
Python入门精讲笔记-02-文本序列类型
02:字符串 str
- 02:字符串 str
- 一、字符串基础
- 二、列表和字串的关联
- 1.构造一个list
- 2.使用字符串的join()方法将list拼接成一个字符串
- 3.字符串的分割,使用字符串的
split方法 - 4.字符串判断是否以特定字符开头、结尾 使用
startswith,endswith注意是starts和ends - 5.字符串中查找字符串的位置
.find(),返回值是index - 6.字符串的占位符和
.formart()方法,见之前的笔记 - 7.字符串的
.index()和.find()方法的差别 - 8.字符串的大小写
- 9.字符串其他方法
- 9.1 swapcase() 交换字符串的大小写
- 9.2 casefold() 消除大小写副本,返回小写,并且会涉及到字符转换
- 9.3 str.center(width[,fillchar]) 字符根据指定的宽度居中,多余部分用指定字符填充
- 9.4 str.count(sub[, start[, end]])
- 9.5 str.encode(encoding='utf-8', errors='strict')
- 9.6 str.expandtabs(tabsize=8) 用空格替换制表符
- 9.7 str.format(*args,**kwargs) 用于字符串格式化的操作
- 9.8 str.format_map(mapping)
- 9.9 str.isalnum()
- 9.10 str.isalpha()
- 9.11 str.isascii()
- 9.12 str.isdecimal()
- 9.13 str.isdigit()
- 9.14 str.isidentifier()
- 9.15str.islower()
- 9.16 str.isnumeric()
- 9.17 str.isprintable()
- 9.18 str.isspace()
- 9.18 str.istitle()
- 9.19 str.isupper()
- 9.20 str.join(iterable)
- 9.21 str.ljust(width[, fillchar])
- fillchar只能是一个字符串,否者抛出异常:TypeError: The fill character must be exactly one character long
- 9.22 str.lower()
- 9.23 str.lstrip([chars])
- 9.24 str.translate(table)
- 9.25 str.partition(sep)
- 9.26 str.removeprefix(prefix, /)
- 9.27 str.removesuffix(suffix, /)
- 9.28 str.replace(old, new[, count])
- 9.29 str.rfind(sub[, start[, end]])
- 9.30 str.rindex(sub[, start[, end]])
- 9.31 str.rjust(width[, fillchar])
- 9.32 str.rpartition(sep)
- 9.33 str.rsplit(sep=None, maxsplit=- 1)
- 9.34 str.rstrip([chars])
- 9.35 str.split(sep=None, maxsplit=- 1)
- 9.36 str.splitlines(keepends=False)
一、字符串基础
1.单引号和双引号以及三引号的差别
用户使用单引号和双引号,三引号是对函数的一个说明,可以生成文档
def greeting():
"""欢迎欢迎"""
pass
help(greeting)
>>>greeting()
欢迎欢迎
2.转义符
| 转义符 | 意义 | 备注 |
|---|---|---|
| / | (在行尾时) | 续行符 |
\\ |
反斜杠符 | |
| ' | 单引号符 | |
| " | 双引号符 | |
| \a | 响铃 | |
| \b | 退格 | |
| \e | 转义 | 意义暂时不明?? |
| \000 | 空 | |
| \n | 换行 | |
| \v | 纵向制表符 | |
| \t | 横向制表符 | |
| \r | 回车 | |
| \f | 换页 | |
| \oyy | 八进制数进行转义 | \o12代表换行 |
| \xyy | 十六进制数 | \x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
3.字符串的操作
3.1使用全局函数len()获取字符串的长度
len('My name is Tom')
14
3.2 字符串的连接操作
'abc'+'xyz'
>>>'abcxyz'
3.3 print 函数的结束符号
3.3.1 print函数可以指定打印的结束符号,默认是以\n来结束的
print('Hello World!')
Hello World!
