Pisa-Proxy SQL 解析之 Lex & Yacc
一、前言
1.1 作者介绍
王波,SphereEx MeshLab 研发工程师,目前专注于 Database Mesh,Cloud Native 的研发。Linux,llvm,yacc,ebpf user。 Gopher & Rustacean and c bug hunter。
GitHub: https://github.com/wbtlb
1.2 背景
在上篇文章《Pisa-Proxy 之 SQL 解析实践》中介绍了 Pisa-Proxy 的核心模块之一 SQL 解析器的相关内容。在 MySQL 和 PostgreSQL 中 SQL 解析是通过 Yacc 实现的,同样 Pisa- Proxy 的 SQL 解析器是由类似 Yacc 这样的工具实现的,所以本篇文章会围绕 SQL 解析器为大家介绍一些编译原理和 Lex & Yacc 的使用,同时也会为读者展示如何通过 Lex & Yacc 实现一个简单的 SQL 解析器。从而帮助大家更好地理解 Pisa-Proxy 中 SQL 解析器是如何工作的。
二、编译器初探
一个程序语言不论是我们常用的 Java,Golang 或者是 SQL 本质上都是一个记号系统,如同自然语言一样,它的完整定义应该包括语法和语义两个方面。一种语言的语法其实是对应的一组规则,用它可以形成和产生一个合适的程序。当前使用最广泛的手段是上下文无关的文法,上下文无关的文法作为程序设计语言语法的描述工具。语法只是定义什么样的符号序列是合法的,与这些符号的含义毫无关系。然而在语义中分为两类:静态语义和动态语义。静态语义是指一系列的限定规则,并确定哪些语法对于程序来说是合适的;动态语义也称作运行语义或者执行语义,明确程序具体要计算什么。
2.1 编译器工作流程
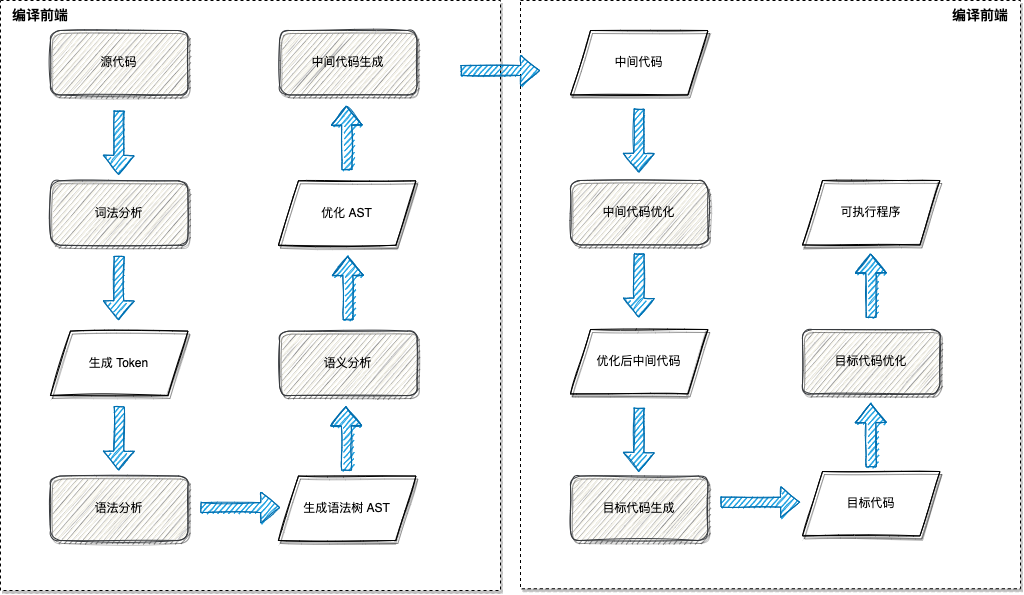
如图 2.1.1 中所示,通常编译器将源代码编译成可执行文件主要有以下几步:
- 对源文件进行扫描,将源文件的字符流拆分分一个个的词(token),此为词法分析
- 根据语法规则将这些记号构造出语法树,此为语法分析
- 对语法树的各个节点之间的关系进行检查,检查语义规则是否被违背,同时对语法树进行必要的优化,此为语义分析
