oracle 学习笔记 PL/SQL
PL/SQL
介绍
组成
(1)数据定义语言(DDL)用于执行数据库的任务,对数据库以及数据库中的各种对象进行创建、删除、修改等操作。
(2)数据操纵语言用于操纵数据库中各种对象、检索和修改数据。
(3)数据控制语言用于安全管理、确定哪些用户可以查看或修改数据库中的数据。
特点
对PL/SQL进行了扩展,在许多方面增强了PL/SQL的功能
主要体现在以下方面:
- SQL和PL/SQL编译器集成PL/SQL现在支持SQL所有范围的语法,如INSERT、UPDATE、DELETE等。
- 支持CASE语句和表达式。
- 继承和动态方法释放。
- 类型进化。
- 新的日期/时间类型。
- PL/SQL代码的本地编译。
- 改善了全球和国家语言支持。
- 表函数和游标表达式。
- 多层集合。
- 对LOB数据类型更好地集成。
- 对批操作的增强。
- MERGE语句
特性
- 数据抽象:可以从数据结构中提取必要的属性,忽略不必要的细节
- 信息隐藏:用户只能看到算法和数据结构设计的给定层次上的信息
字符集
合法字符
所有的大写和小写英文字母;
数字0~9;符号() + -* / < > = ! ~ ;:.`@ % , "# ^&_{ } ? [ ]。
PL/SQL标识符的最大长度为30个字符,不区分大小写。
运算符
算术运算符
+(加)、-(减)、*(乘)、/(除)**(指数)和‖(连接)。
其中﹢(加)和﹣(减)运算符也可用于对DATE(日期)数据类型的值进行运算
关系运算符
- ﹦(等于)、<>或! = (不等于)、<(小于)、>(大于)、>=(大于等于)、<=(小于等于);
- BETWEEN...AND...(检索两值之间的内容);
- IN(检索匹配列表中的值);
- LIKE(检索匹配字符样式的数据);
- IS NULL(检索空数据)。
关系运算符用于测试两个表达式值满足的关系,其运算结果为逻辑值TRUE、FALSE 及UNKNOWN。
逻辑运算符
- AND(两个表达式为真则结果为真)
- OR(只要有一个为真则结果为真)
- NOT(取相反的逻辑值)
其他符号
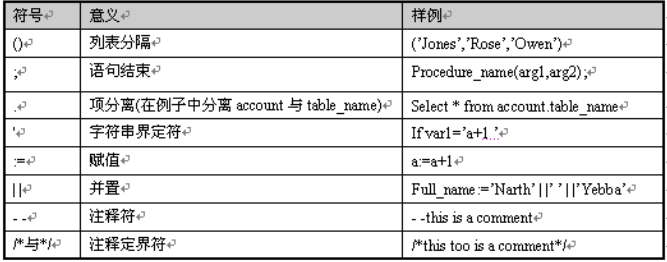
变量、常量和数据类型
变量
变量就是指可以由程序读取或赋值的存储单元。变量用于临时存放数据,变量中的数据随着程序的运行而变化
声明
变量名必须是一个合法的标识符,变量命名规则如下:
- 变量必须以字母(A~Z)开头
- 其后跟可选的一个或多个字母、数字(0~9)或特殊字符$、# 或_
- 变量长度不超过30个字符(4)
- 变量名中不能有空格
基本格式为:<变量名><数据类型>[(宽度):=<初始值>];
属性
%TYPE
%TYPE属性提供了变量和数据库列的数据类型。
在表XS中包含XH列,为了声明一个变量my_xh与XH列具有相同的数据类型,可使用点和%TYPE属性
格式如下:my_xh XS.XH%TYPE;
优点:
- 不必知道XH列的确切的数据类型;
- 如果改变了XH列的数据库定义,my_xh的数据类型在运行时会自动进行修改。
%ROWTYPE
可以使用%ROWTYPE属性声明描述表的行数据的记录,对于用户定义的记录,必须声明自己的域。记录包含唯一的命名域,具有不同的数据类型。
例:
DECLARE
TYPE TimeRec IS RECORD(HH number(2),MM number(2));
TYPE MeetingTyp IS RECORD
(
Meeting_Date date,
Meeting_Time TimeRec,
Meeting_Addr varchar2(20),
Meeting_Purpose varchar2(50)
)
作用域
变量的作用域是指可以访问该变量的程序部分。对于PL/SQL变量来说,其作用域就是从变量的声明到语句块的结束。当变量超出了作用域时,PL/SQL解析程序就会自动释放该变量的存储空间。
常用数据类型
VARCHAR类型
语法格式:var_field VARCHAR(n);
其中长度值n是本变量的最大长度且必须是正整数
在定义变量时,可以同时对其进行初始化,例如:var_field VARCHAR(11):=’Hello world’;
NUMBER类型
NUMBER数据类型可用来表示所有的数值类型。
语法格式:num_field NUMBER(precision,scale);
其中precision表示总的位数;scale表示小数的位数,scale缺省表示小数位为0。
如果实际数据超出设定精度则出现错误。例如:num_field NUMBER(10,2);
num_field是一个整数部分最多使8位,小数部分最多是2的变量
DATE
用来存放日期时间类型数据,用7个字节分别描述年、月、日、时、分、秒。
语法格式:date_field DATE;
日期缺省格式为DD-MON-YY,分别对应日、月、年,例如17-JUN-2002。
注意,月份的表达要用英文单词的缩写格式。日期的格式可以设置为中文格式,例如17-六月-2002。
BOOLEAN
逻辑型(布尔型)变量的值只有true(真)或false(假)。逻辑型变量一般用于判断状态,然后根据其值是“真”或是“假”来决定程序执行分支。关系表达式的值就是一个逻辑值。
对象类型
在多表操作的情况下,当多个表中的列要存储相同类型的数据时,要确保这些列具有完全相同的数据类型、长度和为空性(数据类型是否允许空值)
定义
语法格式:
CREATE OR REPLEACE TYPE schema.type_name
[AUTHID {CURRENT_USER | DEFINER}] AS OBJECT
( attribute1 datatype,
[attribute2 datatype,]
...