3.3.2 也可以指定其他的符号来结束
print('myhoney',end=' ')
print('hello kitty')
结果如下,可以看到有一个\n的符号:
myhoney hello kitty
Process finished with exit code 0
3.3.3 print函数的其他参数

| 参数名称 | 参数作用 | 备注 |
|---|---|---|
| object | 需要打印的字符 | |
| sep | 字符间的分隔符号 | 用于打印多个字符间的连接符号 |
| end | 打印后的字符 | |
| file | 暂时未知 | |
| flush | 暂时未知 |
# sep中就是用于分隔的字符串
print('Lucy', 'Lily', sep=' twins ')
Lucy twins Lily
# end就是用与填充最后打印完成的字符
print('Lucy', 'Lily', sep=' and ', end=' twins')
Lucy and Lily twins
Process finished with exit code 0 (没有\n换行)
# file的演示:可以直接写入到文件
with open(r'd:\test.txt', 'w') as f:
print('write to file', 'second line', sep='\n', end='\n',file=f)
写入到文本的结果如下:
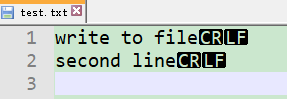
关于print函数的说明
builtins.py:
*def print(self, args, sep=' ', end='\n', file=None): # known special case of print
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
- Optional keyword arguments:*
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
3.4 字符串的索引值和访问
3.4.1 字符串的索引index
字符串的index从0开始,最后一位是不包含在内的,如要访问第6个,则最后的索引要到6
company = 'HyteraCommunication'
print(company[0:6])
>>>Hytera
3.4.2 字符串的最后一位是 -1
company = 'HyteraCommunication'
print(company[-1])
结果是:n
如果不想用-1也可以用len()和索引进行一个变通:
company = 'HyteraCommunication'
print(company[len(company)-1])
结果是:n
3.4.2 字符串的间隔取值
3.4.2.1)可以通过str[:]的形式来获取到
str1 = 'abcdefghijkl'
print(str1[:])
>>>abcdefghijkl
3.4.2.2)可以通过间隔跳跃取值
可以看到,取值为2的时候,取值直接加上这个步进就ok了
a[0] a[2] a[4]
str1 = 'abcdefghijkl'
print(str1[::2])
4)字符串的最后一个索引是-1
字符串的最后一个索引是-1,然后也是从前往后遍历的
str1 = 'abcdefghijkl'
print(str1[-5:-1])
>>>注意结果是:hijk,后面的-1是一个开区间
5)实现一个字符串的反转输出的最快的方式
str2 = 'Good Night'
str2 = str2[::-1]
print(str2)
>>>结果:thgiN dooG
a[i:j:s]当s<0时,i缺省时,默认为-1. j缺省时,默认为-len(a)-1
所以a[::-1]相当于 a[-1:-len(a)-1:-1],也就是从最后一个元素到第一个元素复制一遍。所以你看到一个倒序的东东。
总结:
1、str[i:j:k],其中k默认值为1,表示从左往右的切片,str[2:5:1]
5)字符串和数字相乘,实现字符串的重复
'love'*3
>>>'lovelovelove'
5)查看字符的ascii码中对应的位置
ord('a')
97
查看位置所对应的字符串
chr(98)
'b'
3.4.2 字符串不支持原位改变
str1 = 'Hello'
str1[0] = 'K'
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: 'str' object does not support item assignment
但是字符串有一个replace()的方法,可以改变字符串中的元素,但是以前的字符串不支持原位改变,所以打印出来的字符串是不会变化的😂
str1 = 'Hello'
str1.replace('l','r')
>>>'Herro'
str1
>>>'Hello'
如果非要改变之前的变量的值为新的字符串的话,那可以重新指向新的对象。
这里要注意的是:只是将变量重新指派到新的字符串,以前的字符串并未原位改变
str1 = 'hello'
str1 = str1.replace('l','r')
str1
>>>'herro'

经过变化,hello并未改变,str1指向新的变量而已

二、列表和字串的关联
1.构造一个list
1.1可以通过list()创建一个空的列表
l = list()
l
>>>[]
1.2可以通过list()将字符串转换成一个list
s
>>>'www.hytera.com'
listA = list(s)
>>>listA
['w', 'w', 'w', '.', 'h', 'y', 't', 'e', 'r', 'a', '.', 'c', 'o', 'm']
1.3 直接将变量赋值给一个空的list,创建空列表
l = []
type(l)
>>><class 'list'>
l
>>>[]
2.使用字符串的join()方法将list拼接成一个字符串
需要注意的是:join()是一个字符串的方法
listA
>>>['w', 'w', 'w', '.', 'h', 'y', 't', 'e', 'r', 'a', '.', 'c', 'o', 'm']
l = ''.join(listA)
l
>>>'www.hytera.com'
如果join前面的字符串不是空的话,会在每个次迭代都加上这个字符
s = 'HelloKitty'
l = list(s)
l
>>>['H', 'e', 'l', 'l', 'o', 'K', 'i', 't', 't', 'y']
'Love'.join(l)
>>>'HLoveeLovelLovelLoveoLoveKLoveiLovetLovetLovey'
str.join(iterable)
Return a string which is the concatenation of the strings in the iterable iterable. A TypeError will be raised if there are any non-string values in iterable, including bytes objects. The separator between elements is the string providing this method.
3.字符串的分割,使用字符串的split方法
可以通过split()来进行分割,返回的是一个列表。
url = 'wwww.baidu.com,www.sina.com,www.google.com'
url.split(',')
>>>['wwww.baidu.com', 'www.sina.com', 'www.google.com']
4.字符串判断是否以特定字符开头、结尾 使用startswith,endswith注意是starts和ends
>>> url = 'www.hytera.com'
>>> url.startswith('www.')