- 遍历语法树的节点,将各节点转化为中间代码,并按特定的顺序拼装起来,此为中间代码生成
- 对中间代码进行优化
- 将中间代码转化为目标代码
- 对目标代码进行优化,生成最终的目标程序
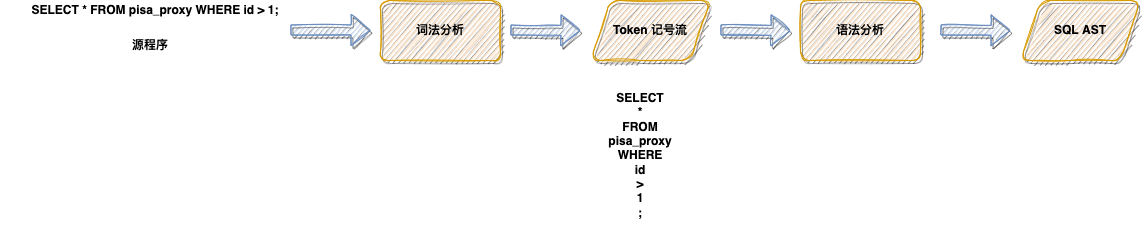
对于 SQL 解析来说,就可以将上图中的步骤简化为如图 2.1.2 的形式,源码输入(SQL 语句),将 SQL 语句进行词法分析,生成 SQL 中特定的 token 记号流。然后拿到记号流后进行语法分析后生成最终的 SQL AST。
2.2 词法分析
上文中提到,无论是编译器还是 SQL 解析器有一个关键步骤就是要对源文件做词法分析,词法分析我们可以理解为对 SQL 语句本身做分词处理。那么在这个阶段,SQL 解析器要做的工作就是从左到右扫描源文件,将 SQL 语句分割成一个个的 token,这里说的 token 是指 SQL 中不能再进一步分割的一串字符。例如图 2.1.2 中的 SQL 语句,经过词法分析后,生成的 token 为:SELECT、*、FROM、pisa_proxy 等等。
在 SQL 语句中能用到的 token 类别也是有限的,比如保留字 SELECT、INSERT、DELETE 等等。还有操作符,比如:算术操作符、比较操作符。还有标识符,比如:内置函数名等等。在此阶段每扫描一个 token 会被维护到一个数据结构中,然后在下个阶段语法分析阶段使用。
通常来说,词法分析有直接扫描,正则匹配扫描方式。
2.2.1 直接扫描法
直接扫描法逻辑非常清晰,每次扫描根据第一个字符判断属于哪种类型的 token,然后采取不同的策略扫描出一个完整的 token,然后再进行下一轮扫描。在 Pisa-Proxy 中的 SQL 解析中,词法分析就采用了这种实现方式,用 Python 展示如何实现一个简单的 SQL 词法分析器对 SQL 进行扫描,代码如下:
# -*- coding: utf-8 -*-
single_char_operators_typeA = {
";", ",", "(", ")","/", "+", "-", "*", "%", ".",
}
single_char_operators_typeB = {
"<", ">", "=", "!"
