
数据分析英国电商——数据分析可视化
# 订单维度 # 首先将mydata_finall按订单号进行分组,对商品数量quantity和总价sumcost进行分组求和 invoiceno_grouped = mydata_finall.groupby('InvoiceNo')[['Quantity','SumCost']].sum() invoiceno_grouped.describe() # 根据得到的结果可以发现,均单有279件商品,说明订单多以批发为主,订单均值超过均值, # 说明订单总体差异较大,存在购买力极强的用户,这些用户应该得到重点关注 Quantity SumCost count 19960.000000 19960.000000 mean 279.179359 533.171884 std 955.011810 1780.412288 min 1.000000 0.380000 25% 69.000000 151.695000 50% 150.000000 303.300000 75% 296.000000 493.462500 max 80995.000000 168469.600000 y = invoiceno_grouped[invoiceno_grouped.Quantity <2000]['Quantity'] sns.distplot(y,bins = 50,color="b", kde = False) plt.title("Quantity Distribtion Of Orders (Below 2000)") plt.ylabel('Frequency') plt.xlabel("Quantity") plt.show()
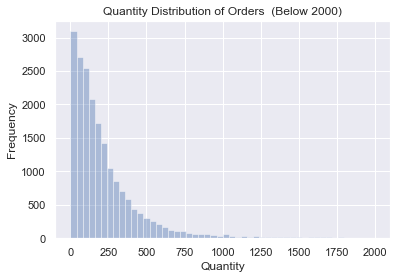
#订单内的商品数量呈现出很典型的长尾分布,大部分订单的商品数量在250件内,商品数量越多,订单数相对越少
#绘制订单金额的分布
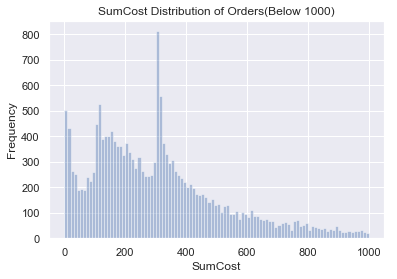
#可以看到订单额集中在500以内,而350有一个峰值。
#客户维度
#由于之前在清洗数据的时候把很多nan替换成0,所以客户id为零的实际不能分析出太多东西,所以仅针对customerid不为0的进行分析
sales_useful = sales_normal[sales_normal.CustomerID != 0].copy()
#对客户id和订单编号进行分组,索引会发生变化,所以重设索引,然后对同笔订单的金额和数量进行求和,然后在按照customerid分组展示
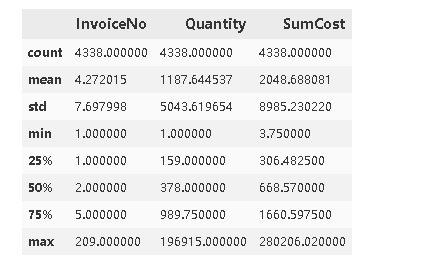
#通过这个描述性统计我们可以得到人均购买4笔同一种商品,25%的客户买完意见商品以后就没有留存下来,人均购买1187件商品,甚至超过了Q3的购买量,最多购买196915件商品,人均消费4338英镑,也同样超过了Q3,最多消费280206英镑。
#消费金额分布(分组以后的金额)