[attributen datatype]
[method1]
[method2]
...
[methodn]
schema:用户自定义类型所属方案。
type_name:用户自定义类型名称。
AUTHID:指示将来执行该方法时,必须使用在创建时定义的CURRENT_USER或DEFINER的权限集合。
CURRENT_USER是调用该方法的用户,DEFINER是该对象类型的所有者。
Attribute1:对象类型的属性。属性的声明有一些限制,包括:
- 属性的声明必须在方法声明之前。
- 数据类型可以任何数据库类型,但是不能包括ROWID、UROWID、LONG、LONG RAW、NCHAR、NCLOB、NVARCHAR2类型,以及PL/SQL的专用类型或在PL/SQL包中定义的类型。
- 不能使用那些智能在PL/SQL中使用而不能在数据库中使用的数据类型。这些类型包括:BINARY_INTEGER、BOOLEAN、PLS_INTEGER、RECORD和REF CURSOR。
- 不能使用NOT NULL约束,但是可以通过在对象的实例上定义一个数据库触发器达到类似的效果。
- 属性列表中至少有一个属性。
- 不能使用默认值。
method:定义方法。方法就是过程或函数,它们是在属性声明之后进行声明的。属性描绘对象的特征,而方法是作用在这些特征上的动作。
例:
CREATE OR REPLACE TYPE TEST_TYP
AS OBJECT
(
item_id CHAR(6),
price NUMBER(10,2)
);
数据类型转换
常见转化函数:
- TO_CHAR:将NUMBER和DATE类型转换成VARCHAR2类型。
- TO_DATE:将CHAR转换成DATE类型。
- TO_NUMBER:将CHAR转换成NUMBER类型。
PL/SQL可以在某些类型之间自动转换
例:
DECLARE
MAXC VARCHAR(6);
BEGIN
SELECT MAX(KCL) INTO MAXC
FROM CP;
DBMS_OUTPUT.PUT_LINE(MAXC);
END;
PL/SQL基本程序结构和语句
本逻辑结构包括顺序结构、条件结构和循环结构。除了顺序执行的语句外,PL/SQL主要通过条件语句和循环语句来控制程序执行的逻辑顺序,这就是所谓的控制结构。控制结构是所有程序设计语言的核心。检测不同条件并加以处理是程序控制的主要部分。
条件结构
IF逻辑结构
IF-THEN
语法格式:
IF Boolean_expression THEN /*条件表达式*/
Run_expression /*条件表达式为真时执行*/
END IF
可嵌套
例
DECLARE
MAXC NUMBER(6);
BEGIN
SELECT MAX(KCL) INTO MAXC
FROM CP;
DBMS_OUTPUT.PUT_LINE(MAXC);
IF MAXC < 2000 THEN
DBMS_OUTPUT.PUT_LINE('too low');
END IF;
END;
IF-THEN-ELSE
语法格式:
IF Boolean_expression THEN /*条件表达式*/
Run_expression /*条件表达式为真时执行*/
ELSE
Run_expression /*条件表达式为假时执行*/
END IF
例:
DECLARE
MAXC NUMBER(6);
BEGIN
SELECT MAX(KCL) INTO MAXC
FROM CP;
DBMS_OUTPUT.PUT_LINE(MAXC);
IF MAXC < 900 THEN
DBMS_OUTPUT.PUT_LINE('too low');
ELSE
DBMS_OUTPUT.PUT_LINE('too large');
END IF;
END;
IF-THEN-ELSIF-THEN-ELSE
语法格式:
IF Boolean_expression1 THEN
Run_expression1
ELSIF Boolean_expression2 THEN
Run_expression2
ELSE
Run_expression3
END IF
例:
DECLARE
MAXC NUMBER(6);
BEGIN
SELECT MAX(KCL) INTO MAXC
FROM CP;
DBMS_OUTPUT.PUT_LINE(MAXC);
IF MAXC < 900 THEN
DBMS_OUTPUT.PUT_LINE('too low');
ELSIF MAXC>=1100 THEN
DBMS_OUTPUT.PUT_LINE('too large');
ELSE
DBMS_OUTPUT.PUT_LINE('OK');
END IF;
END;
循环结构
循环提供了一遍又一遍重复执行某段语句直至满足退出条件,退出循环。编写循环语句时,注意一定要确保有相应的退出条件满足。
LOOP-EXIT-END 循环
语法格式:
LOOP
Run_expression /*执行循环体*/
IF Boolean_expression THEN /*测试Boolean_expression是否符合退出条件*/
EXIT; /*满足退出条件,退出循环*/
END IF;
END LOOP;
说明:
Run_expression是在循环体中需要完成的操作。
如果Boolean_expression条件表达式为TRUE则跳出循环,否则继续循环操作,直到满足条件表达式的条件跳出循环。
例:
DECLARE
digit NUMBER:=1;
cnt NUMBER:=0;
BEGIN
LOOP
digit:=digit*2;
cnt:=cnt+1;
IF cnt = 3 THEN
EXIT;
END IF;
END LOOP;
DBMS_OUTPUT.PUT_LINE(digit);
END;
LOOP-EXIT-WHEN-END循环
除退出条件检测有所区别外,此结构与前一个循环结构类似。
语法格式:
LOOP
Run_expression /*执行循环体*/
EXIT WHEN Boolean_expression /*测试是否符合退出条件*/
END LOOP;
例:
DECLARE
digit NUMBER:=1;
cnt NUMBER:=0;
BEGIN
LOOP
digit:=digit*2;
cnt:=cnt+1;
EXIT WHEN cnt = 3;
END LOOP;
DBMS_OUTPUT.PUT_LINE(digit);
END;
WHILE-LOOP-END循环
语法格式:
WHILE Boolean_expression /*测试Boolean_expression是否符合退出条件*/
LOOP
Run_expression /*执行循环体*/
END LOOP;
例:
DECLARE
digit NUMBER:=1;
cnt NUMBER:=0;
BEGIN
WHILE cnt < 3
LOOP
cnt:=cnt+1;
digit:=digit*2;
END LOOP;
DBMS_OUTPUT.PUT_LINE(digit);
END;
FOR-IN-LOOP-END循环循环
语法格式:
FOR count IN count_1..count_n /*定义跟踪循环的变量*/
LOOPRun_expression /*执行循环体*/
END LOOP;
例
DECLARE
digit NUMBER:=1;
cnt NUMBER;
BEGIN
FOR cnt IN 0..2
LOOP
digit:=digit*2;
END LOOP;
DBMS_OUTPUT.PUT_LINE(digit);
END;
选择和跳转语句
CASE
CASE语句是在Oracle9i才引入的,它可以使用简单的结构,对数值列表做出选择。更为重要的是,它还可以用来设置变量的值。
语法格式:
CASE input_name
WHEN expression1 THEN result_expression1
WHEN expression2 THEN result_expression2
...
WHEN expressionN THEN result_expression[ELSE result_expressionN]
END;
例
DECLARE
MAXC NUMBER(6);
BEGIN
SELECT MAX(KCL) INTO MAXC
FROM CP;
DBMS_OUTPUT.PUT_LINE(MAXC);
CASE MAXC
WHEN 900 THEN
DBMS_OUTPUT.PUT_LINE('too low');
WHEN 1100 THEN
DBMS_OUTPUT.PUT_LINE('too large');
ELSE
DBMS_OUTPUT.PUT_LINE('OK');
END CASE;
END;
GOTO
PL/SQL提供GOTO语句,实现将执行流程转移到标号指定的位置。
语法格式:
GOTO label
Label是指向的语句标号,标号必须符合标识符规则。
标号的定义形式:<<label>> 语句使用GOTO语句,可以控制执行顺序。
异常
预定义异常
预定义异常是由运行系统产生的,通过异常处理解决错误问题。
例
DECLARE
fz NUMBER(2):=10;
fm NUMBER(2):=0;
res NUMBER(5);
BEGIN
res:=fz/fm;
EXCEPTION
WHEN ZERO_DIVIDE THEN
DBMS_OUTPUT.PUT_LINE('DIVIDE ZERO');
END;
除了除零错误外,PL/SQL还有很多系统预定义异常

用户定义异常
用户可以通过自定义异常来处理错误的发生,调用异常处理需要使用RAISE语句。
语法格式:
EXCEPTION
WHEN exception_name THEN
sequence_of_statements1;
WHEN THEN
sequence_of_statements2;
[WHEN OTHERS THEN
sequence_of_statements3;]
END;
例:
DECLARE
Overnumber_Error EXCEPTION;
now NUMBER(3):=101;
Max_cnt NUMBER(3):=100;
BEGIN
IF now > Max_cnt
THEN RAISE Overnumber_Error;
END IF;
EXCEPTION
WHEN Overnumber_Error THEN
DBMS_OUTPUT.PUT_LINE('Overnumber Error');
END;
空操作和空值
通过关键字NULL表示不执行操作
例
DECLARE
n NUMBER(2):=-1;
BEGIN
IF n<0 THEN
NULL;
ELSE
DBMS_OUTPUT.PUT_LINE('正常');
END IF;
END;
系统内置函数
常用的数学函数:
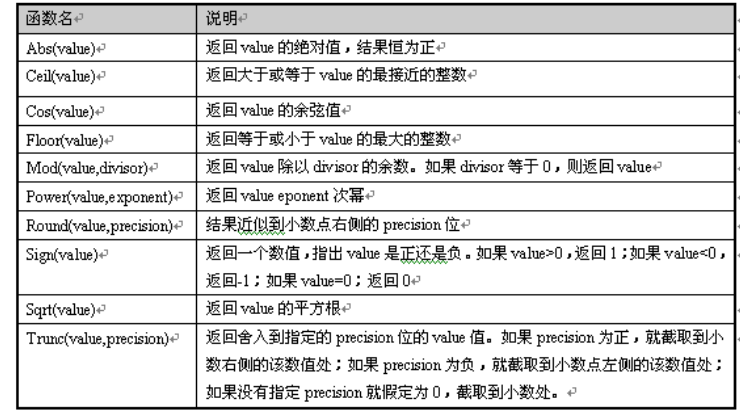
常用字符串函数:
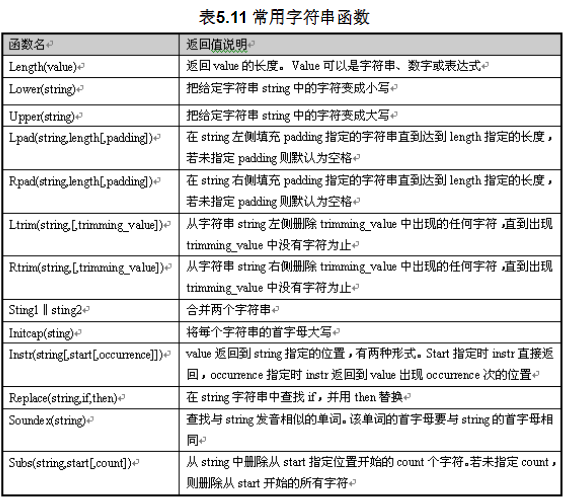
统计函数:
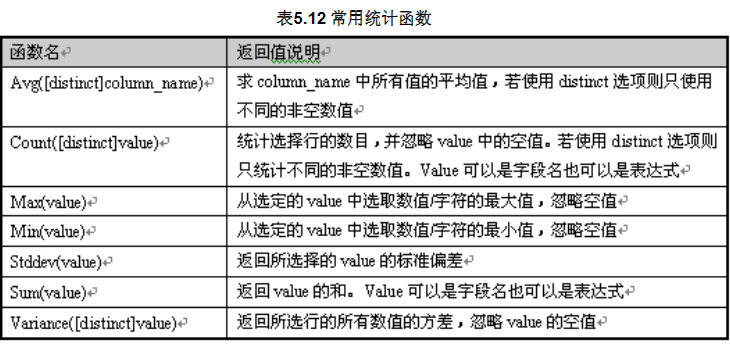
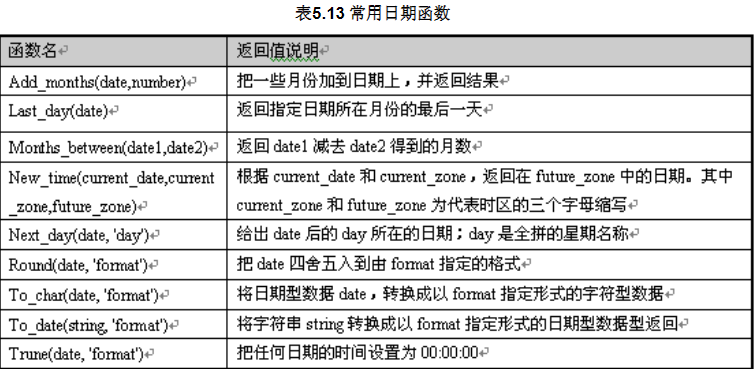
常用日期函数:
用户定义函数
创建
语法格式:
CREATE [OR REPLACE] FUNCTION function_name /*函数名称*/
(
parameter_name1 mode1 datatype1, /*参数定义部分*/
parameter_name2 mode2 datatype2,
parameter_name3 mode3 datatype3,
...
)
RETURN return_datatype /*定义返回值类型*/
IS/AS
BEGIN
function_body /*函数体部分*/
RETURN scalar_expression /*返回语句*/
END function_name;
function_name:用户定义的函数名。
函数名必须符合标识符的定义规则,对其所有者来说,该名在数据库中是唯一的。
parameter:用户定义的参数。用户可以定义一个或多个参数。
mode:参数类型。
- IN 类型 可传值 不可赋值
- OUT 类型 可赋值 不可传值
- IN OUT 类型 可传值、赋值
datatyep:用户定义参数的数据类型。
Return_datatype:函数返回值的数据类型。函数返回scalar_expression表达式的值。
Function_body函数体由PL/SQL语句构成。
例:
CREATE OR REPLACE FUNCTION CAL
(
cnum IN NUMBER
)
RETURN NUMBER
AS ANS NUMBER;
BEGIN
SELECT SUM(KCL) INTO ANS
FROM CP
WHERE JG = cnum;
RETURN(ANS);
END CAL;
调用
无论在命令行还是在程序语句中,函数都可以通过函数名称直接在表达式中调用。
语法格式:
variable_name:=function_name
例:
DECLARE
TOT NUMBER;
BEGIN
TOT:=CAL(500);
DBMS_OUTP
释放
当函数不再使用时,要用drop命令将其从内存中删除。
语法格式:
DROP FUNCTION [schema.]function_name
Schema是函数的拥有者,function_name是函数名。
例
DROP FUNCTION CAL;
游标
PL/SQL用游标(cursor)来管理SQL的SELECT语句。
游标是为处理这些语句而分配的一大块内存。一个对表进行操作的PL/SQL语句通常都可产生或处理一组记录,但是许多应用程序,尤其是PL/SQL嵌入到的主语言(如C、Delphi、PowerBuilder或其它开发工具)通常不能把整个结果集作为一个单元来处理,这些应用程序就需要一种机制来保证每次处理结果集中的一行或几行,游标就提供了这种机制。
PL/SQL通过游标提供了对一个结果集进行逐行处理的能力,游标可看作一种特殊的指针,它与某个查询结果相联系,可以指向结果集的任意位置,以便对指定位置的数据进行处理。使用游标可以在查询数据的同时对数据进行处理
显式游标
显式游标首先要声明(Declare),在使用前要打开(Open),使用完毕后要关闭(Close)
游标声明
显式游标是作为声明段的一部分进行定义的,定义的方法如下:
DECLARE CURSOR cursor_name
IS
select_statement
其中,cursor_name是游标名,它是与某个查询结果集联系的符号名,要遵循Oracle变量定义的规则。
Select_statement是SELECT语句,由该查询产生与所声明的游标相关联的结果集
例 :
DECLARE CURSOR CP_CR IS
SELECT CPBH,CPMC
FROM CP
WHERE KCL <1000;
打开
在PL/SQL中,使用OPEN语句打开游标,其格式为:
OPEN cursor_name
其中,cursor_name是要打开游标名。打开游标后,可以使用系统变量%ROWCOUNT查看游标中数据行的数目。
例:
OPEN CP_CR;
读取数据
游标打开后,就可以使用FETCH语句从中读取数据。
FETCH语句的格式为:
FETCH cursor_name [ INTO variable_name,...n]
其中,Cursor_name为从中提取数据的游标名,INTO表示将读取的游标数据存放到指定的变量variable_name中。
例:
DECLARE
CURSOR CP_CR IS
SELECT DISTINCT CPBH,CPMC
FROM CP
WHERE KCL <1000;
CP_LODER CP_CR%ROWTYPE;
BEGIN
OPEN CP_CR;
FETCH CP_CR INTO CP_LODER;
WHILE CP_CR%FOUND
LOOP
DBMS_OUTPUT.PUT_LINE(CP_LODER.CPBH||','||CP_LODER.CPMC);
FETCH CP_CR INTO CP_LODER;
END LOOP;
CLOSE CP_CR;
END;
关闭游标