True
>>> url.endswith('.com')
True
5.字符串中查找字符串的位置 .find(),返回值是index
返回的值为第一个命中的字符串的index,可以用来查找某一个字符第一次出现的索引值
>>> url = 'www.baidu.com'
>>> url = 'www.googoole.com'
>>> url.find('goo')
返回值(返回的是index):
4
6.字符串的占位符和.formart()方法,见之前的笔记
7.字符串的.index()和.find()方法的差别
@20180829新增
7.1相同的地方
如果存在要查找的元素,那么功能是相同的。使用.index()方法可以查询到第一次出现值的索引
# 使用.index()方法
>> str1 = 'www.hytera.com'
>>> str1.index('A')
>>> str1.index('a')
9
# 使用.find()方法
>>> str1.find('a')
9
7.2差异的地方
主要在于未查询到值后的返回情况:
1).index()未查询到,会抛出一个异常:ValueError: substring not found
2).find()未查找到,会返回-1
# 使用string的index()查询不到
>>> str1.index('G')
Traceback (most recent call last):
File "<input>", line 1, in <module>
ValueError: substring not found
# 使用find查询不到,会返回 -1
>>> str1.find('G')
-1
8.字符串的大小写
8.1 字符串的大小写转换
url1 = 'www.google.com'
url2 = 'WWW.BING.COM'
# 所有字符全部转大写
url1.upper()
'WWW.GOOGLE.COM'
# 所有字符全部转小写
url2.lower()
'www.bing.com'
8.2 每个字符串开头字母大写
title方法,让每个字符串的开头字母都大写,单词的其他字母小写。
s = 'i have5tickets for you!thank.you!'
s.title()
输出:
'I Have5Tickets For You!Thank.You!'
第2个例子,一句话中大小写混杂,会将每个单词的第一个字母大写。
s1 = 'THANK YOU ,haVE a nICE Day!'
s1.title()
'Thank You ,Have A Nice Day!'
8.3 首字母大写,其余全部小写
s1 = 'THANK YOU ,haVE a nICE Day!'
s1.capitalize()
输出:
'Thank you ,have a nice day!'
9.字符串其他方法
python提供了很多字符串处理的内置方法,了解这些内置方法,可以提升字符串处理的效率。
9.1 swapcase() 交换字符串的大小写
交换字符串的大小写,大写转成小写,小写转成大写,对于符号则不进行任何处理。
a = 'aaaBBBccc555....__1@#$%^&*()_+'
a.swapcase()
'AAAbbbCCC555....__1@#$%^&*()_+'
9.2 casefold() 消除大小写副本,返回小写,并且会涉及到字符转换
返回原字符串消除大小写的副本。 消除大小写的字符串可用于忽略大小写的匹配。
消除大小写类似于转为小写,但是更加彻底一些,因为它会移除字符串中的所有大小写变化形式。 例如,德语小写字母 'ß' 相当于 "ss"。 由于它已经是小写了,lower() 不会对 'ß' 做任何改变;而 casefold() 则会将其转换为 "ss"。
字符串中包含了ß这个字符,使用casefolde()时候,会转成ss
a = 'AAßbbbCCCdddEEEff21233434%^&*(...'
r = a.casefold()
print(r)
运行结果:
aassbbbcccdddeeeff21233434%^&*(...
9.3 str.center(width[,fillchar]) 字符根据指定的宽度居中,多余部分用指定字符填充
返回长度为 width 的字符串,原字符串在其正中。 使用指定的 fillchar 填充两边的空位(默认使用 ASCII 空格符)。 如果 width 小于等于 len(s) 则返回原字符串的副本。
a.center(10,'P')
输出:
'PPPcatPPPP'
a.center(20,'¥')
输出:
'¥¥¥¥¥¥¥¥cat¥¥¥¥¥¥¥¥¥'
9.4 str.count(sub[, start[, end]])
返回子字符串 sub 在 [start, end] 范围内非重叠出现的次数。 可选参数 start 与 end 会被解读为切片表示法。
PyDev console: starting.