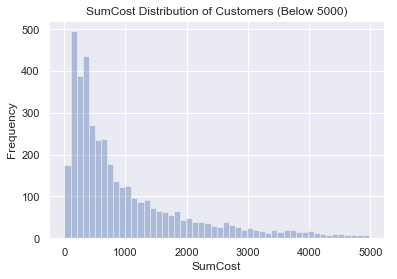
#通过这个图像我们可以发现的订单金额相对集中,大多在1000以内。
#商品维度
#商品对应的是stackcode,发现不同客户购买同一商品的价格不一致
#下边就是要考虑商品的平均价格,商品的平均价格要按照商品来分组,然后求和Quantity和Sumcost,然后再用求和以后的SumCost 除以Quantity
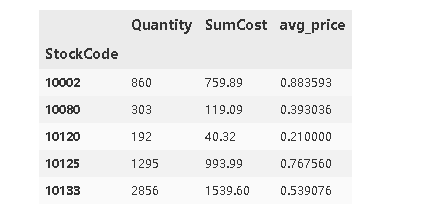
#查看价格分布
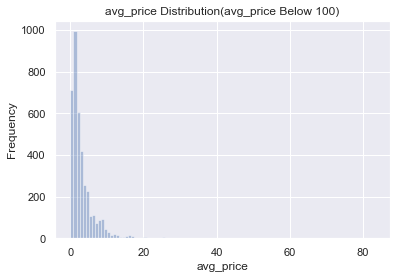
# 能够看到绝大多数的商品价格在20英镑以内,可知该网站销售的商品大多是价格比较低的
果然无论是哪个国家的人民都更偏向于低价商品,低价商品在成交量以及成交金额上面都是占据了非常大的部分,而价格较高的商品的销量远低于低价商品,那么可以进一步把平台作为一个走量的平台,就如唯品会。
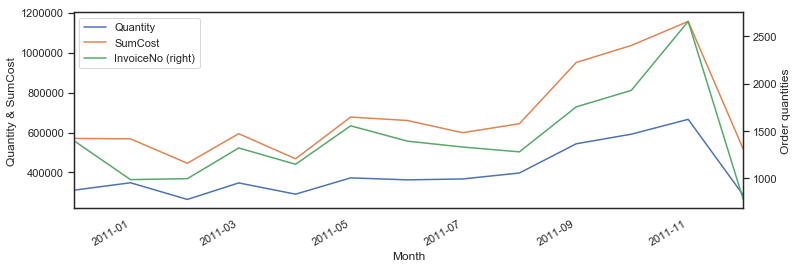
#时间维度
#按照有效订单分组
#区域维度
#对于区域维度的处理主要是按照客户id和国家分类,然后在把两张表合并在一起
#提取客户id和国家关系表 sales_country = sales_normal.drop_duplicates(subset=['CustomerID','Country'])
按客户分组,然后计算总金额
country_grouped = sales_useful.groupby('CustomerID')[['SumCost']].sum()
两张表合并
country_grouped = country_grouped.merge(sales_country,on=['CustomerID'])
合并以后按照国家在分组,计算消费金额和客户总数
country_grouped.head()
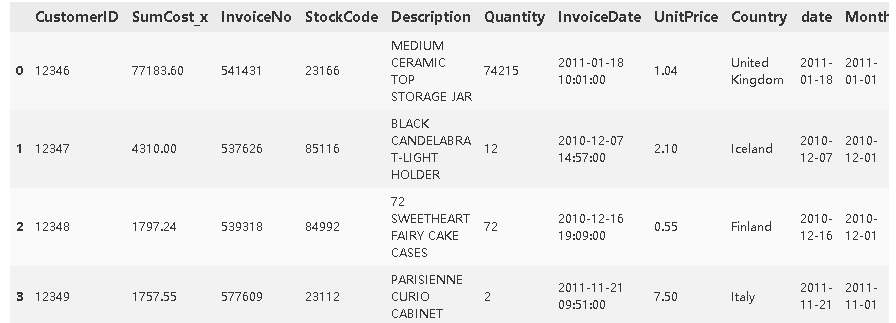
发现这里的sumcost已经变成了sumcost_x,重命名
country_grouped.rename(columns={'SumCost_x':'SumCost'},inplace=True) country_grouped.head()
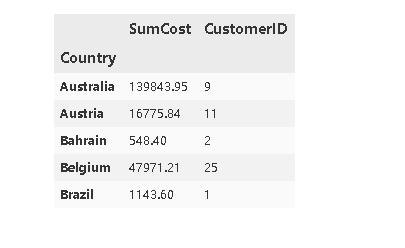
为这个数据集添加一个新的字段,即avgamount 即人均消费。avg_amount = sumcost/cutomerid
country_grouped['avg_amount'] = country_grouped['SumCost']/country_grouped['CustomerID']
country_grouped.head(30)
![]()

这里可以发现除了英国以外其他国家的购买人数都很少
我们来按照avg_amount从大到小排列一下
country_grouped.sort_values(by='avg_amount',ascending=False).head(20)
