
FSRNet: End-to-End Learning Face Super-Resolution with Facial Priors论文阅读
这篇文章 FSRNet: End-to-End Learning Face Super-Resolution with Facial Priors 是 CVPR 2018 的文章
一、动机
以往利用人脸先验的人脸SR方法都采用多阶段训练策略,而不是端到端训练策略,不方便且复杂。基于CNN,我们提出了FSRNet
二、论文的贡献
1)据我们所知,这是第一个利用面部几何先验进行的端到端训练的深度人脸超分辨率网络。
2)同时介绍了两种人脸几何先验方法:人脸特征点热图(facial landmark heatmaps )和解析图( parsing maps)
3)The proposed FSRNet achieves the state of the artwhen hallucinating unaligned and very low-resolution (16×16 pixels) face images by an upscaling factor of 8, and the extended FSRGAN further generates more realistic faces.
4)采用人脸对齐和解析作为新的人脸超分辨评价指标,进一步证明了该指标解决了传统指标与视觉感知不一致的问题。
三、论文模型: Face Super-Resolution Network
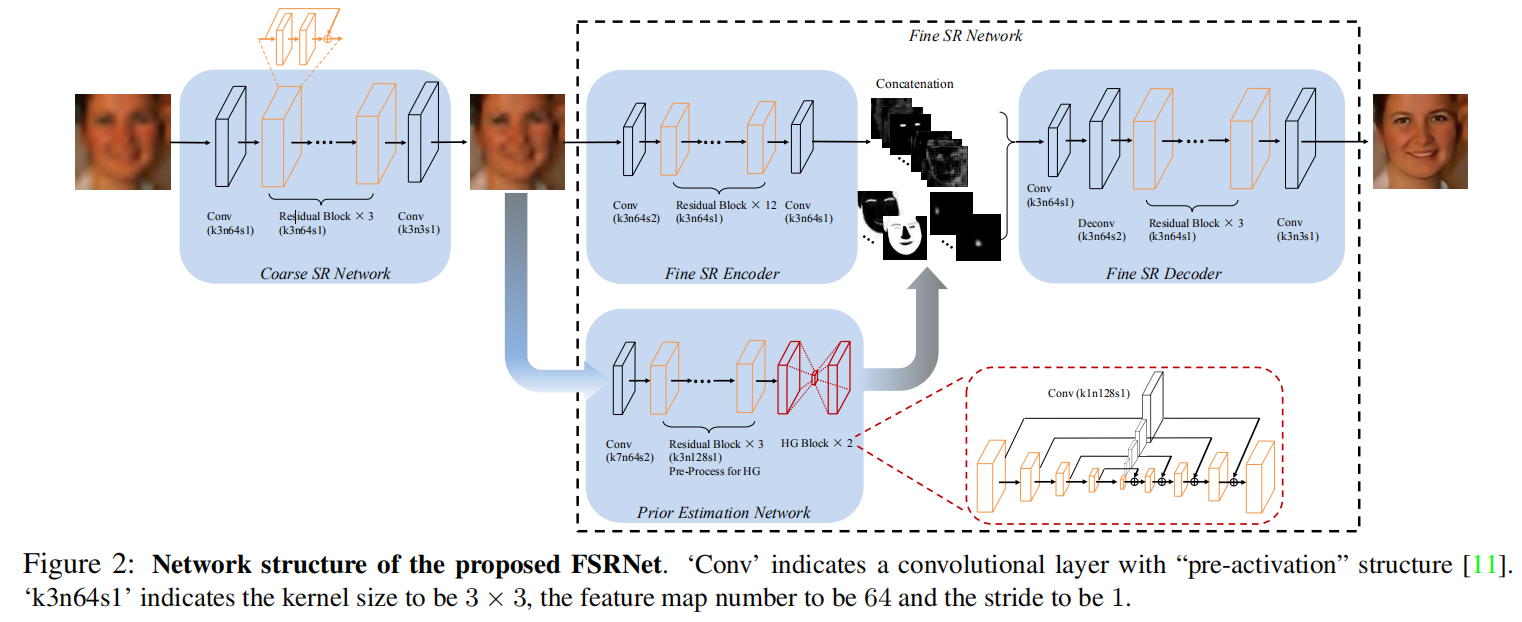
3.1 Overview of FSRNet
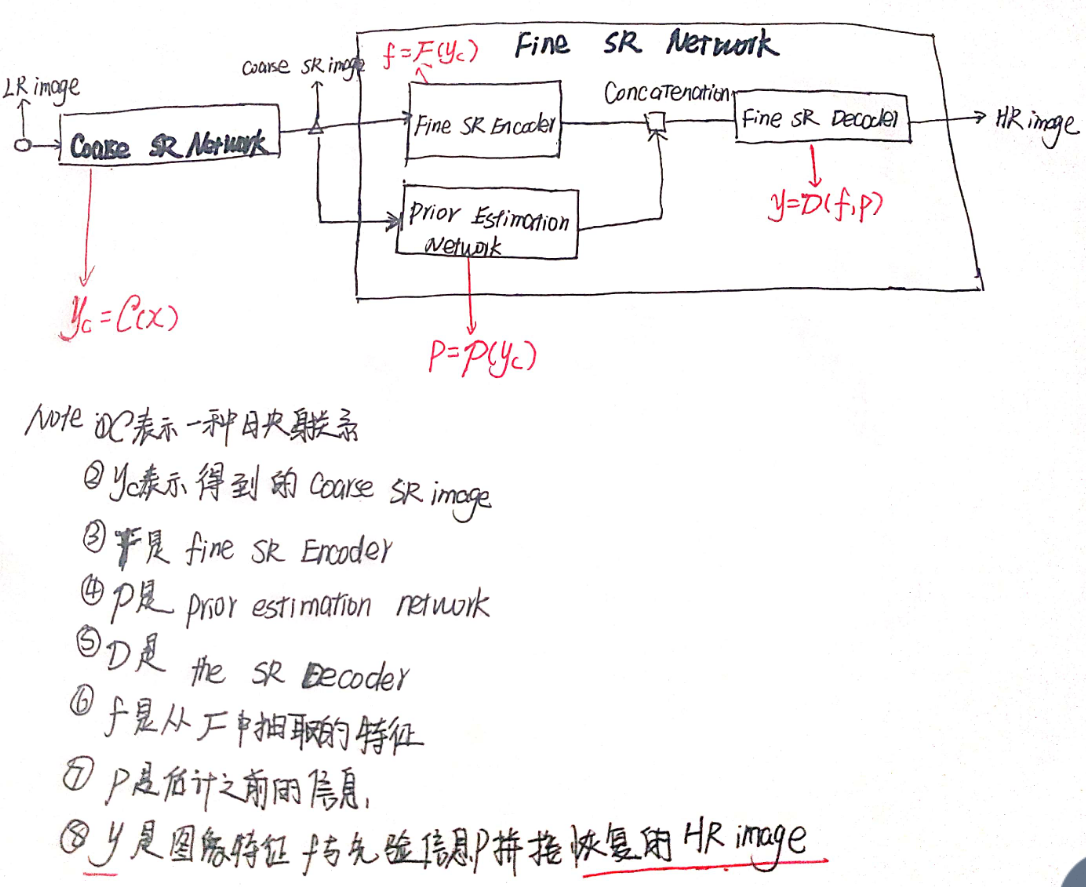
我们的基本FSRNet F由四部分组成: 粗SR网络、精SR编码器、先验估计网络和最终的精SR解码器。
一个低分辨率的人脸图片x作为输入,经过coarse SR Network 恢复出一个coarse SR image。然后这个coarse SR image被送入到Fine SR Network中,作为Fine SR Encoder和Prior Estimation Network 的输入图片。