游标使用完以后,要及时关闭。关闭游标使用CLOSE语句
格式为:
CLOSE cursor_name;
注意
用%FOUND和%NOTFOUND检验游标成功与否。该属性表示当前游标是否指向有效的一行,根据其返回值TRUE或FALSE检查是否应结束游标的使用。
循环执行游标取数操作时,检索出的总数据行数存放在系统变量%ROWCOUNT中。
游标的目标变量必须与游标SELECT表中表列的数据类型一致
隐式游标
如果在PL/SQL程序段中使用SELECT语句进行操作,PL/SQL会隐含地处理游标定义,即称作隐式游标。
(1) 每一个隐式游标必须有一个INTO;
(2) 和显式游标一样,带有关键字INTO接受数据的变量时数据类型要与列表的一致。
(3) 隐式游标一次仅能返回一行数据,使用时必须检查异常。最常见的异常有“no_data_found”和“too_many_rows”在PL/SQL程序中应尽可能的使用显式标,因为它更有效。具体体现如下:
- 通过检查PL/SQL的系统变量
“%found”或“%notfound”确认成功或失败。使用显式游标的代码段简单地检测这些系统变量以确定使用显示游标的SELECT语句成功或失败。 - 显示游标是在DECLARE段中由用户自己定义的,这样PL/SQL块的结构化程度更高(定义和使用分离)。
- 游标的FOR循环减少了代码的数量,过程清晰明了,更容易按过程化处理。
游标变量
与游标类似,游标变量指向多行查询的结果集的当前行。但是,游标与游标变量是不同的,就像常量和变量之间的关系一样。游标是静态的,游标变量是动态的,因为它并不与特定的查询绑定在一起。可以为任何兼容的查询打开游标变量,从而提高了更好的灵活性。而且,可以将新的值赋予游标变量,将它作为参数传递给本地和存储过程。游标变量对每个PL/SQL客户都是可用的,可以用在PL/SQL主环境中。
游标变量概况
游标变量就像C和Pascal指针一样,保存在某个项目的内存位置,而不是项目本身。因此,声明游标实质是创建一个指针,而不是项目。在PL/SQL中,指针具有数据类型REF X,REF是REFERENCE,X表示类对象。因此,游标变量具有数据类型REF CURSOR。
使用游标变量
使用游标变量,可在PL/SQL存储子程序和大量的客户之间传递查询结果集。PL/SQL和任何客户都不拥有一个结果集,它们只是共享一个查询工作区,在这个工作区中存储了查询结果。例如,OCI客户、Oracle Form应用和Oracle服务器都能指向相同的工作区。
定义REF CURSOR类型
创建游标变量有两个步骤:
首先定义REF CURSOR类型,然后声明这种类型的游标变量。
语法格式:
TYPE ref_type_name
IS
REF CURSOR [RETURN return_type];
其中,ref_type_name是在游标变量中使用的类型;return_type必须表示一个记录或者是数据库表的一行
声明游标变量
一旦定义了REF CURSOR类型,就可以在PL/SQL块或者子程序中声明游标变量
DECLARE
TYPE CP_cur IF REF CURSOR RETURN CP%ROWTYPE;
CPCR CP_cur;
-- 通过原有行定义 RETURN类型
DECLARE
TYPE CP_TYE IS RECORD(
CPBH char(8),
CPMC char(12)
);
TYPE CP_cur IF REF CURSOR RETURN CP_TYE;
CPCR CP_cur;
-- 定义用户自定义的RECORD类型
此外,还可以声明游标变量作为函数和过程的参数
控制游标变量
在使用游标变量时,要遵循如下步骤:OPEN→FETCH→CLOSE。
首先,使用OPEN打开游标变量;然后使用FETCH从结果集中提取行,当所有的行都处理完毕时,使用CLOSE关闭游标变量。
OPEN语句与多行查询的游标相关联,它执行查询,标志结果集。
语法格式:
OPEN {cursor_variable∣: host_cursor_variable}
FOR{ select_statement∣dynamic_string[USING bind_argument[,...]]}
其中,cursor_variable为弱游标变量;host_cursor_variable为强游标变量。select_statement为SQL查询语句。
一个游标表达式返回一个嵌套游标,结果集中的每一行都包含值加上子查询生成的游标
然而,单个查询能够从多个表中提取相关的值。可以使用嵌套循环处理这个结果集,首先提取结果集的行,然后是这些行中的嵌套游标。PL/SQL支持使用游标表达式的查询作为游标声明的一个部分。
语法格式如下:
CURSOR(subquery)
嵌套游标在包含的行从父游标中提取的时候打开。
只有在下面的情形下,嵌套游标才被关闭:
- 嵌套游标被用户显示关闭。
- 父游标被重新执行。
- 父游标被关闭。
- 父游标被取消。
- 在提取父游标的一行时出现错误。
例:
DECLARE
TYPE CP_cur IS REF CURSOR RETURN CP%ROWTYPE;
CPCR CP_cur;
CP_LODER CP%ROWTYPE;
BEGIN
IF NOT CPCR%ISOPEN THEN
OPEN CPCR FOR
SELECT DISTINCT * FROM CP;
END IF;
FETCH CPCR INTO CP_LODER;
WHILE CPCR%FOUND
