: 文章标题, content: 文章正文内容 127 nb = NaiveBayes(title, content) 128 # nb.run() 129 nb.predict()
utils.py
1 import re 2 import jieba 3 4 5 def cut_word(data:list): 6 """ 7 进行中文分词 8 :param data: 待分词的数据,列表类型 9 :return: 分词后的数据,列表类型 10 """ 11 res = [] 12 for s in data: 13 word_cut = ' '.join(list(jieba.cut(s))) 14 res.append(word_cut) 15 return res 16 17 def rep_invalid_char(old:str): 18 """只保留字符串中的大小写字母,数字,汉字""" 19 invalid_char_re = r"[^0-9A-Za-z\u4e00-\u9fa5]" 20 return re.sub(invalid_char_re, "", old)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号