干货 | Elasticsearch、Kibana数据导出实战
1、问题引出
以下两个导出问题来自Elastic中文社区。
问题1、kibana怎么导出查询数据?
问题2:elasticsearch数据导出
就像数据库数据导出一样,elasticsearch可以么?
或者找到它磁盘上存放数据的位置,拷贝出来,放到另一个es服务器上或者转成自己要的数据格式?
实际业务实战中,大家或多或少的都会遇到导入、导出问题。
根据数据源的不同,基本可以借助:
-
1、程序写入
-
2、数据同步
logstash/flume/cana/es_hadoopl等来实现关系型数据库(如:Oracle、mysql)、非关系型数据库(如:Mongo、Redis)、大数据(Hadoop、Spark、Hive)到Elasticsearch的写入。
而数据的导出,一部分是业务场景需要,如:业务系统中支持检索结果导出为CSV、Json格式等。
还有一部分是分析数据的需求:期望借助Kibana工具将仪表盘聚合结果导出、不需要借助程序尽快将满足给定条件的结果数据导出等。
这些快速导出的需求,最好借助插件或者第三方工具实现。
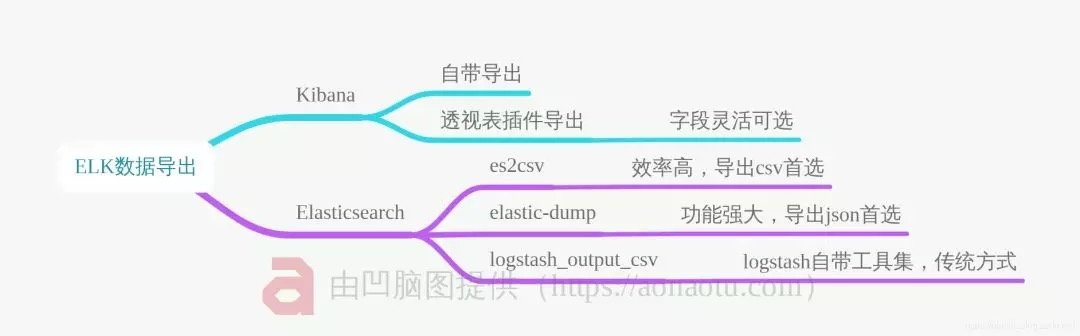
本文将重点介绍Kibana/Elasticsearch高效导出的插件、工具集。
2、期望导出数据格式
一般期望导出:CSV、Json格式。
3、Kibana导出工具
3.1 Kibana 官方导出
步骤1:点击Kibana;
步骤2:左侧选择数据,筛选字段;
步骤3:右侧点击:share->csv reports。
步骤4:菜单栏:选择Management->Reporting->下载。
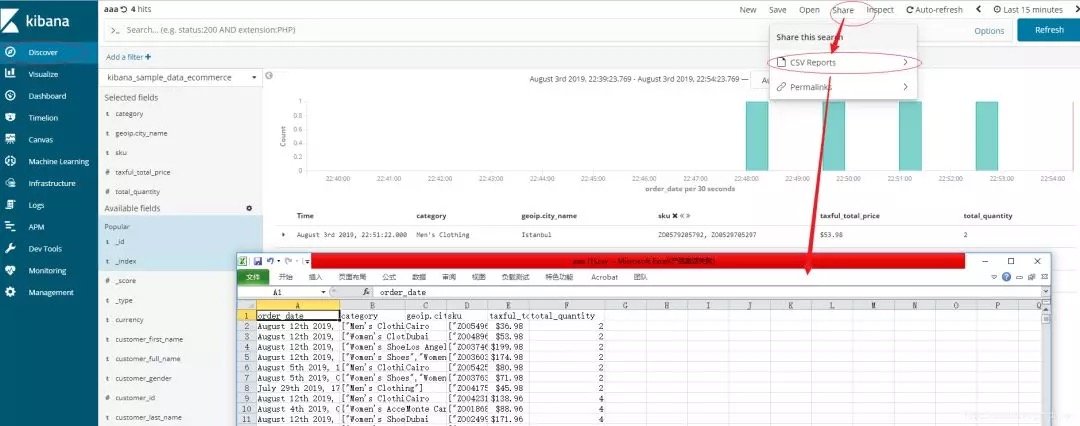
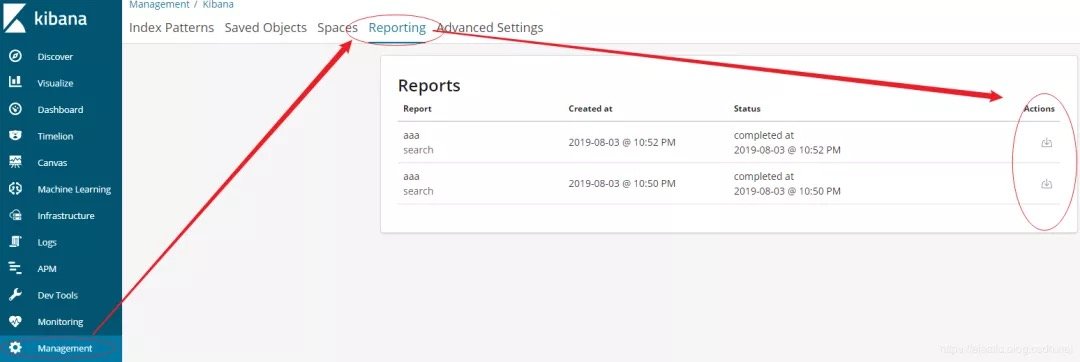
以上是kibana6.5.4的实操截图。
其他常见报表数据导出:

在Dashboard的右上角点击Inspect,再点击就可以导出对应可视化报表对应的数据。
3.2 数据透视表pivot-kibana
Kibana的数据透视表——使用Kibana UI中的任何其他工具一样使用数据透视表可以极大地简化数据工作。
Flexmonster Pivot可以交叉和快速地汇总业务数据并以交叉表格式显示结果。
地址:https://github.com/flexmonster/pivot-kibana/
筛选数据效果如下:
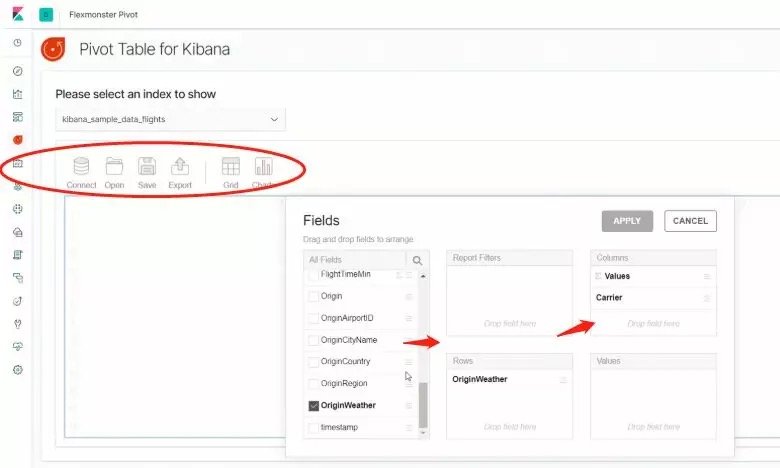
注意:建议7.X以上版本使用。低版本不支持。
4、Elasticsearch导出工具
4.1 es2csv
1、简介:用Python编写的命令行实用程序,用于以Lucene查询语法或查询DSL语法查询Elasticsearch,并将结果作为文档导出到CSV文件中。
es2csv 可以查询多个索引中的批量文档,并且只获取选定的字段,这可以缩短查询执行时间。
2、地址:https://pypi.org/project/es2csv/
3、使用方法:
1es2csv -u 192.168.1.1:9200 -q '{"_source":{"excludes":["*gxn",,"*kex","vperxs","lpix"]},"query":{"term":{"this_topic":{"value":41}}}}' -r -i sogou_topic -o ~/export.csv
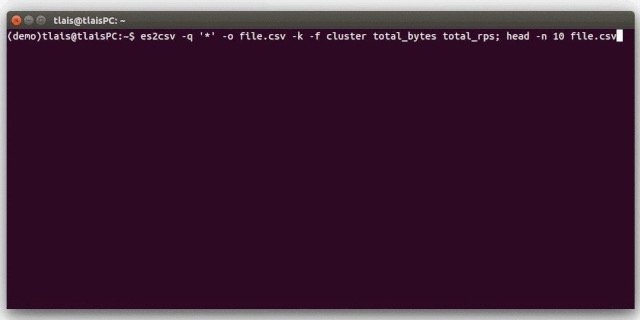
4、使用效果:
官方最新更新支持5.X版本,实际验证6.X版本也可以使用,导出效率高。
5、推荐指数:
五星,
Elasticsearch导出CSV首选方案。
4.2 elasticsearch-dump
1、简介:Elasticsearch导入导出工具。
支持操作包含但不限于:
1)、数据导出
-
导出索引、检索结果、别名或模板为Json
-
导出索引为gzip
-
支持导出大文件切割为小文件
-
支持统一集群不同索引间或者跨索引数据拷贝
2)、数据导入
- 支持Json数据、S3数据导入Elasticsearch。
2、地址:
https://github.com/taskrabbit/elasticsearch-dump
3、使用方法:
1elasticdump \
2 --input=http://production.es.com:9200/my_index \
3 --output=query.json \
4 --searchBody='{"query":{"term":{"username": "admin"}}}'
如上,将检索结果导出为json文件。
更多导入、导出详见github介绍。
4、使用效果:
早期1.X版本没有reindex操作,使用elasticdump解决跨集群数据备份功能。效果可以。
5、推荐指数:
五星。
Elasticsearch导出json首选方案。
4.3 logstash_output_csv
步骤1:安装logstash_output_csv工具:
1D:\logstash-6.5.4\bin>logstash-plugin.bat install logstash-output-csv
2Validating logstash-output-csv
3Installing logstash-output-csv
4Installation successful
步骤2:配置conf文件
核心的:输入input,输出ouput,中间处理filter都在如下的配置文件中。
- 输入:指定ES地址,索引,请求query语句;
- 输出:csv输出地址,输出字段列表。
1input {
2 elasticsearch {
3 hosts => "127.0.0.1:9200"
4 index => "company_infos"
5 query => '
6 {
7 "query": {
8 "match_all": {}
9 }
10 }
11 '
12 }
13}
14
15output {
16 csv {
17 # elastic field name
18 fields => ["no", "name", "age", "company_name", "department", "sex"]
19 # This is path where we store output.
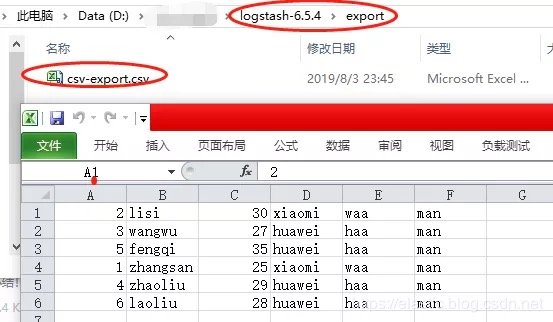