Python 3.10.4 (tags/v3.10.4:9d38120, Mar 23 2022, 23:13:41) [MSC v.1929 64 bit (AMD64)] on win32
s = 'www.google.com'
s.count('w')
3
s.count('g')
2
s.count('oo')
1
s.count('o',-1,-3)
0
s.count('o',-3,-1)
1
s.count('o')
3
s.count('o',-1,-3,-1)
Traceback (most recent call last):
File "C:\Program Files\Python310\lib\code.py", line 90, in runcode
exec(code, self.locals)
File "<input>", line 1, in <module>
TypeError: count() takes at most 3 arguments (4 given)
9.5 str.encode(encoding='utf-8', errors='strict')
返回原字符串编码为字节串对象的版本。 默认编码为 'utf-8'。 可以给出 errors 来设置不同的错误处理方案。 errors 的默认值为 'strict',表示编码错误会引发 UnicodeError。 其他可用的值为 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及任何其他通过 codecs.register_error() 注册的值,请参阅 错误处理方案 小节。 要查看可用的编码列表,请参阅 标准编码 小节。
默认情况下,为了获得最佳性能,不会检测 errors 参数,而只在首次编码错误时用到它。若要检测 errors ,请启用 Python开发模式 或用 调试版本 。
在 3.1 版更改: 加入了对关键字参数的支持。
在 3.9 版更改: 现在,仅在开发模式和 调试模式 下才会检测 errors。
encoding是将字符串编码成字节流,所以返回的内容是b开头的字符串。
s.encode()
b'www.baidu.com'
type(s.encode())
<class 'bytes'>
| 参数 | 描述 |
|---|---|
| encoding | 可选。字符串。规定要使用的编码。默认是 UTF-8。 |
| errors | 可选。字符串。规定错误方法。合法值如下表 |
对于无法正确编码的字符,进行替换的策略如下:
| 参数 | 作用 |
|---|---|
| 'backslashreplace' | 使用反斜杠代替无法编码的字符 |
| 'ignore' | 忽略无法编码的字符 |
| 'namereplace' | 用解释字符的文本替换字符 |
| 'strict' | 默认值,失败时引发错误 |
| 'replace' | 用问号替换字符 |
| 'xmlcharrefreplace' | 用 xml 字符替换字符 |
s
'Hello, my Chinese name is 张三,nice to meet you!'
# 使用反斜杠代替无法编码的字符
s.encode(encoding='ascii',errors='backslashreplace')
b'Hello, my Chinese name is \\u5f20\\u4e09,nice to meet you!'
#忽略无法编码的字符
s.encode(encoding='ascii',errors='ignore')
b'Hello, my Chinese name is ,nice to meet you!'
# 用解释字符的文本替换字符
s.encode(encoding='ascii',errors='namereplace')
b'Hello, my Chinese name is \\N{CJK UNIFIED IDEOGRAPH-5F20}\\N{CJK UNIFIED IDEOGRAPH-4E09},nice to meet you!'
# 默认值,失败时引发错误
s.encode(encoding='ascii',errors='strict')
Traceback (most recent call last):
File "C:\Program Files\Python310\lib\code.py", line 90, in runcode
exec(code, self.locals)
File "<input>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 26-27: ordinal not in range(128)
# 用问号替换字符
s.encode(encoding='ascii',errors='replace')
b'Hello, my Chinese name is ??,nice to meet you!'
# 用 xml 字符替换字符
s.encode(encoding='ascii',errors='xmlcharrefreplace')
b'Hello, my Chinese name is 张三,nice to meet you!'
9.6 str.expandtabs(tabsize=8) 用空格替换制表符
返回字符串的副本,其中所有的制表符会由一个或多个空格替换,具体取决于当前列位置和给定的制表符宽度。 每 tabsize 个字符设为一个制表位(默认值 8 时设定的制表位在列 0, 8, 16 依次类推)。 要展开字符串,当前列将被设为零并逐一检查字符串中的每个字符。 如果字符为制表符 (\t),则会在结果中插入一个或多个空格符,直到当前列等于下一个制表位。 (制表符本身不会被复制。) 如果字符为换行符 (\n) 或回车符 (\r),它会被复制并将当前列重设为零。 任何其他字符会被不加修改地复制并将当前列加一,不论该字符在被打印时会如何显示。
s = 'ab\tcec\te'
r = s.expandtabs()
print(r)
输出:
ab cec e
输出:
['a', 'b', ' ', ' ', ' ', ' ', ' ', ' ', 'c', 'e', 'c', ' ', ' ', ' ', ' ', ' ', 'e']
打印结果;
0 a
1 b
2
3
4
5
6
7
8 c
9 e
10 c
11
12
13
14
15
16 e
根据打印的内容可以看到,这里不是简单的将制表符替换成空格,而是根据制表符的位置,默认按照8个字符进行补齐,因为这里的tablesize默认值是8.