}
double_char_operators = {
">=", "<=", "==", "~="
}
reservedWords = {
"select", "insert", "update", "delete", "show",
"create", "set", "grant", "from", "where"
}
class Token:
def __init__(self, _type, _val = None):
if _val is None:
self.type = "T_" + _type;
self.val = _type;
else:
self.type, self.val = _type, _val
def __str__(self):
return "%-20s%s" % (self.type, self.val)
class NoneTerminateQuoteError(Exception):
pass
def isWhiteSpace(ch):
return ch in " \t\r\a\n"
def isDigit(ch):
return ch in "0123456789"
def isLetter(ch):
return ch in "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
def scan(s):
n, i = len(s), 0
while i < n:
ch, i = s[i], i + 1
if isWhiteSpace(ch):
continue
if ch == "#":
return
if ch in single_char_operators_typeA:
yield Token(ch)
elif ch in single_char_operators_typeB:
if i < n and s[i] == "=":
yield Token(ch + "=")
else:
yield Token(ch)
elif isLetter(ch) or ch == "_":
begin = i - 1
while i < n and (isLetter(s[i]) or isDigit(s[i]) or s[i] == "_"):
i += 1
word = s[begin:i]
if word in reservedWords:
yield Token(word)
else:
yield Token("T_identifier", word)
elif isDigit(ch):
begin = i - 1
aDot = False
while i < n:
if s[i] == ".":
if aDot:
raise Exception("Too many dot in a number!\n\tline:"+line)
aDot = True
elif not isDigit(s[i]):
break
i += 1
yield Token("T_double" if aDot else "T_integer", s[begin:i])
elif ord(ch) == 34: # 34 means '"'
begin = i
while i < n and ord(s[i]) != 34:
i += 1
if i == n:
raise Exception("Non-terminated string quote!\n\tline:"+line)
yield Token("T_string", chr(34) + s[begin:i] + chr(34))
i += 1
else:
raise Exception("Unknown symbol!\n\tline:"+line+"\n\tchar:"+ch)
if __name__ == "__main__":
print "%-20s%s" % ("TOKEN TYPE", "TOKEN VALUE")
print "-" * 50
sql = "select * from pisa_proxy where id = 1;"
for token in scan(sql):
print token
最终的输出结果如下:
TOKEN TYPE TOKEN VALUE
--------------------------------------------------
T_select select
T_* *
T_from from
T_identifier pisa_proxy
T_where where
T_identifier id
T_= =
T_integer 1
T_; ;
由上面的代码我们可以看到,在一开始我们定义了几个 token 类型,例如:reservedWords 数组中维护了 SQL 中的保留字,还有 SQL 中的操作符 single_char_operators_typeA。最终的执行结果我们可以看出,扫描器最终将一条 SQL 语句进行分词最终拆成各自对应类型的 token。