LOOP
DBMS_OUTPUT.PUT_LINE(CP_LODER.CPBH||','||CP_LODER.CPMC);
FETCH CPCR INTO CP_LODER;
END LOOP;
CLOSE CPCR;
END;
-- 定义原有的RECORD类型
DECLARE
TYPE CP_TYE IS RECORD(
CPBH CP.CPBH%TYPE,
CPMC CP.CPMC%TYPE
);
TYPE CP_cur IS REF CURSOR RETURN CP_TYE;
CPCR CP_cur;
CP_LODER CP_TYE;
BEGIN
IF NOT CPCR%ISOPEN THEN
OPEN CPCR FOR
SELECT DISTINCT CPBH,CPMC FROM CP;
END IF;
FETCH CPCR INTO CP_LODER;
WHILE CPCR%FOUND
LOOP
DBMS_OUTPUT.PUT_LINE(CP_LODER.CPBH||','||CP_LODER.CPMC);
FETCH CPCR INTO CP_LODER;
END LOOP;
CLOSE CPCR;
END;
-- 定义用户自定义的RECORD类型
包
可以利用包(package)将过程和函数安排在逻辑分组中。包含有两个分离的部件:
包说明(规范、包头)和包体(主体)。包说明和包体都存储在数据字典中。
包与过程和函数的一个明显的区别是,包仅能存储在非本地的数据库中。除了允许相关的对象结合为组之外,包与依赖性较强的存储子程序相比其所受的限制较少。除此之外,包的效率比较高。从本质上讲,包就是一个命名的声明部分。任何可以出现在块声明中的语句都可以在包中使用,这些语句包括过程、函数、游标、类型和变量。把上述内容放入包中好处是,用户可以从其他PL/SQL块中对其进行引用,因此包为PL/SQL提供了全程变量。
包格式
包的创建分为包头的创建和包体的创建两部分。
包头
CREATE OR REPLACE PACKAGE [schema.]packge_name /*包头名称*/
IS∣AS
pl/sql_package_spec /*定义过程、函数等*/
其中:
schema:指定将要创建的包所属用户方案。
packge_name:将要创建的包的名称。
pl/sql_package_spec:变量、常量及数据类型定义;游标定义;函数、过程定义和参数列表返回类型。
在定义包头时,要遵循以下规则:
- 包元素的位置可以任意安排。然而,在声明部分,对象必须在引用前进行声明。
- 包头可以不对任何类型的元素进行说明。例如,包头可以只带过程和函数说明语句,而不声明任何异常和类型。
- 对过程和函数的任何声明都必须只对子程序和其参数(如果有的话)进行描述,但不带任何代码的说明,实现代码则只能在包体中。它不同于块声明,在块声明中,过程或函数的代码同时出现在其声明部分。
包体
CREATE OR REPLACE PACKAGE BODY [schema.]package_name
IS∣AS
pl/sql_package_body
说明:
schema:指定将要创建的包所属用户方案。
pl/sql_package_body:游标、函数、过程的具体定义。
包体是一个独立于包头的数据字典对象。包体只能在包头完成编译后才能进行编译。包体中带有实现包头中描述的前向子程序的代码段。除此之外,包体还可以包括具有包体全局属性的附加声明部分,但这些附加说明对于说明部分是不可见的。
例:
CREATE OR REPLACE PACKAGE TEST_PACKAGE
IS
FUNCTION CAL(
cnum IN NUMBER
)
RETURN NUMBER;
END TEST_PACKAGE;
CREATE OR REPLACE PACKAGE BODY TEST_PACKAGE
IS
FUNCTION CAL(
cnum IN NUMBER
)
RETURN NUMBER
AS ANS NUMBER;
BEGIN
SELECT SUM(KCL) INTO ANS
FROM CP
WHERE JG = cnum;
RETURN(ANS);
END CAL;
END TEST_PACKAGE;
-- 创建包
DECLARE
TOT NUMBER;
BEGIN
TOT:=TEST_PACKAGE.CAL(500);
DBMS_OUTPUT.PUT_LINE(TOT);
END;
-- 调用包
DROP PACKAGE TEST_PACKAGE;
-- 清除包
重载
在包中,同样的操作可以通过不同类型的参数实现,但存在限制:
- 如果两个子程序的参数仅在名称和类型上不同,这两个子程序不能重载。
- 不能仅根据两个子程序不同的返回类型对其进行重载。
- 重载子程序的参数的类族(type family)必须不同。
- 根据用户定义的对象类型,打包子程序也可以重载
包的初始化
当第一次调用打包子程序时,该包将进行初始化。也就是说,将该包从硬盘中读入到内存,并启动调用的子程序的编译代码。这时,系统为该包中定义的所有变量分配内存单元。每个会话都有其打包变量的副本,以确保执行同一包子程序的两个对话使用不同的内存单元。在大多数情况下,初始化代码要在包第一次初始化时运行。为了实现这种功能,可以在包体中的所有对象之后加入一个初始化部分。
语法格式:
CRETE OR REPLACE PACKAGE BODY package_name
IS∣AS...