如果是以\t开头,则也同样会使用指定的tabsize进行替换和补充。
s
'\tabcdefg'
r = s.expandtabs(tabsize=3)
r
' abcdefg'
r.count(' ')
3
9.7 str.format(*args,**kwargs) 用于字符串格式化的操作
执行字符串格式化操作。 调用此方法的字符串可以包含字符串字面值或者以花括号 {} 括起来的替换域。 每个替换域可以包含一个位置参数的数字索引,或者一个关键字参数的名称。 返回的字符串副本中每个替换域都会被替换为对应参数的字符串值。
name,age,gender = 'Lucy',22,'female'
# 可以使用数字
'Person info is name:{0} age:{1} gender:{2}'.format(name,age,gender)
'Person info is name:Lucy age:22 gender:female'
# 也可以不使用数字
'Person info is name:{} age:{} gender:{}'.format(name,age,gender)
'Person info is name:Lucy age:22 gender:female'
format还可以进行小数的操作和进制的转换等等操作:
'{:.2f}'.format(3.1415926)
'3.14'
'{:0x}'.format(999)
'3e7'
9.8 str.format_map(mapping)
以下为官方的例子,实际未使用过。
类似于 str.format(**mapping),不同之处在于 mapping 会被直接使用而不是复制到一个 dict。 适宜使用此方法的一个例子是当 mapping 为 dict 的子类的情况:
class Default(dict):
def __missing__(self, key):
return key
'{name} was born in {country}'.format_map(Default(name='Guido'))
'Guido was born in country'
9.9 str.isalnum()
如果字符串中的所有字符都是字母或数字且至少有一个字符,则返回 True , 否则返回 False 。 如果 c.isalpha() , c.isdecimal() , c.isdigit() ,或 c.isnumeric() 之中有一个返回 True ,则字符c是字母或数字。
Return True if the string is an alpha-numeric string, False otherwise.
A string is alpha-numeric if all characters in the string are alpha-numeric and
there is at least one character in the string.
'abc123'.isalnum()
True
'abc123+'.isalnum()
False
''.isalnum()
False
9.10 str.isalpha()
如果字符串中的所有字符都是字母,并且至少有一个字符,返回 True ,否则返回 False 。字母字符是指那些在 Unicode 字符数据库中定义为 "Letter" 的字符,即那些具有 "Lm"、"Lt"、"Lu"、"Ll" 或 "Lo" 之一的通用类别属性的字符。 注意,这与 Unicode 标准中定义的"字母"属性不同。
'abcdef'.isalpha()
True
'abcdef0'.isalpha()
False
'abcdef+'.isalpha()
False
''.isalpha()
False
'AAABBBcccc'.isalpha()
True
9.11 str.isascii()
如果字符串为空或字符串中的所有字符都是 ASCII ,返回 True ,否则返回 False 。ASCII 字符的码点范围是 U+0000-U+007F 。
'abc.AAABNBZZZ^#.~!@#$%^&*()_+'.isascii()
True
'abc.AAABNBZZZ^#.~!@#$%^&*()_+中文'.isascii()
False
9.12 str.isdecimal()
如果字符串中的所有字符都是十进制字符且该字符串至少有一个字符,则返回 True , 否则返回 False 。十进制字符指那些可以用来组成10进制数字的字符,例如 U+0660 ,即阿拉伯字母数字0 。 严格地讲,十进制字符是 Unicode 通用类别 "Nd" 中的一个字符。
'10'.isdecimal()
True
'10.11111'.isdecimal()
False
9.13 str.isdigit()
如果字符串中的所有字符都是数字,并且至少有一个字符,返回 True ,否则返回 False 。 数字包括十进制字符和需要特殊处理的数字,如兼容性上标数字。这包括了不能用来组成 10 进制数的数字,如 Kharosthi 数。 严格地讲,数字是指属性值为 Numeric_Type=Digit 或 Numeric_Type=Decimal 的字符。
'3333'.isdigit()
True
'0x99'.isdigit()
9.14 str.isidentifier()
如果字符串是有效的标识符,返回 True ,依据语言定义, 标识符和关键字 节。
调用 keyword.iskeyword() 来检测字符串 s 是否为保留标识符,例如 def 和 class。
示例:
# 例子1
>>>
>>> from keyword import iskeyword
>>> 'hello'.isidentifier(), iskeyword('hello')
(True, False)
>>> 'def'.isidentifier(), iskeyword('def')
(True, True)
# 例子2
'get_res_func'.isidentifier()
True
'00get_res_func'.isidentifier()
False
# 例子3:
from keyword import iskeyword
iskeyword('hello')
False
iskeyword('list')
False
iskeyword('from')
True
iskeyword('import')
True
9.15str.islower()
如果字符串中至少有一个区分大小写的字符,且此类字符均为小写则返回 True ,否则返回 False 。
'abcceeeeeeffff'.islower()
True
'abcceeeeeeffffAAAAABBBBCCC'.islower()
False
'abcceeeeeeffff...'.islower()
True
''.islower()
False
9.16 str.isnumeric()
如果字符串中至少有一个字符且所有字符均为数值字符则返回 True ,否则返回 False 。 数值字符包括数字字符,以及所有在 Unicode 中设置了数值特性属性的字符,例如 U+2155, VULGAR FRACTION ONE FIFTH。 正式的定义为:数值字符就是具有特征属性值 Numeric_Type=Digit, Numeric_Type=Decimal 或 Numeric_Type=Numeric 的字符。
对于 Unicode 数字、全角数字(双字节)、罗马数字和汉字数字会返回 True ,其他会返回 False。byte数字(单字节)无此方法。
u'11221'.isnumeric()
True
u'Ⅷ'.isnumeric()
True
u'11221one'.isnumeric()
False
u'1.1223'.isnumeric()
False
9.17 str.isprintable()
如果字符串中所有字符均为可打印字符或字符串为空则返回 True ,否则返回 False 。 不可打印字符是在 Unicode 字符数据库中被定义为 "Other" 或 "Separator" 的字符,例外情况是 ASCII 空格字符 (0x20) 被视作可打印字符。 (请注意在此语境下可打印字符是指当对一个字符串发起调用 repr() 时不必被转义的字符。 它们与字符串写入 sys.stdout 或 sys.stderr 时所需的处理无关。)
9.18 str.isspace()
如果字符串中只有空白字符且至少有一个字符则返回 True ,否则返回 False 。
空白 字符是指在 Unicode 字符数据库 (参见 unicodedata) 中主要类别为 Zs ("Separator, space") 或所属双向类为 WS, B 或 S 的字符。
''.isspace()
False
' aaa bbb '.isspace()
False
' '.isspace()
True
9.18 str.istitle()
如果字符串中至少有一个字符且为标题字符串则返回 True ,例如大写字符之后只能带非大写字符而小写字符必须有大写字符打头。 否则返回 False 。
'this is a desk'.title()
'This Is A Desk'
s = 'this is a desk!'
