

SVM -支持向量机原理详解与实践之三
SVM -支持向量机原理详解与实践之三
-
什么是核
什么是核,核其实就是一种特殊的函数,更确切的说是核技巧(Kernel trick),清楚的明白这一点很重要。
为什么说是核技巧呢?回顾到我们的对偶问题:
|
|
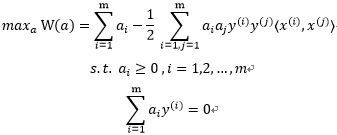
映射到特征空间后约束条件不变,则为:
|
|
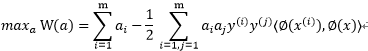
在原始特征空间中主要是求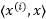 ,也就是
,也就是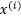 和
和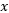 的内积(Inner Product)
的内积(Inner Product)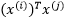 ,也称数量积(Scalar Product)或是点积(Dot Product),映射到特征空间后就变成了求
,也称数量积(Scalar Product)或是点积(Dot Product),映射到特征空间后就变成了求 ,也就是
,也就是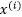 和
和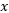 的映射到特征空间之后的内积,就如我前面所提到的在原始空间样本线性不可分,但是映射到高维后可以得到一个线性可分的决策曲面,但是我们假如映射到的这个维度很高,甚至是无穷维怎么办?映射到高维空间后计算量无疑很大,但是运用核后计算量将大大降低,这就是为什么我们说核为核技巧。
的映射到特征空间之后的内积,就如我前面所提到的在原始空间样本线性不可分,但是映射到高维后可以得到一个线性可分的决策曲面,但是我们假如映射到的这个维度很高,甚至是无穷维怎么办?映射到高维空间后计算量无疑很大,但是运用核后计算量将大大降低,这就是为什么我们说核为核技巧。
下面我们举个例子可以更为直观的看到在原始样本空间映射到高维空间后运算量为什么会很大,而运用核函数或是核技巧后计算量会大大降低。
设向量A = [a1,a2,a3];B = [b1,b2,b3];
则向量A和B的内积表示为:
A·B=a1×b1+a2×b2+a3×b3;
而映射到了特征空间后的 分别为:
分别为:
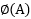 = (a1*a1, a1*a2, a1*a3, a2*a1, a2*a2, a2*a3, a3*a1, a3*a2, a3*a3)
= (a1*a1, a1*a2, a1*a3, a2*a1, a2*a2, a2*a3, a3*a1, a3*a2, a3*a3)
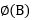 = (b1*b1, b1*b2, b1*b3, b2*b1, b2*b2, b2*b3, b3*b1, b3*b2, b3*b3)
= (b1*b1, b1*b2, b1*b3, b2*b1, b2*b2, b2*b3, b3*b1, b3*b2, b3*b3)
假设实数向量:A = [1,2,3];B = [2,3,4];
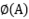 = (1, 2, 3, 2, 4, 6, 3, 6, 9)
= (1, 2, 3, 2, 4, 6, 3, 6, 9)
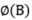 = (4, 6, 8, 6, 9, 12, 8, 12, 16)
= (4, 6, 8, 6, 9, 12, 8, 12, 16)
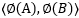 = 4 + 12 + 24 + 12 + 36 + 72 + 24 + 72 + 144 = 400;
= 4 + 12 + 24 + 12 + 36 + 72 + 24 + 72 + 144 = 400;
我们会发现三维的运算已经很繁琐,如果更高维呢,运算量无疑大大增加,但是如果我们引入核函数:
