cache基础知识与配置 (仅作自己学习记录,较混乱)
1. 局部性原理(locality)
cache中局部地址对应的数据较为常用,而该局部地址以外的数据较少使用。局部性是cache的巨大特性。把常用数据的地址,放到cache中,避免CPU不停的到MEM中寻找数据。
2. cache的命中率
指 CPU在任意时刻从cache中可靠读取数据的概率, 能在cache中找到需要的内存地址和数据的概率。
3. 映射方法
注:cache和Memory的映射是按块(block)执行的
全相联映射:mem块可以存储到cache的任意位置,非常灵活,不过需要有相联映射表。因为mem的数据多,其块数远大于cache的块数,所以cache的块名无法和mem的块名一一对应。mem数据写入到cache时,系统将两者的块名做成相联映射表,CPU需要mem的某块数据时,就在相联映射表中寻找对应的cache地址,读出所需的数据。
直接映射:该方法不需要相联映射表,而是将cache和mem都分为块,比如cache分为10块,mem分为100块。mem的第1,11,21...91块只能存放在cache的第1块,第2块只能存放在cache的第2块,依次类推。因此,不需要映射表,只需计算:【mem块名%cache块数】的模值,比如mem的第21块,其存储在cache的位置为:21%10=1,第一块。
组相联映射:组相联映射是前两者的折中方案。将cache和mem都分组,每组同样按直接映射的方式存放,但是组内的各块却采用全相联映射,可以任意对应存放。
4. 替换策略:
FIFO:堆栈,先进先出。最先存到cache的数据地址被最先替换出去。
LRU(Least Recently Used,近期最少使用):把CPU近期最少使用的块替换出去。这种替换方法需要随时记录Cache中各块的使用情况,以便确定哪个块是近期最少使用的块。每块也设置一个计数器,Cache每命中一次,命中块计数器清零,其他各块计数器增1。当需要替换时,将计数值最大的块换出。:近期使用最少的先替换出去