'this is a desk'.istitle()
False
'This is a desk'.istitle()
False
'This Is A Desk'.istitle()
True
'ThiS Is A Desk'.istitle()
False
9.19 str.isupper()
如果字符串中至少有一个区分大小写的字符 且此类字符均为大写则返回 True ,否则返回 False 。
全部为大写,则为True,否则为False
'Her name is Lucy!'.isupper()
False
'HER NAME IS LUCY'.isupper()
True
延申,如何找出一个字符中的所有大写\小写的字符?
s = 'This is a cloudy day ,I like Chiness Food!'
# 方法一:
res = []
for i in s:
if i.isupper():
res.append(i)
print(f'方法一res:{res}')
# 方法二:
import re
re_pattern = r'.?([A-Z]).?'
res = re.findall(re_pattern,s)
print(f'方法二res:{res}')
输出的结果:
方法一res:['T', 'I', 'C', 'F']
方法二res:['T', 'I', 'C', 'F']
9.20 str.join(iterable)
返回一个由 iterable 中的字符串拼接而成的字符串。 如果 iterable 中存在任何非字符串值包括 bytes 对象则会引发 TypeError。 调用该方法的字符串将作为元素之间的分隔。
l = [str(i) for i in range(0,11)]
l
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10']
'x'.join(l)
'0x1x2x3x4x5x6x7x8x9x10'
9.21 str.ljust(width[, fillchar])
为格式化字符串的操作,原来字符串左对齐,并且根据给定的width进行填充,默认是空格填充,可以指定fillchar字符。
返回长度为 width 的字符串,原字符串在其中靠左对齐。 使用指定的 fillchar 填充空位 (默认使用 ASCII 空格符)。 如果 width 小于等于 len(s) 则返回原字符串的副本。
'apple'.ljust(10)
'apple '
'apple'.ljust(10,'#')
'apple#####'
如果width小于字符串长度,则返回原字符串。
'apple'.ljust(2)
'apple'
s
'banana'
r = s.ljust(2)
r is s
True
fillchar只能是一个字符串,否者抛出异常:TypeError: The fill character must be exactly one character long
s
'banana'
s.ljust(10,'##')
Traceback (most recent call last):
File "C:\Program Files\Python310\lib\code.py", line 90, in runcode
exec(code, self.locals)
File "<input>", line 1, in <module>
TypeError: The fill character must be exactly one character long
9.22 str.lower()
返回原字符串的副本,其所有区分大小写的字符 4 均转换为小写。
所用转换小写算法的描述请参见 Unicode 标准的 3.13 节。
'AdfajAdjfiodfhJoef6612379321789...++'.lower()
'adfajadjfiodfhjoef6612379321789...++'
9.23 str.lstrip([chars])
返回原字符串的副本,移除其中的前导字符。 chars 参数为指定要移除字符的字符串。 如果省略或为 None,则 chars 参数默认移除空白符。 实际上 chars 参数并非指定单个前缀;而是会移除参数值的所有组合:
'www.baidu.com'.lstrip('w')
'.baidu.com'
'http://www.google.com'.lstrip('htp')
'://www.google.com'
如果不想移除组合,则可以用 str.removeprefix() 方法
'http://www.baidu.com'.removeprefix('ht')
'tp://www.baidu.com'
9.24 str.translate(table)
返回原字符串的副本,其中每个字符按给定的转换表进行映射。 转换表必须是一个使用 getitem() 来实现索引操作的对象,通常为 mapping 或 sequence。 当以 Unicode 码位序号(整数)为索引时,转换表对象可以做以下任何一种操作:返回 Unicode 序号或字符串,将字符映射为一个或多个字符;返回 None,将字符从结果字符串中删除;或引发 LookupError 异常,将字符映射为其自身。