2.2.2 正则表达式扫描法
其实程序的本质就是一组字符串,而语言可以看成合法程序的集合,因此编译器或者说 SQL 解析的本质是判断输入的字符串是该语言的合法类型,另外也是将语言中的合法程序转换成目标语言的合法程序。所以正则表达式扫描法的本质,也就是在一个有限状态机里来判断字符串是否和正则表达式是否匹配,在后面的介绍中我们会提到 flex,flex 的本质其实是将用户用正则表达式写的分词匹配模式构造成一个有限状态自动机。
2.3 语法分析
词法分析结束后,SQL 语句的字符流被拆分成 token,那么语法分析就是要分析出 SQL 的语法结构,将线性的 token 流转化为树状结构,为后续的语义分析和 AST 生成做准备。在编译器中,正则表达式还是难以表示程序语言所代表句子的集合,所以就引入的上下文无关文法,上下文无关文法能够描述现今程序设计语言的语法结构。
以我们自然语言为例,假设有一种编程语言为 SQLX,它只包含主-谓-宾 这种结构来说,主语只有你、我、他,谓语只有爱,宾语有 Rust 和 Pisanix,那么语法可以为以下这种形式:
语句 -> 主语 谓语 宾语
主语 -> 我
主语 -> 你
主语 -> 他
谓语 -> 爱
宾语 -> Rust
宾语 -> Pisanix
从上面的例子来看我们可以分别对主谓宾进行替换,从而写出所有满足此结构的语句。反过来讲我们可以用任意语句和此结构对比来判断它是否满足 SQLX 语言。由此产生几个概念,上面语法中形如“主语->谓语->宾语”的式子成为产生式
产生式左侧的符号(语句、主语、谓语、宾语)称为非终结符。而“我,你,他,爱,Rust,Pisanix”这些符号无法再产生新的符号,因此被称为终结符,终结符只能出现在产生式右边。语句这个词为所有句子产生的起点,所以也被称为起始符号。
通常把一个非 终结符的产生式写在一起,用“|”隔开,归纳如下:
语句 -> 主语 谓语 宾语
主语 -> 你|我|他
谓语 -> 爱
宾语 -> Rust | Pisanix
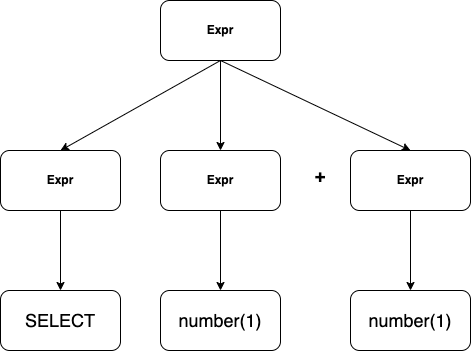
我们以一个 SQL 语句为例: SELECT 1 + 1,我们可以写出这条语句的推到表达式为,分析树如图 2.3.1
Expr => Expr Expr + Expr => SELECT Expr + Expr => SELECT number + Expr => SELECT number + number => SELECT 1 + 2
2.3.1 两种分析方法
语法分析包含两种分析方法:
-
自顶向下分析:自顶向下分析就是从起始符号开始,不断的挑选出合适的产生式,将中间句子中的非终结符的展开,最终展开到给定的句子。
-
自底向上分析:自底向上分析的顺序和自顶向下分析的顺序刚好相反,从给定的句子开始,不断的挑选出合适的产生式,将中间句子中的子串折叠为非终结符,最终折叠到起始符号
在推导的过程中,每一步都只有唯一的一个产生式可以应用,每一步都可以排除掉其他所有的产生式。但在实际分析时,在中间过程中可能会遇到所有产生式都不可应用或者有多个产生式可以应用。对于第二种情况,需要采用回溯,先试探性的选择一个产生式应用,若一直推导至最终句子(或起始符号),则表明此产生式是可用的,若推导下去遇到第一种情况,则回溯到此处,选择另一个产生式。如果此处所有产生式都尝试过了全部都遇到第一种情况,则表明最终句子不符合语法结构。如果此处有多条产生式可以推导至最终句子(或起始符号),则表明语法有歧义。回溯分析一般都非常慢,因此一般通过精心构造语法来避免回溯。
2.4 小结
以上内容主要介绍了编译器的相关概念,和通过一个简单的例子来直观感受词法分析的基本原理和工作过程,接下来我会为大家简单介绍一下在词法分析和语法分析中最常用到的两个工具 Lex 和 Yacc。
三、认识 Lex 和 Yacc
3.1 认识 Lex
Flex(快速词法分析器生成器)是 Lex 的免费开源软件替代品。它是生成词法分析器(也称为“扫描器”或“词法分析器”)的计算机程序。扫描仪是一种识别文本中的词汇模式的程序,用来识别文本中的词汇模式。
3.1.1 Lex由三部分组成
-
定义部分:定义段包括文字块、定义、内部表声明、起始条件和转换。
-
规则部分:规则段为一系列匹配模式和动作,模式一般使用正则表达式书写,动作部分为 C 代码。
-
用户子程序段:这里为 C 代码,会被原样复制到c文件中,一般这里定义一些辅助函数等,如动作代码中使用到的辅助函数。
这里我们做一个简单的例子,用 Lex 实现一个简单的 SQL 词法分析器,lex 代码如下:
%{
#include <stdio.h>
%}
%%
select printf("KW-SELECT : %s\n", yytext);