在Fine SR Network中从coarse SR image中提取特征,而Prior Estimation Network 通过多任务学习共同估计先验信息:特征点热图(landmark heatmaps )和解析图(parsing maps)。最后将图像特征和人脸先验知识输入到精密的SR解码器中,恢复出精确的HR人脸。
3.2 Coarse SR network

k3n64s1:kernel size:3×3,number of channels:64,stride:1
首先,作者使用 a coarse SR network 来大致的恢复出一个粗糙的HR 图片。这样做的动机是,直接从一个LR图片估计人脸特征点的位置和解析图(parsing maps)具有很大的困难。使用coarse SR network 有助于减轻估计先验的困难。粗SR网络的体系结构如上图所示。它以一个3×3的卷积开始后面跟着3个残差块。然后再使用3×3卷积层重建粗糙的HR图像
3.3 Fine SR Network
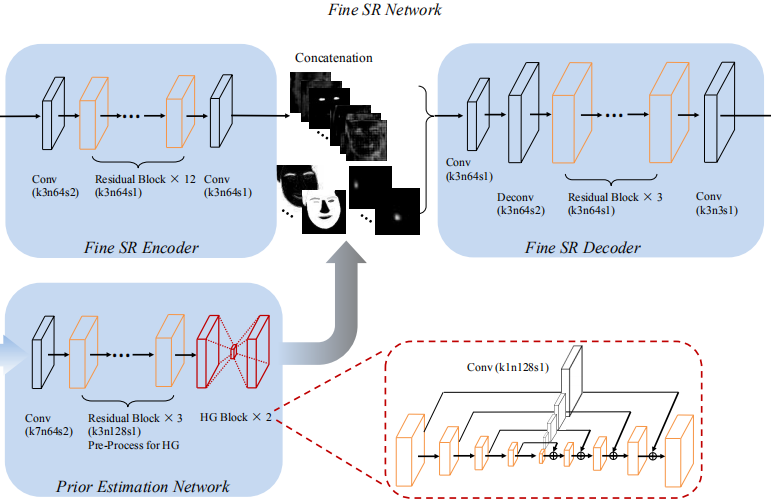
在上面的精细SR网络中,将粗糙的HR图像发送给两个分支,即先验估计网络和精细的SR编码器中,分别用于估计人脸先验和提取特征。然后,解码器联合使用这两个分支的结果来恢复较好的HR图像
3.4Prior Estimation Network
任何真实世界的物体在它的形状和纹理上都有不同的分布,包括脸。通过将面部形状与纹理进行比较,我们首先考虑了两方面的因素,选择对形状进行建模和利用。第一,当分辨率由高到低的时候,形状比纹理保存的更好,因此更容易被提取出来,实现超分辨率。第二,形状先验比纹理先验更容易表示。例如,面部解析估计不同面部成分的分割,特征点提供面部关键点的准确位置,即使在低分辨率情况下。而且对于一个特定的人脸,如何表示高维的纹理先验是不清楚。
受最近叠加热图回归在人体姿态估计中的成功启发,在先验估计网路中,我们采用沙漏(HG)结构来估计人脸特征点热图和解析图。由于这两个先验都代表二维的脸型,所以在我们的先验估计网络中,除了最后一层之外,这两个任务之间的特征都是共享的。为了有效地跨尺度合并特征并保存不同尺度的空间信息, HG块(hourglass block )在对称层之间使用了跳跃连接机制(a skip connection mechanism)。采用1×1卷积层对得到的特征进行后处理。最后,将共享的 HG特征连接到两个单独的1×1卷积层,生成特征点热图和解析图