你可以使用 str.maketrans() 基于不同格式的字符到字符映射来创建一个转换映射表。另请参阅 codecs 模块以了解定制字符映射的更灵活方式。
可以使用str.maketrans()方法来制作一个对照表
9.24.1 static str.maketrans(x[, y[, z]])
此静态方法返回一个可供 str.translate() 使用的转换对照表。
如果只有一个参数,则它必须是一个将 Unicode 码位序号(整数)或字符(长度为 1 的字符串)映射到 Unicode 码位序号、(任意长度的)字符串或 None 的字典。 字符键将会被转换为码位序号。
1、如果有两个参数,则它们必须是两个长度相等的字符串,并且在结果字典中,x 中每个字符将被映射到 y 中相同位置的字符。
2、如果有第三个参数,它必须是一个字符串,其中的字符将在结果中被映射到 None。
s = 'I have a cat and a blue dog'
intab = 'abcd'
outtab = '1234'
# 生成翻译表
trans_tab = str.maketrans(intab,outtab)
print(trans_tab)
# 执行翻译
r = s.translate(trans_tab)
print(r)
输出:
{97: 49, 98: 50, 99: 51, 100: 52}
I h1ve 1 31t 1n4 1 2lue 4og
9.24.2 翻译的过程中过滤部分字符
在maketrans()方法中,第3个参数用于筛选字符,可以看出第3个参数的内容,并映射成了None
s = 'I have a cat and a blue dog'
intab = 'abcd'
outtab = '1234'
delete_tab = 'ug'
# 生成翻译表
trans_tab = str.maketrans(intab,outtab,delete_tab)
print(trans_tab)
# 执行翻译
r = s.translate(trans_tab)
print(r)
输出:
{97: 49, 98: 50, 99: 51, 100: 52, 117: None, 103: None}
I h1ve 1 31t 1n4 1 2le 4o
9.25 str.partition(sep)
在 sep 首次出现的位置拆分字符串,返回一个 3 元组,其中包含分隔符之前的部分、分隔符本身,以及分隔符之后的部分。 如果分隔符未找到,则返回的 3 元组中包含字符本身以及两个空字符串。
s = 'www.google.com'
s.partition('.')
('www', '.', 'google.com')
s.partition('-')
('www.google.com', '', '')
9.26 str.removeprefix(prefix, /)
如果字符串以 前缀 字符串开头,返回 string[len(prefix):] 。否则,返回原始字符串的副本:
s = 'Today is a nice day!'
# 移除Tod的前缀
s.removeprefix('Tod')
'ay is a nice day!'
# 移除不存在的gg开头的前缀,返回原字符串
s.removeprefix('gg')
'Today is a nice day!'
9.27 str.removesuffix(suffix, /)
如果字符串以 后缀 字符串结尾,并且 后缀 非空,返回 string[:-len(suffix)] 。否则,返回原始字符串的副本:
'Today is a nice day!'
s.removesuffix('day')
'Today is a nice day!'
s.removesuffix('day!')
'Today is a nice '
9.28 str.replace(old, new[, count])
返回字符串的副本,其中出现的所有子字符串 old 都将被替换为 new。 如果给出了可选参数 count,则只替换前 count 次出现。
s = 'www.3woogw.com'
# 不指定替换的次数
s.replace('w','r')
'rrr.3roogr.com'
# 指定替换的次数
s.replace('w','x',2)
'xxw.3woogw.com'
9.29 str.rfind(sub[, start[, end]])
返回子字符串 sub 在字符串内被找到的最大(最右)索引,这样 sub 将包含在 s[start:end] 当中。 可选参数 start 与 end 会被解读为切片表示法。 如果未找到则返回 -1。
s
'www.3woogw.com'
s.rfind('o')
12
s.rfind('x')
-1
s.index('o')
9.30 str.rindex(sub[, start[, end]])
类似于 rfind(),但在子字符串 sub 未找到时会引发 ValueError。
9.31 str.rjust(width[, fillchar])
返回长度为 width 的字符串,原字符串在其中靠右对齐。 使用指定的 fillchar 填充空位 (默认使用 ASCII 空格符)。 如果 width 小于等于 len(s) 则返回原字符串的副本。