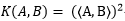
再做计算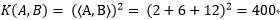
我们发现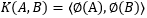 ,但是
,但是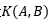 的计算要简便得多。
的计算要简便得多。
下面我们给出核的定义:
假如原始的内积形式是 ,给定一个特征映射
,给定一个特征映射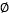 ,映射之后的内积形式则为
,映射之后的内积形式则为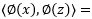
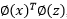 ,所以我们将相应的核定义为:
,所以我们将相应的核定义为:
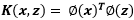
以上的核函数我们称为内积核,或者简称核。
-
核函数选择
通过前面这个简单的例子我们知道了核的用途,就是将特征空间庞大运算量问题(或者说无法计算的问题)通过核技巧转化为低维空间可计算的问题。
我们前面的例子比较简单,我们可以手工构造对应于映射 的核函数出来,但如果对于任意一个映射,想要构造出对应的核函数出来那就困难了,或者换句话说几乎不可能,所以概括的说解决现实的问题时我们会遇到以下两个问题:
的核函数出来,但如果对于任意一个映射,想要构造出对应的核函数出来那就困难了,或者换句话说几乎不可能,所以概括的说解决现实的问题时我们会遇到以下两个问题:
- 想要找到将具体样本数据和分布映射到高维实现线性可分的映射函数
![]() 很难
很难
- 计算出核函数
![]() 很难,或是几乎不可能。
很难,或是几乎不可能。
 很难,或是几乎不可能。
很难,或是几乎不可能。根据上面的例子我们看到运用核函数 我们可以不用确切的知道
我们可以不用确切的知道 同样可以得到和
同样可以得到和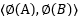 一致的结果,所以
一致的结果,所以 可以不用知道具体形式,现在就剩下一个问题: 这个核函数
可以不用知道具体形式,现在就剩下一个问题: 这个核函数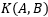 怎么来的?或者说我们怎么才能找到合适的核函数。
怎么来的?或者说我们怎么才能找到合适的核函数。
要想确切的找到这样的核函数也几乎是不可能的。但是我们能不能用其它的函数来代替或者说是表示核函数呢,答案是肯定的。再看核函数的定义:
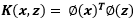
其实就是两个特征映射函数的内积。它可以用多项式等函数表示。因为根据高等数学泰勒展开式我们可以知道,任何函数都可以用多项式的方式去趋近,一些基础的函数如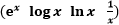 等等都可以去趋近,而不同的函数曲线其实就是这些基础函数的组合。理解这一点很重要!
等等都可以去趋近,而不同的函数曲线其实就是这些基础函数的组合。理解这一点很重要!
所以我们完全可以用一些基础函数去无线趋近实际的核函数,例如多项式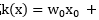
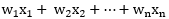 ,还有高斯函数
,还有高斯函数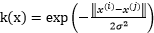 , 也就是指数函数的扩展形式,这些都是基础函数,所以这些函数都可以作为核函数。(相信很多人都曾疑惑为什么在绝大多数讲解核函数文章或是书籍的时候都会跳到核函数的具体形式如多项式核、高斯核等,而却为什么没有讲解这些函数为什么可以作为核函数)。
, 也就是指数函数的扩展形式,这些都是基础函数,所以这些函数都可以作为核函数。(相信很多人都曾疑惑为什么在绝大多数讲解核函数文章或是书籍的时候都会跳到核函数的具体形式如多项式核、高斯核等,而却为什么没有讲解这些函数为什么可以作为核函数)。
下面就是一些常用的核函数介绍:

回到本章的具体问题,我们应该如何选取这些核函数并应用到我们的学习器中呢?它有什么经验可以遵循?本人自认经验还很欠缺,不敢做深入分析,以下收集一些网上和论文的经验:
- 线性核(Linear) 主要应用与线性可分的情形,参数少,速度块,对于一般的数据可以尝试首先运用线性核。 Linear和是
- RBF也就是径向基函数,也叫高斯核,应用最为广泛,主要应用线性不可分的情形,参数多,分类结果非常依赖于参数。通过交叉验证来寻找合适的参数,通过大量的训练可以达到比线性核更好的效果。
- 多项式核需要确定的参数要比RBF多,而参数多少直接影响了模型的复杂度。
- Sigmoid核,对于某些参数RBF和sigmoid具有相似的性能。
-
核函数判定与再生核希尔伯特空间(reproducing kernel Hilbert space, RKHS)
通过前面的介绍我们知道核函数的用途,也知道一些常用的核函数,当然不是任何基础函数都可以做为核函数的,作为核函数还必须要满足一些性质,这一章节要讲解做为核函数所必须具有的一些性质。
如果K是有效的核函数,那么根据核的定义可知:
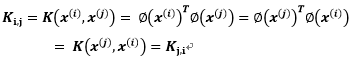
从上式可知,K矩阵必须是对称的。并且让 表示
表示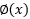 第k坐标的属性值,对任意向量z有:
第k坐标的属性值,对任意向量z有:
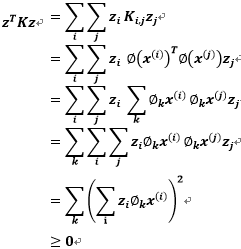
从上面的对到可以看出只要是K是个有效的核函数,由于z是任意的,所以核K是半正定的(K>=0)。
下面的Mercer定理很好的总结该性质:
如果函数K是 上的映射(也就是从两个n维向量映射到实数域)。那么如果K是一个有效的核函数,也称为Mercer核函数,那么当且仅当对于训练样例
上的映射(也就是从两个n维向量映射到实数域)。那么如果K是一个有效的核函数,也称为Mercer核函数,那么当且仅当对于训练样例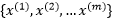 , 其相应的核函数矩阵是半正定的。
, 其相应的核函数矩阵是半正定的。
简单的说就是只要一个对称函数所对应的核矩阵半正定就可以作为核函数使用。对于一个半正定核矩阵,总能找到一个与之对应的映射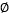 ,换言之,任何一个核函数都隐式地定义一个称为"再生核希尔伯特空间"(reproducing kernel Hilbert space, RKHS)的特征空间。
,换言之,任何一个核函数都隐式地定义一个称为"再生核希尔伯特空间"(reproducing kernel Hilbert space, RKHS)的特征空间。
-
再生核希尔伯特空间
我们知道希尔伯特空间就是完备的内积空间(如果对函数空间知识不是很了解,可以看看函数空间的相关知识,上海交大的公开课讲的挺不错,上海交通大学公开课:数学之旅——函数空间),详细一点的说就是描述就是:
- 赋予范数的集合称为赋范空间;
- 赋予距离的集合称为度量空间。
赋范空间有向量的模长,也就是范数,但是两个向量是有夹角的,范数没有夹角的概念,所以为了表示这样的两个向量,引入内积的概念,所以有接着的第三个:
- 赋予内积的集合称为内积空间
注意内积空间有几个属性,即对称性(例如距离的d|x-y|=d|y-x|)和正定性等和前面讨论的Mercer定理是一一对应的。
如果在内积空间加上完备性就构成了希尔伯特空间,完备性简单点说就是极限运算中不能跑出度量的范围。
在了解了希尔伯特空间后,我们看再生核希尔伯特空间的定义:
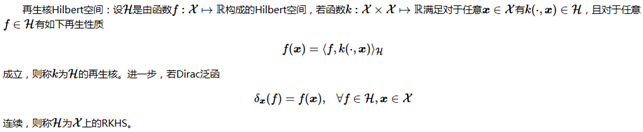
这里暂且不进行进一步的讨论,主要是由于自己对再生核理解得还不够透彻,希望能在下一篇文章中做进一步的阐述。
-
软间隔和正则化
-
离群样本点和损失函数分析
-
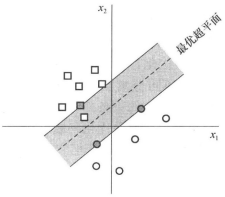
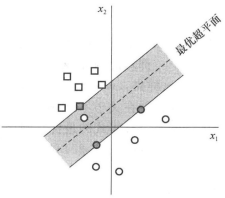
前面我们提到,当我们尝试将原始空间上的线性不可分的问题转化为高维空间的线性可分的问题,但是现实的情况非常复杂,即使在维度比较高的特征空间也很难找到合适的核函数使得训练样本线性可分。
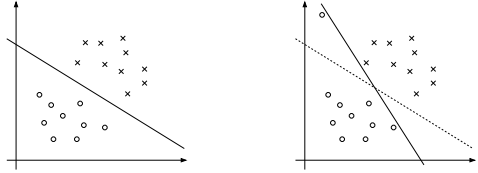
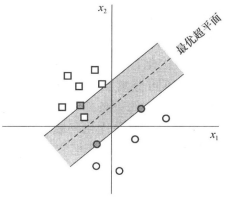
我们看到左图中间隔曲线将两个类别分开,并且最小间隔比较大,右图则是另一种情况,左上角出现一个样本点,它更靠近正例(我们说它是离群点),这时候我们仍然要将它从正例中区别出来,并且将它正确的预测分类为负类,那么我们的间隔曲线就必须做一定的调整,也就是从原来的虚线转变为实线,这样才能有效的将新的样本区别开来,这个例子说明我们前面介绍的模型对这些离群的点或者说是样本的噪声非常敏感。
这里要提到的软间隔就是,就是支持向量机允许一些样本出错,即允许存在一些不满足约束的离群的点,如下图红色高显的点,就是一些不满足约束的离群点。