BEGIN
Initialization_code;
END;
其中,package_name是包的名称,Initialization_code是要运行的初始化代码。
Oracle内置包
Oracle提供了若干具有特殊功能的内置包。这些具有特殊功能的包为:
- DBMS_ALERT包:用于数据库报警,允许会话间通信。
- DBMS_JOB包:用于任务调度服务。
- DBMS_LOB包:用于大型对象操作。
- DBMS_PIPE包:用于数据库管道,允许会话间通信。
- DBMS_SQL包:用于执行动态SQL。
- UTL_FILE包:用于文本文件的输入与输出。
除了包UTL_FILE既存储在服务器端又存储在客户端,所有的DBMS包都存储在服务器中。此外,在某些客户环境,Oracle还提供一些额外的包。
集合
PL/SQL的集合类似于其他3GL中使用的数组,是管理多行数据必需的结构体。集合就是列表,可能有序也可能无序。有序列表的索引是唯一性的数字下标;而无序列表的索引是唯一性的标识符,这些标识符可以是数字、哈西值,也可以是一些字符串名。PL/SQL提供了3种不同的集合类型:联合数组(以前称index_by表)、嵌套表、可变数组。
联合数组
联合数组定义
联合是具有Oracle 10g的数据类型或用户自定义的记录/对象类型的一维体。联合数组类似于C语言中的数组。
语法格式:
TYPE tabletype
IS
TABLE OF type
INDEX BY BINARY_INTEGER;
其中:tabletype是指所定义的新类型的类型名;type是要定义的联合数组的类型。
例:
TYPE CP_NAME IS
TABLE OF CP.CPBH%TYPE
INDEX BY BINARY_INTEGER;
CPBHS CP_NAME;
联合数组赋值
可以直接用:=对表中的元素赋值
由于联合数组中的元素不是按特定顺序排列的,因此联合数组的元素的个数只是受到BINARY_INTEGER类型的限制,即index的范围为-214483647~+214483647。因此只要在此范围内给元素赋值就是合法的
例:
DECLARE
TYPE CP_NAME IS
TABLE OF CP.CPBH%TYPE
INDEX BY BINARY_INTEGER;
CPBHS CP_NAME;
BEGIN
CPBHS(1):='1001';
CPBHS(2):='1010';
CPBHS(-3):='0001';
DBMS_OUTPUT.PUT_LINE(CPBHS(-3));
END;
不可调用未赋值元素
嵌套表
嵌套表声明
嵌套表的声明和联合数组的声明十分类似。
语法格式:
TYPE table_name IS
TABLE OF table_type[NOT NULL]
嵌套表和联合数组的唯一不同就是没有INDEX BY BINARY_INTEGER子句,因此区别这两种类型的唯一方法就是看是否含有INDEX BY BINARY_INTEGER子句。
嵌套表初始化
嵌套表的初始化与联合数组的初始化完全不同。在声明了类型之后,再声明一个联合数组变量类型,如果没有给该表赋值,那么该表就是一个空的联合数组。但是,在以后的语句中可以继续向联合数组中添加元素;而声明了嵌套表变量类型时,如果嵌套表中没有任何元素,那么它就会自动初始化为NULL,并且是只读的。如果还想向这个嵌套表中添加元素,系统就会提示出错。
例:
DECLARE
TYPE CP_NAME IS
TABLE OF CP.CPBH%TYPE;
CPBHS CP_NAME:=CP_NAME('1000','1001','1002');
BEGIN
FOR i in 1..3 LOOP
DBMS_OUTPUT.PUT_LINE(CPBHS(i));
END LOOP;
END;
-- 嵌套表初始化
嵌套表与联合数组十分相似,只是嵌套表在结构上是有序的,而联合数组是无序的。如果给一个嵌套表赋值,嵌套表元素的index将会从1开始依次递增。
可变数组
可变数组声明
语法格式:
TYPE type_name IS
VARRAY∣VARYING ARRAY
(maximun_size) OF element_type[NOT NULL]
说明:
type_name为可变数组的名称;maximun_size是指可变数组元素个数的最大值;element_type是指数组元素的类型。
可变数组初始化
与嵌套表一样,可变数组也需要初始化。初始化时需要注意的是,赋值的数量必须保证不大于可变数组的最大上限。
例:
DECLARE
TYPE Dates IS
VARRAY(7) OF VARCHAR(10);
V_dates dates:=dates('MON','TUE','WED');
BEGIN
FOR i in 1..3 LOOP
DBMS_OUTPUT.PUT_LINE(v_dates(i));
END LOOP;
END;
集合的属性和方法
COUNT属性
COUNT是一个函数,它用来返回集合中的数组元素个数。
例:
DECLARE
TYPE Dates IS
VARRAY(7) OF VARCHAR(10);
V_dates dates:=dates('MON','TUE');