LFU(Least Frequently Used,最不经常使用):将一段时间内被访问次数最少的那个块替换出去。每块设置一个计数器,从0开始计数,每访问一次,被访块的计数器就增1。当需要替换时,将计数值最小的块换出,同时将所有块的计数器都清零。
一般规定Cache与内存的空间比为4:1000,即128kB Cache可映射32MB内存;256kB Cache可映射64MB内存
AMAT(average memory access time): AMAT= hit time _+miss rate * access penalty
OS : 操作系统,(operating system)用特权模式才能访问
CPU性能评估:latency延迟 throughput 单位时间内完成的指令数 throughput越高越好,latency越低越好; speedup=N=latency(B)/Latency(A)=Throughput(A)/B,性能比较,A的性能or速度是B的N倍。
Benchmark: 用于衡量CPU的性能;理解为标准的测试库,
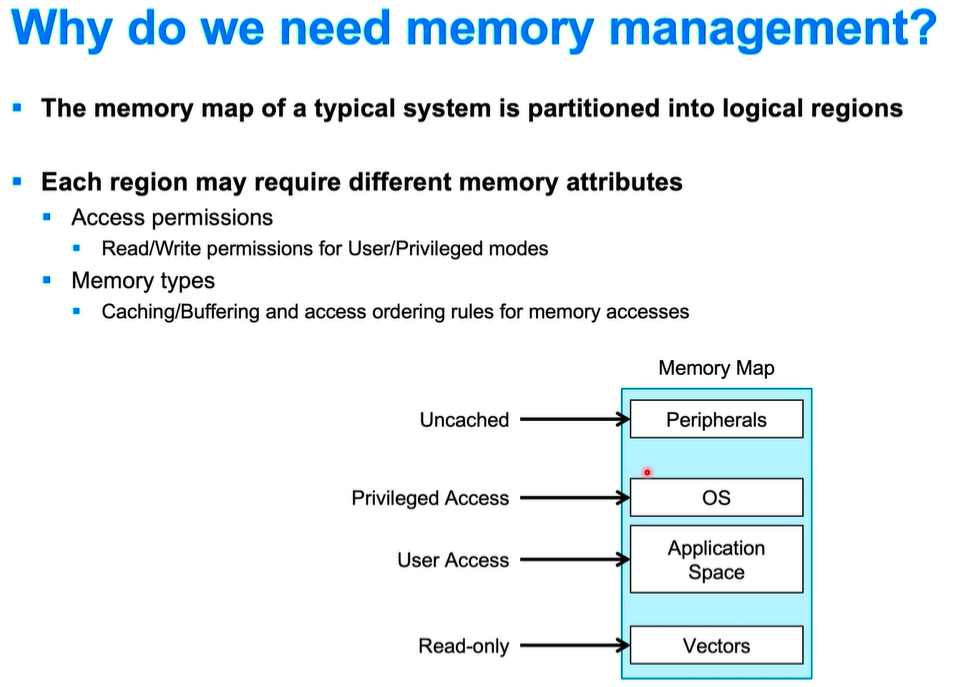
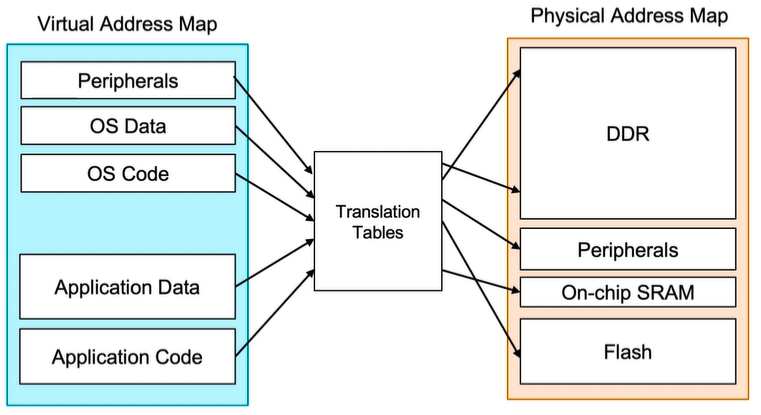
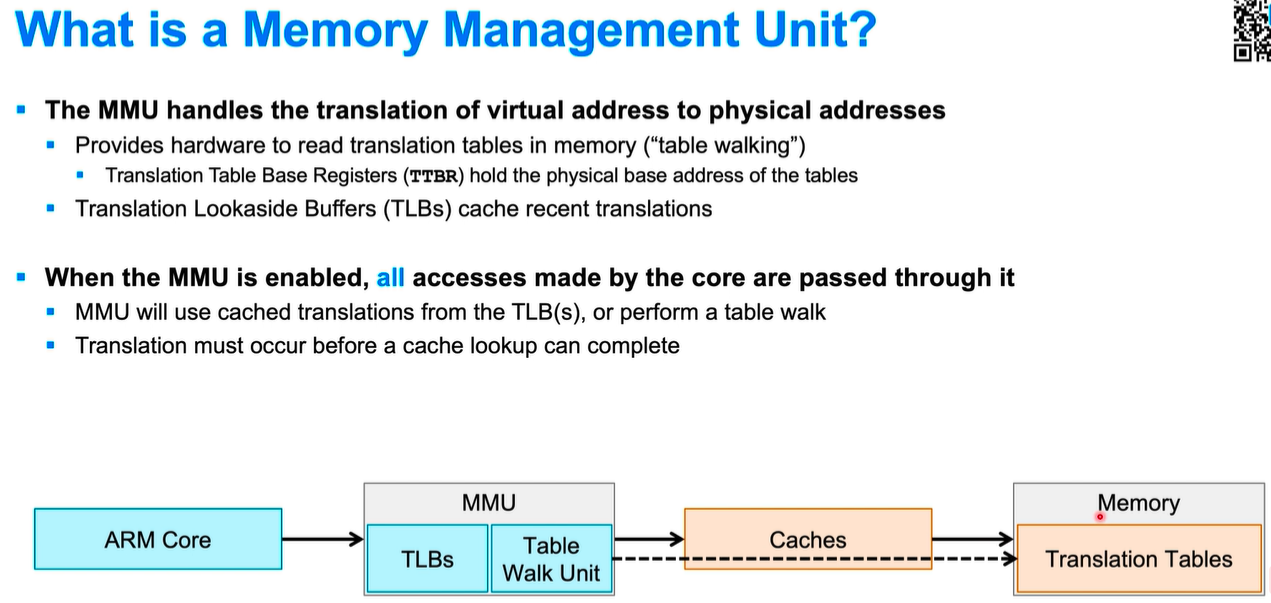
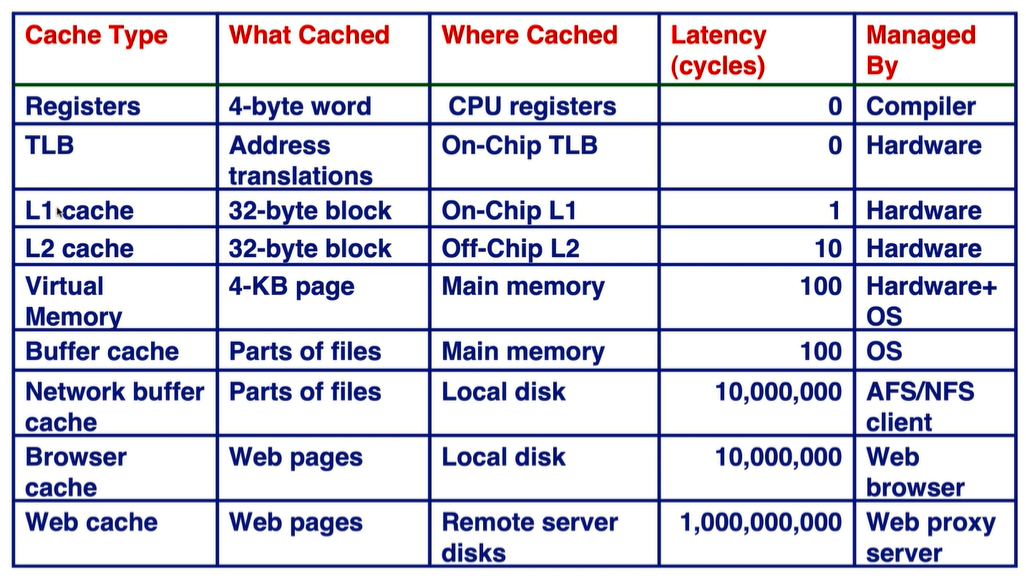
cache 尺寸:L1: 16K~64KB; Cache line 尺寸:一般为32~128 bytes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号