即这些点不满足约束:
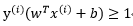
优化目标写为:
|
|
(3-10-1) |

上式中C是一个大于0的常数,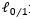 是0/1损失函数,
是0/1损失函数,
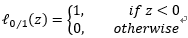
由前面两个式子可以看出,C取无穷大时,为了让优化目标取得最小值,则取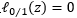 ;意思就是后面的项归0(otherwise),也就是
;意思就是后面的项归0(otherwise),也就是 , 这也就是说,
, 这也就是说,
- 当C取无穷大时,为了达到目标的最优化,所有样本就必须满足约束条件
![]()
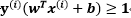
而当C取有限值时,为了让优化目标取得最小值,可以允许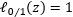 ,即允许加上一个有限值C*1=C, 即
,即允许加上一个有限值C*1=C, 即
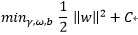
-
即当C去有限值的,允许有一些样本不满足约束,对应到上面的两个图,就是那些离群的样本点。
-
替代损失(surrogate loss)简介与松弛变量(Slack variables)
-
替代损失,顾名思义,就是替代前面介绍的为了优化有样本离群这种情况的目标函数而引入的损失函数。那为什么需要替代函数呢?因为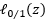 非凸,不好求极值,而我们的最小化问题就是一个求极值的问题,所以我们需要这么一个替代的函数来代替
非凸,不好求极值,而我们的最小化问题就是一个求极值的问题,所以我们需要这么一个替代的函数来代替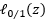 ,以下是三个比较常用的替代函数:
,以下是三个比较常用的替代函数:
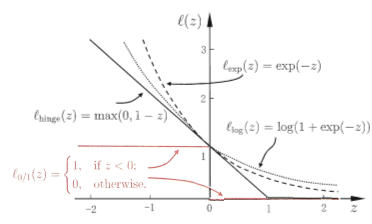
- hinge损失:
![]()
- 指数损失(exponential loss):
![]()
- 对率损失(logistic loss):
![]()
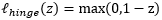
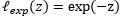
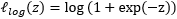
若采用hinge损失:则优化目标(3-10-1)可以有以下的转化:

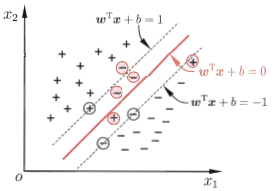
这就是常用的"软间隔支持向量机",这和线性可分模式下分析时候的二次规划问题很类似,观察(3-10-2)式,很显然每个样本都对应有一个松弛变量,我们可以看到首先松弛变量 非负,约束条件同时也表明允许某些样本点的函数间隔小于1或是函数间隔为负,让我们再看下图分析:
非负,约束条件同时也表明允许某些样本点的函数间隔小于1或是函数间隔为负,让我们再看下图分析:
- 函数间隔小于1的样本点在最大间隔区间里面,如下图中的蓝圈圈住的样本。
- 函数间隔为负数的样本点则在在相反的样本分类里面,如下图中的红圈圈住的样本。





通过上面的描述我们可以总结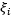 的重要特性,即:
的重要特性,即:
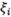 表征了该样本不满足约束条件
表征了该样本不满足约束条件 的程度。
的程度。
我们可以看到(3-10-2)式的约束条件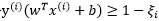 相对于约束条件
相对于约束条件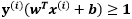 ,这个条件也是我们在线性可分模式下的时候必须服从的约束条件放宽了很多,而放宽了这些限制后我们就必须对目标函数进行调整。
,这个条件也是我们在线性可分模式下的时候必须服从的约束条件放宽了很多,而放宽了这些限制后我们就必须对目标函数进行调整。
再看(3-10-2)式中的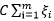 ,我们发现它有两个特点:
,我们发现它有两个特点:
![]() 表示离群点越多,目标函数就越大,这和我们最小化目标函数是相悖的。
表示离群点越多,目标函数就越大,这和我们最小化目标函数是相悖的。- 表示的是离群点的权重,C越大表示离群点对目标函数的影响就越大。
- 目标函数控制着离群点的数目和程度,使得大部分样本仍然服从限制条件。