TYPE CP_NAME IS
TABLE OF CP.CPBH%TYPE;
CPBHS CP_NAME:=CP_NAME('1000');
TYPE CP_CPMC IS
TABLE OF CP.CPMC%TYPE
INDEX BY BINARY_INTEGER;
CPMCS CP_CPMC;
BEGIN
CPMCS(1):='1001';
CPMCS(2):='1010';
CPMCS(-3):='0001';
DBMS_OUTPUT.PUT_LINE(V_dates.COUNT);
DBMS_OUTPUT.PUT_LINE(CPBHS.COUNT);
DBMS_OUTPUT.PUT_LINE(CPMCS.COUNT);
END;
DELETE方法
DELETE是用来删除集合中的一个或多个元素。
需要注意的是,由于DELETE方法执行的删除操作的大小固定,所以对于可变数组来说没有DELETE方法。
DELETE方法有3种方式:
- DELETE:不带参数的DELETE方法即将整个集合删除。
- DELETE(x):即将集合表中第x个位置的元素删除。
- DELETE(x,y):即将集合表中从第x个元素到第y个元素之间的所有元素删除。
例:
DECLARE
TYPE CP_NAME IS
TABLE OF CP.CPBH%TYPE;
CPBHS CP_NAME:=CP_NAME('1000','1001','1002','1001','1000');
BEGIN
DBMS_OUTPUT.PUT_LINE(CPBHS.COUNT);
CPBHS.DELETE(3);
DBMS_OUTPUT.PUT_LINE(CPBHS.COUNT);
CPBHS.DELETE(1,2);
DBMS_OUTPUT.PUT_LINE(CPBHS.COUNT);
CPBHS.DELETE;
DBMS_OUTPUT.PUT_LINE(CPBHS.COUNT);
END;
EXISTS属性
EXISTS是用来判断集合中的元素是否存在。
语法格式:
EXISTS(X)
即判断位于位置X处的元素是否存在,如果存在则返回TRUE;如果X大于集合的最大范围,则返回FALSE。
注意:使用EXISTS判断时,只要在指定位置处有元素存在即可,即使该处的元素为NULL,EXISTS也会返回TRUE
例:
DECLARE
TYPE CP_NAME IS
TABLE OF CP.CPBH%TYPE;
CPBHS CP_NAME:=CP_NAME('1000','1001','1002','1001','1000');
BEGIN
IF CPBHS.EXISTS(1) THEN
DBMS_OUTPUT.PUT_LINE('YES');
ELSE
DBMS_OUTPUT.PUT_LINE('NO');
END IF;
IF CPBHS.EXISTS(6) THEN
DBMS_OUTPUT.PUT_LINE('YES');
ELSE
DBMS_OUTPUT.PUT_LINE('NO');
END IF;
END;
EXTEND方法
EXTEND方法用来将元素添加到集合的末端,具体形式有以下几种:
- EXTEND:不带参数的EXTEND是将一个NULL元素添加到集合的末端。
- EXTEND(x):将x个NULL元素添加到集合的末端。
- EXTEND(x,y):将x个位于y的元素添加到集合的末端
例:
DECLARE
TYPE CP_NAME IS
TABLE OF CP.CPBH%TYPE;
CPBHS CP_NAME:=CP_NAME('1000','1001','1002','1001','1000');
BEGIN
CPBHS.EXTEND;
IF CPBHS.EXISTS(1) THEN
DBMS_OUTPUT.PUT_LINE('YES');
ELSE
DBMS_OUTPUT.PUT_LINE('NO');
END IF;
IF CPBHS.EXISTS(6) THEN
DBMS_OUTPUT.PUT_LINE('YES');
ELSE
DBMS_OUTPUT.PUT_LINE('NO');
END IF;
END;
由于index_by表元素的随意性,因此EXTEND方法只对嵌套表和可变数组有效
FIRST和LAST属性
FIRST是用来返回集合的第一个元素,LAST则是返回集合的最后一个元素。
LIMIT属性
LIMIT用来返回集合中的最大元素个数。由于嵌套表没有上限,所以当嵌套表使用LIMIT时,总是返回NULL
NEXT和PRIOR属性
使用NEXT和PRIOR时,它的后面都会跟一个参数。
语法格式:
NEXT(X)
PRIOR(X)
其中,NEXT(X)返回位置为X处的元素后面的那个元素;PRIOR(X)返回X处的元素前面的那个元素。
TRIM方法
TRIM方法用来删除集合末端的元素,其具体形式如下:
TRIM:不带参数的TRIM从集合中末端删除一个元素。
TRIM(X):是从集合的末端删除X个元素,其中X要小于集合的COUNT数。
注意:与EXTEND一样,由于index_by表元素的随意性,因此TRIM方法只对嵌套表和可变数组有效

 浙公网安备 33010602011771号
浙公网安备 33010602011771号