9.32 str.rpartition(sep)
在 sep 最后一次出现的位置拆分字符串,返回一个 3 元组,其中包含分隔符之前的部分、分隔符本身,以及分隔符之后的部分。 如果分隔符未找到,则返回的 3 元组中包含两个空字符串以及字符串本身。
9.33 str.rsplit(sep=None, maxsplit=- 1)
返回一个由字符串内单词组成的列表,使用 sep 作为分隔字符串。 如果给出了 maxsplit,则最多进行 maxsplit 次拆分,从 最右边 开始。 如果 sep 未指定或为 None,任何空白字符串都会被作为分隔符。 除了从右边开始拆分,rsplit() 的其他行为都类似于下文所述的 split()。
9.34 str.rstrip([chars])
返回原字符串的副本,移除其中的末尾字符。 chars 参数为指定要移除字符的字符串。 如果省略或为 None,则 chars 参数默认移除空白符。 实际上 chars 参数并非指定单个后缀;而是会移除参数值的所有组合:
>>>
>>> ' spacious '.rstrip()
' spacious'
>>> 'mississippi'.rstrip('ipz')
'mississ'
要删除单个后缀字符串,而不是全部给定集合中的字符,请参见 str.removesuffix() 方法。 例如:
>>>
>>> 'Monty Python'.rstrip(' Python')
'M'
>>> 'Monty Python'.removesuffix(' Python')
'Monty'
9.35 str.split(sep=None, maxsplit=- 1)
返回一个由字符串内单词组成的列表,使用 sep 作为分隔字符串。 如果给出了 maxsplit,则最多进行 maxsplit 次拆分(因此,列表最多会有 maxsplit+1 个元素)。 如果 maxsplit 未指定或为 -1,则不限制拆分次数(进行所有可能的拆分)。
如果给出了 sep,则连续的分隔符不会被组合在一起而是被视为分隔空字符串 (例如 '1,,2'.split(',') 将返回 ['1', '', '2'])。 sep 参数可能由多个字符组成 (例如 '1<>2<>3'.split('<>') 将返回 ['1', '2', '3'])。 使用指定的分隔符拆分空字符串将返回 ['']。
例如:
>>>
>>> '1,2,3'.split(',')
['1', '2', '3']
>>> '1,2,3'.split(',', maxsplit=1)
['1', '2,3']
>>> '1,2,,3,'.split(',')
['1', '2', '', '3', '']
如果 sep 未指定或为 None,则会应用另一种拆分算法:连续的空格会被视为单个分隔符,其结果将不包含开头或末尾的空字符串,如果字符串包含前缀或后缀空格的话。 因此,使用 None 拆分空字符串或仅包含空格的字符串将返回 []。
例如:
>>>
>>> '1 2 3'.split()
['1', '2', '3']
>>> '1 2 3'.split(maxsplit=1)
['1', '2 3']
>>> ' 1 2 3 '.split()
['1', '2', '3']
例如:
s
'1 2 3 4 5 6'
s.split()
['1', '2', '3', '4', '5', '6']
9.36 str.splitlines(keepends=False)
返回由原字符串中各行组成的列表,在行边界的位置拆分。 结果列表中不包含行边界,除非给出了 keepends 且为真值。
此方法会以下列行边界进行拆分。 特别地,行边界是 universal newlines 的一个超集。
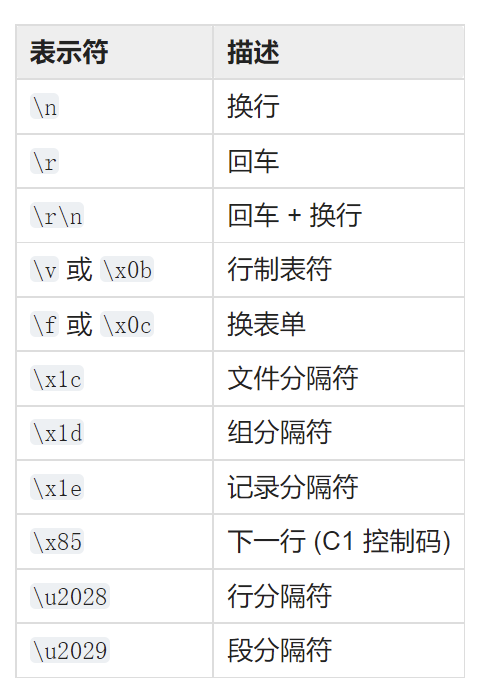
在 3.2 版更改: \v 和 \f 被添加到行边界列表
例如:
>>>
>>> 'ab c\n\nde fg\rkl\r\n'.splitlines()
['ab c', '', 'de fg', 'kl']
>>> 'ab c\n\nde fg\rkl\r\n'.splitlines(keepends=True)
['ab c\n', '\n', 'de fg\r', 'kl\r\n']
不同于 split(),当给出了分隔字符串 sep 时,对于空字符串此方法将返回一个空列表,而末尾的换行不会令结果中增加额外的行:
>>>
>>> "".splitlines()
[]
>>> "One line\n".splitlines()
['One line']
作为比较,split('\n') 的结果为:
>>>
>>> ''.split('\n')
['']
>>> 'Two lines\n'.split('\n')
['Two lines', '']
详细的用法可以直接参考中文文档;
https://docs.python.org/zh-cn/3/library/stdtypes.html#text-sequence-type-str

 浙公网安备 33010602011771号
浙公网安备 33010602011771号