20 path => "D:\logstash-6.5.4\export\csv-export.csv"
21 }
22}
步骤3:执行导出
1D:\\logstash-6.5.4\bin>logstash -f ../config/logstash_ouput_csv.conf
2Sending Logstash logs to D:/2.es_install/logstash-6.5.4/logs which is now configured via log4j2.properties
3[2019-08-03T23:45:00,914][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
4[2019-08-03T23:45:00,934][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.5.4"}
5[2019-08-03T23:45:03,473][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
6[2019-08-03T23:45:04,241][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x34b305d3 sleep>"}
7[2019-08-03T23:45:04,307][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
8[2019-08-03T23:45:04,740][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
9[2019-08-03T23:45:05,610][INFO ][logstash.outputs.csv ] Opening file {:path=>"D:/logstash-6.5.4/export/csv-export.csv"}
10[2019-08-03T23:45:07,558][INFO ][logstash.pipeline ] Pipeline has terminated {:pipeline_id=>"main", :thread=>"#<Thread:0x34b305d3 run>"}
地址:
https://medium.com/@shaonshaonty/export-data-from-elasticsearch-to-csv-caaef3a19b69
5、小结
根据业务场景选择导出数据的方式。
您的业务场景有导出数据需求吗?如何导出的?欢迎留言讨论。
推荐阅读:
为什么选择 Spring 作为 Java 框架?
SpringBoot RocketMQ 整合使用和监控
Elasticsearch实战 | 必要的时候,还得空间换时间!
干货 |《从Lucene到Elasticsearch全文检索实战》拆解实践
JVM面试问题系列:JVM 配置常用参数和常用 GC 调优策略
上篇好文:

posted on 2019-08-19 20:27 SpringForAll 阅读(3433) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号