Elasticsearch实战 | 必要的时候,还得空间换时间!
1、应用场景
实时数据流通过kafka后,根据业务需求,一部分直接借助kafka-connector入Elasticsearch不同的索引中。
另外一部分,则需要先做聚类、分类处理,将聚合出的分类结果存入ES集群的聚类索引中。如下图所示:
业务系统的分层结构可分为:接入层、数据处理层、数据存储层、接口层。
那么问题来了?
我们需要基于聚合(数据处理层)的结果实现检索和聚合分析操作,如何实现更快的检索和更高效的聚合分析效果呢?

2、方案选型
方案一:
只建立一个索引,aggs_index。
数据处理层的聚合结果存入ES中的指定索引,同时将每个聚合主题相关的数据存入每个document下面的某个field下。如下示意图所示:
 方案一示意图
方案一示意图
方案二:
新建两个索引:aggs_index以及aggs_detail_index。
其中:
1)aggs_index存储事件列表信息。
2)aggs_detail_index存储事件关联的文章内容信息。
如下图所示:
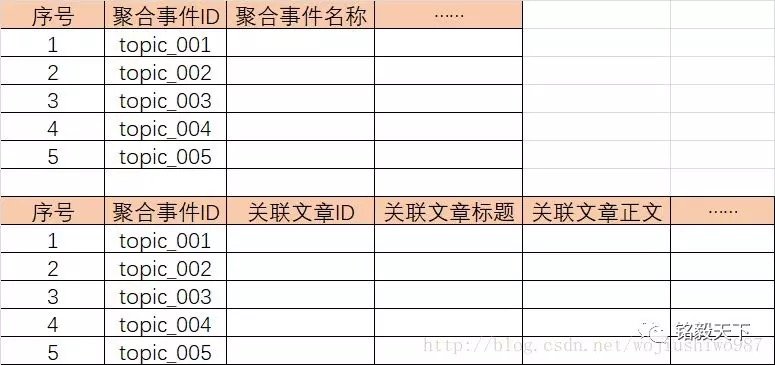 方案二示意图
方案二示意图
3、方案对比
方案一优点:节省存储空间,只存储关联文章id,数据没有重复存储。
方案一缺点:检索、聚合慢,性能不能达标。
方案一后续的所有操作,都需要先遍历检索这一堆IDs,然后再进行检索、聚合分析操作。
操作实例如下(实际比这要复杂):
第一步:通过事件id,获取关联文章id列表;
第二步:基于关联文章id列表,进行检索和聚合操作。
POST aggs_index/_search
{
"_source": {
"includes":[
"title",
"abstract",
"publish_time",
"author"
]},
"query":{
"terms":{
"_id":"["789b4cb872be00a04560d95bf13ec8f42c",
"792d9610b03676dc5644c2ff4db372dec4",
"817f5cff3dd0ec3564d45615f940cb7437",
"....."]
}
}
}
步骤2当id数量很多时,会有如下的错误提示:
{
"error": {
"root_cause": [
{
"type": "too_many_clauses",
"reason": "too_many_clauses:
maxClauseCount is set to 1024"
},
。。。
方案二优点:分开存储,便于一个索引中进行检索、聚合分析操作。
空间换时间,极大的提升检索效率、聚合速度。
方案二缺点:同样的数据,多存储了一份。
其对应的检索操作如下:
POST aggs_index/_search
{
"_source": {
"includes":[
"title",
"abstract",
"publish_time",
"author"
]},
"query":{
"term":{
"topic_id":"WIAEgRbI0k9s1D2JrXPC"
}
}
}
是真的吗?
用事实说话:
以下响应时间的单位为:ms。
方案一要在N个(N接近10)索引,每个索引近千万级别的数据中检索。
 两方案对比
两方案对比
 两方案响应时间对比效果图
两方案响应时间对比效果图
4、小结
-
由以上图示,对比可知,方案二采取了空间换时间的策略,数据量多存储了一份,但是性能提升了10余倍。
-
在实战开发中,我们要理性的选择存储方案,在磁盘成本日渐低廉的当下,把性能放在第一位,用户才能用的"爽“!
推荐阅读:
为什么选择 Spring 作为 Java 框架?
SpringBoot RocketMQ 整合使用和监控
使用Arthas 获取Spring ApplicationContext还原问题现场
上篇好文:

posted on 2019-08-11 12:11 SpringForAll 阅读(257) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号