3.5Fine SR Encoder
对于精细的SR编码器,受ResNet在SR中的成功启发,我们利用残差块进行特征提取。考虑到计算代价,我们的先验特征的大小被降采样为64×64。为了使feature size一致,fine SR编码器从stride 2的3×3卷积层开始,将feature map向下采样到64×64。然后利用ResNet结构提取图像特征。
3.6Fine SR Decoder
精细SR解码器联合使用特征和先验来恢复最终的精细HR图像。第一步,将先验特征p和图像特征f串联作为解码器的输入。然后,一个3×3的卷积层将feature maps的数量减少到64。利用4×4反卷积层将feature map上采样到128×128。然后利用3个残差块对特征进行解码。最后,使用3×3卷积层恢复较好的HR图像。
3.7 loss function
、
Θ表示参数集,α和β表示 the coarse SR loss and prior loss 的权重。y (i), p (i)分别为恢复的第i幅HR图像和估计的第i幅图像的先验信息。
FSRGAN
为了生成逼真的高分辨率人脸,我们的模型以条件方式利用GAN。对抗网络C的目标函数表示为

论文的创新
利用人脸的先验信息(即facial landmark heatmaps and parsing maps)来进行端到端训练的人脸超分变率网络。【有很多人使用人脸的先验信息做人脸超分,也有很多人使用端到端的训练做人脸超分,但是没有人把这两种方式结合起来用】
下一步工作或论文的不足之处
1.设计一个更好的先验信息估计网络。 (在该论文中用了好多对比实验证明了先验信息的重要性)
2.迭代地学习精细的SR网络。
3.调研其他有用的脸部先验信息。
4.FSR网络框架中的 Prior Estimation Network和 Fine SR Encoder中的模块作用论文中写的不够清楚

 浙公网安备 33010602011771号
浙公网安备 33010602011771号