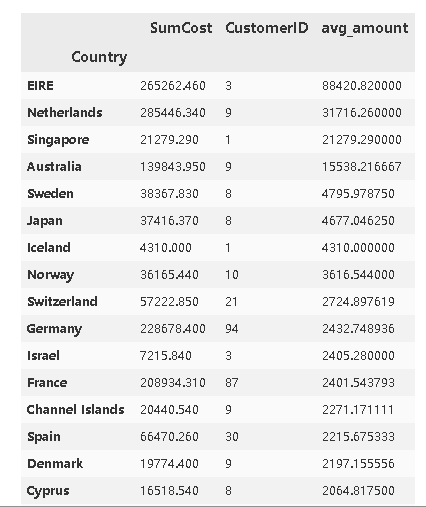
能够看到虽然其他国家购买人数较少,但是人均购买量很可观,可以考虑吧筛选出具体的客户id然后取得联习给予适当的优惠和配备专属客服。
#生命周期
我们知道一个网站能够长久的生存下去,那么客户的生命周期是一个很重要的因素。
由于该数据集的统计对象为2010年12月1日至2011年12月9日的全部订单,所以我们就只能统计这一段时间内的消费情况
首先筛选出id为0的客户
sales_useful = sales_normal[sales_normal.CustomerID != 0].copy()
按照客户id分组,然后找到客户第一次购买和最后一次购买的时间差
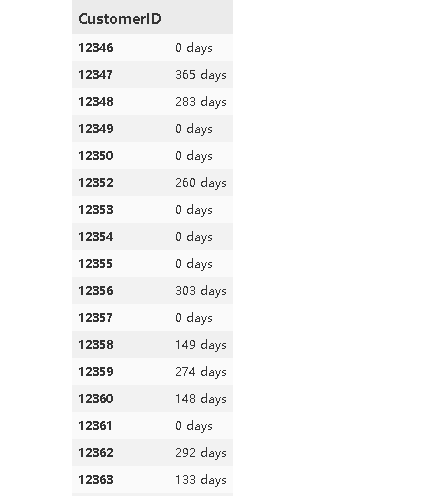
可以看到好多的留存天数很多还是天数是0天,0天代表的是没有留存。
lifetime = max_date - min_date lifetime.describe()
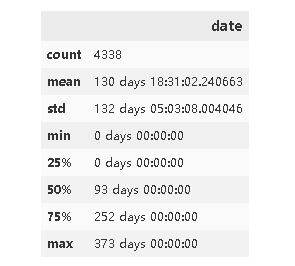
由于这个timedelta的类型不能绘制图形,所以转换成datetime的形式
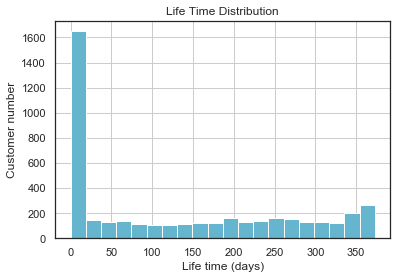
可以看到绝大多数都是没有留存,可以考虑增加购买初体验。而且发现在350天左右又有了一个新的高峰
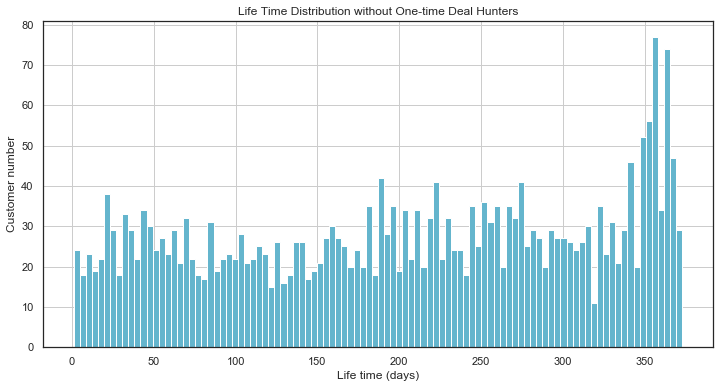
结论:
- 订单维度:该电商网站在2010年12月1日-2011年12月9日内共产生有效订单19960笔,笔单价为533.17英镑,人均购买约279件商品,说明用户群体多以批发商为主,且订单交易金额和订单内商品件数,其均值都高于中位数;订单交易金额的均值甚至高于Q3分位数。说明订单总体差异大,存在部分购买力极强的客户
- 客户维度:通过这个描述性统计我们可以得到人均购买4笔同一种商品,25%的客户买完意见商品以后就没有留存下来,人均购买1187件商品,甚至超过了Q3的购买量,最多购买196915件商品,人均消费4338英镑,也同样超过了Q3,最多消费280206英镑
- 商品维度:能够看到绝大多数的商品价格在20英镑以内,可知该网站销售的商品大多是价格比较低的,且价格越低对应的购买量越高,商品整体是较低价的平民商品
- 时间维度:总共有4338个客户,平均留存时间130days,最小值是0天就是没有留存,前25%是0天说明有4分之一的用户是直接流失掉的,50%是93天,说明平均流失时间为93天,可以考虑在90天左右给予优惠促使客户完成购买然后留存下来,前75%是252天,最多的是留存373天。生命周期呈现两极分化的状态。
- 区域维度:绝大多数的客户是来自英国本土,其他国家的客户较少,但是却多为优质客户,可以对这些客户进行深挖予以物流上面的支持

 浙公网安备 33010602011771号
浙公网安备 33010602011771号