from printf("KW-FROM : %s\n", yytext);
where printf("KW-WHERE : %s\n", yytext);
and printf("KW-AND : %s\n", yytext);
or printf("KW-OR : %s\n", yytext);
[*] printf("IDENTIFIED : %s\n", yytext);
[,] printf("IDENTIFIED : %s\n", yytext);
[=] printf("OP-EQ : %s\n", yytext);
[<] printf("KW-LT : %s\n", yytext);
[>] printf("KW-GT : %s\n", yytext);
[a-zA-Z][a-zA-Z0-9]* printf("IDENTIFIED: : %s\n", yytext);
[0-9]+ printf("NUM: : %s\n", yytext);
[ \t]+ printf(" ");
. printf("Unknown : %c\n",yytext[0]);
%%
int main(int argc, char* argv[]) {
yylex();
return 0;
}
int yywrap() {
return 1;
}
# flex sql.l # 用 flex 编译 .l 文件生成 c 代码
# ls
lex.yy.c sql.l
# gcc -o sql lex.yy.c # 编译生成可执行二进制文件
# ./sql # 执行二进制文件
select * from pisaproxy where id > 1 and sid < 2 # 输入测试 sql
KW-SELECT : select
IDENTIFIED : *
KW-FROM : from
IDENTIFIED: : pisaproxy
KW-WHERE : where
IDENTIFIED: : id
KW-GT : >
NUM: : 1
KW-AND : and
IDENTIFIED: : sid
KW-LT : <
NUM: : 2
通过上面的例子我们可以看到,Lex 成功地将一条 SQL 语句拆分成了单独的 token。
3.2 认识 Yacc
Yacc 是开发编译器的工业级工具, 采用 LALR(1) 语法分析方法。LR(k) 分析方法,括号中的 k(k>=0) 表示向右查看输入串符号的个数。LR 分析法给出一种能根据当前分析栈中的符号串和向右顺序查看输入串的 k 个符号就可唯一确定分析器的动作是移进还是规约和用哪个产生式规约。
Yacc 和 Lex 一样,也包含由“%%”分隔的三个段:定义声明、语法规则、C代码段。
- 定义段和预定义标记部分:
上面%{ %}的代码和Lex一样,一般称为定义段。就是一些头文件声明,宏定义、变量定义声明、函数声明等。其中%left表示左结合,%right 表示右结合。最后列出的定义拥有最高的优先权。因此乘法和除法拥有比加法和减法更高的优先权。+ - * / 所有这四个算术符都是左结合的。运用这个简单的技术,我们可以消除文法的歧义。
-
规则部分:规则段由语法规则和包括C代码的动作组成。规则中目标或非终端符放在左边,后跟一个冒号(:),然后是产生式的右边,之后是对应的动作(用{}包含)
-
代码部分:该部分是函数部分。当Yacc 解析出错时,会调用
yyerror(),用户可自定义函数的实现。
这里我们用一个简单的例子通过 Yacc 和 Lex 来实现一个简单的 SQL 解析器
sql.l 代码示例
%{
#include <stdio.h>
#include <string.h>
#include "struct.h"
#include "sql.tab.h"
int numerorighe=0;
%}
%option noyywrap
%%
select return SELECT;
from return FROM;
where return WHERE;
and return AND;
or return OR;
[*] return *yytext;
[,] return *yytext;
[=] return *yytext;
[<] return *yytext;
[>] return *yytext;
[a-zA-Z][a-zA-Z0-9]* {yylval.Mystr=strdup(yytext);return IDENTIFIER;}
[0-9]+ return CONST;
\n {++yylval.numerorighe; return NL;}
[ \t]+ /* ignore whitespace */
%%
sql.y 部分代码示例
%{
%}
%token <numerorighe> NL
%token <Mystr> IDENTIFIER CONST '<' '>' '=' '*'