-
拉格朗日求解软间隔目标函数
为了求解软间隔的优化目标函数(3-10-2),回想我们在求解最优间隔分类器对偶问题时的拉格朗日乘子法,通过目标函数和约束条件构造拉格朗日函数,
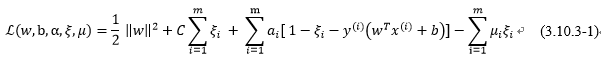
其中 和
和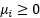 是拉格朗日乘子,然后根据以下步骤分别求导:
是拉格朗日乘子,然后根据以下步骤分别求导:
- 对偶问题则是先固定
![]() ,优化出最优的
,优化出最优的![]() ,最后确定参数
,最后确定参数![]() 。
。
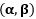 ,优化出最优的
,优化出最优的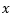 ,最后确定参数
,最后确定参数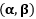 。
。固定拉格朗日乘子,对w求导得到:
|
|
(3.10.3-2) |
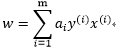
对b求导得到:
|
|
(3.10.3-3) |
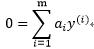
对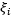 求导得到:
求导得到:
|
|
(3.10.3-4) |
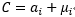
将上面三个等式带入目标函数(3-10-2)可得到(解法参考前面的详细推导):
|
|
(3.10.3-5) |
|
|
|

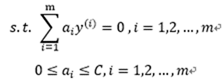
对比上式和最优间隔分类器中对偶问题的求解结果可知,两者之间只是约束不一样,求解的结果中并不包括松弛变量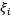 ,但是包括了参数C。
,但是包括了参数C。
同样参考拉格朗日对偶性中对KKT条件的描述:
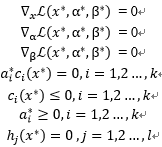
我们的软间隔支持向量机即(3-10-2)
|
|

-
软间隔的KKT条件分析
紧接着求相应的软间隔的KKT条件可得:

分析软间隔的KKT条件,也如拉格朗日对偶性章节中分析的一样,软间隔的KKT条件仍满足KKT的对偶互补条件即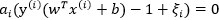 ,也就是说对任意样本
,也就是说对任意样本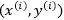 ,总有
,总有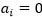 或是
或是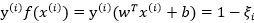 ,所以
,所以
- 若
![]() ,则很显然该样本不会对
,则很显然该样本不会对![]() 产生任何影响
产生任何影响
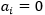 ,则很显然该样本不会对
,则很显然该样本不会对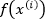 产生任何影响
产生任何影响- 若
![]() ,则必然有
,则必然有![]() ,即该样本就是支持向量。
,即该样本就是支持向量。
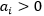 ,则必然有
,则必然有 ,即该样本就是支持向量。
,即该样本就是支持向量。


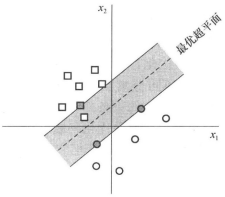
另外根据(3.10.3-4)即 ,分析以下几种情况:
,分析以下几种情况:
- 若
![]() ,则因为
,则因为![]() ,所以
,所以![]() , 则
, 则![]() ,又根据
,又根据![]() ,进而有松弛变量
,进而有松弛变量![]() ,这表明该样本恰好在最大间隔的边界上,如下图红圈点:
,这表明该样本恰好在最大间隔的边界上,如下图红圈点:
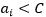 ,则因为
,则因为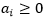 ,所以
,所以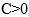
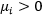 ,又根据
,又根据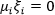 ,进而有松弛变量
,进而有松弛变量 ,这表明该样本恰好在最大间隔的边界上,如下图红圈点:
,这表明该样本恰好在最大间隔的边界上,如下图红圈点:


- 若
![]() ,则有
,则有![]() ,又根据
,又根据![]() 的,这个时候
的,这个时候![]() 有以下两种情况:
有以下两种情况:
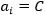 ,则有
,则有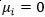 ,又根据
,又根据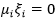
 有以下两种情况:
有以下两种情况:-
![]() 则样本落在最大间隔内部,但是在超平面的正确一侧,如下图红圈点:
则样本落在最大间隔内部,但是在超平面的正确一侧,如下图红圈点:![]()
![]()
-
![]() 则该样本被错误分类,即落在超平面的错误一侧,如下图红圈的样本点
则该样本被错误分类,即落在超平面的错误一侧,如下图红圈的样本点![]()
![]()
总结:上面通过对软间隔的KKT条件分析,我们得出结论:软间隔支持向量机的模型只与
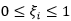

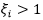

支持向量有关。
-
过拟合(overfitting)与正则化(regularization)
过拟合就是说学习器把训练样本自身的一些特征当做所有潜在样本都会具有的一般性质,导致泛化性能下降。与过拟合相对的是欠拟合,也就是说学习器连样本的一般性质都没有学习好,下图中比较好的诠释了过拟合和欠拟合的分类效果。
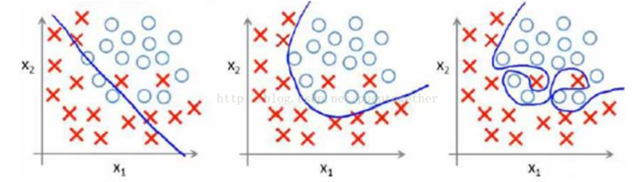
- X1为欠拟合的情况,也就是不能很好的区分类别。
- X2为分类刚刚好,就是即使有些样本没有分类出来,但是可以保证绝大部分情况下有效的分类,没有将样本特有的一些属性添加到模型,在真实情况时候往往可以达到理想的效果。
- X3为过拟合,也就是说分类只适合训练样本,到了真实环境中的时候效果会不理想。
A: 欠拟合的情况可以通过在学习过程中扩展分支或是在神经网络学习中增加训练轮数来解决。
B: 过拟合的情况不可避免,只能是缓解,各种机器学习算法中都有一些针对过拟合的措施,正则化就是一个防止过拟合的有效手段。
正则化就是为模型添加调整参数的过程,目的是为了防止过拟合(overfitting), 增加平滑度。通常会以向现有的权向量(weight vector)添加常倍数的方式来完成,这个常数一般为L1(Lasso)或者L2(ridge), 但是实际上可以是任何形式的。
在修改后的模型中,从正则化训练集得出的损失函数,平均值应当降至最低。
|
|

再看(3-10-2-1)式子中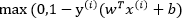 是hinge损失函数,如下图可知hinge损失函数有一段"平坦"的零区域,这使得支持向量机的解具有稀疏性。
是hinge损失函数,如下图可知hinge损失函数有一段"平坦"的零区域,这使得支持向量机的解具有稀疏性。
如果用其他的损失函数代替hinge损失做0/1损失函数,就可以得到其他的学习模型,它的一般形式为:
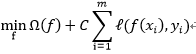 (3.10.5-1)上式就是正则化问题,其中:
(3.10.5-1)上式就是正则化问题,其中:
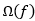 称为"结构风险"(structural risk), 也称为正则化项,用于描述模型f的某些性质;
称为"结构风险"(structural risk), 也称为正则化项,用于描述模型f的某些性质;
![]() 称为"经验风险"(empirical risk),用于描述模型与训练数据的契合程度;
称为"经验风险"(empirical risk),用于描述模型与训练数据的契合程度;
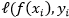
- C用于对前面两个进行折中,称为正则化常数。
常用的正则化项有: 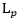 范数是常用的正则化项,其中
范数是常用的正则化项,其中 范数
范数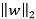 倾向于w的分量取值尽量的均衡,即非零分量个数尽量稠密。而
倾向于w的分量取值尽量的均衡,即非零分量个数尽量稠密。而 范数
范数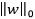 和
和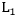 范数
范数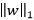 则倾向于w的分量尽量的稀疏,即非零分量个数尽量少。
则倾向于w的分量尽量的稀疏,即非零分量个数尽量少。
-
支持向量回归
-
核方法
-
支持向量机实践
这里限于篇幅,实践的内容将在下一篇展开…

 浙公网安备 33010602011771号
浙公网安备 33010602011771号