%token SELECT FROM WHERE AND OR
%type <Mystr> identifiers cond compare op
%%
lines:
line
| lines line
| lines error
;
line:
select identifiers FROM identifiers WHERE cond NL
{
ptr=putsymb($2,$4,$7);
}
;
identifiers:
'*' {$$="ALL";}
| IDENTIFIER {$$=$1;}
| IDENTIFIER','identifiers
{
char* s = malloc(sizeof(char)*(strlen($1)+strlen($3)+1));
strcpy(s,$1);
strcat(s," ");
strcat(s,$3); $$=s;
}
;
select:
SELECT
;
cond:
IDENTIFIER op compare
| IDENTIFIER op compare conn cond;
compare:
IDENTIFIER
| CONST
;
op:
'<'
|'='
|'>'
;
conn:
AND
| OR
;
%%
# 此处由于编译过程较为繁琐,此处仅为大家展示关键结果
# ./parser "select id,name,age from pisaproxy1,pisaproxy2,pisaproxy3 where id > 1 and name = 'dasheng'"
''Row #1 is correct
columns: id name age
tables: pisaproxy1 pisaproxy2 pisaproxy3
可以看出通过 Lex 首先将 SQL 解析成 token,然后再由 yacc 做语法解析,根据 .y 中的规则将 column 和 tables 正确解出。
四、Pisa-Proxy SQL 解析实现浅析
在 Pisa-Proxy 中的 SQL 解析器是通过 Grmtools 这个工具实现的,Grmtools 是 Rust 实现的 lex 和 yacc 库。Pisa-Proxy 的 SQL 解析主要包含两部分内容,首先是 lex.rs 文件,这个文件是通过 Grmtools 提供的方法实现的手写词法分析器,如前文提到,这个模块将 SQL 语句进行分词,生成 token。然后是 grammar.y 文件,该文件中描述了 SQL 语句的推导过程,Grmtools 会通过该文件进行语法分析最终生成 SQL AST。
五、总结
本篇文章主要分享了编译器的相关概念和一些原理,我们可以了解到 SQL 解析器对于 SQL 语句的意义是什么,以及如何将 SQL 语句字符串形式转化成我们需要的抽象语法树。Lex 和 Yacc 是两个非常强大的工具,他可以帮助开发者方便快捷地实现自己的解析器,但是编译原理包罗万象也是非常复杂的一门学科。Pisa-Proxy 的 SQL 解析器在实现过程中也遇到很多问题,比如如何解决冲突,二义性,优先级等等问题。后面会继续有文章深度剖析 SQL 语句在 Rust 中的具体实现,本文就不再赘叙述。
六. 相关链接:
6.1 Pisanix:
项目地址:https://github.com/database-mesh/pisanix
官网地址:Hello from Pisanix | Pisanix
Database Mesh:https://www.database-mesh.io/
SphereEx 官网:https://www.sphere-ex.com
6.2 社区
开源项目千万步,Pisanix 才刚起步。开源是一扇门,Pisanix 欢迎各位小伙伴一起参与进来,发表自己的想法,分享自己的见解,不管是代码还是文档,issue 还是 pull request,社区一样欢迎。各位乐意帮助数据库治理的小伙伴们,让我们一起来建设 Pisanix 社区吧~
目前 Pisanix 社区每两周都会组织线上讨论,详细安排如下,我们等你~
| 邮件列表 | https://groups.google.com/g/database-mesh |
|---|---|
| 英文社区双周会(2022年2月27日起),周三 9:00 AM PST | https://meet.google.com/yhv-zrby-pyt |
| 中文社区双周会(2022年4月27日起),周三 9:00 PM GMT+8 | https://meeting.tencent.com/dm/6UXDMNsHBVQO |
| 微信小助手 | pisanix |
| Slack | https://databasemesh.slack.com/ |
| 会议记录 | https://bit.ly/39Fqt3x |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号