中商惠⺠交易中台架构演进:对 Apache ShardingSphere 的应⽤
翟扬,中商惠民平台组架构师,参与中台建设 0 到 1 的过程,主要负责交易中台、商品中台、搜索平台的建设和研发工作。
快消品⾏业传统的运营模式,已经不能适应新时代的发展要求,单⼀推动供应链末端的升级,⽆法实现社区商业的⾼质量发展。中商惠民继续以百万家社区超市订货服务为业务核⼼,从服务零售终端门店转型升级,向推动快消品全产业链数字化转变,构建 B2B2C 数据闭环运营体系,为品牌商、经销商、社区超市提供采、销、营、配全产业链转型升级解决⽅案,持续推动业务探索和创新。这⼀切,强⼤的中台系统功不可没。
交易中台介绍
中商惠民历经⼏次技术迭代,2016 到 2017 年开始 PHP 技术栈转到 Java 技术栈并进⾏微服务化,2018 年开始打造中台。
2021 年年初完成的交易中台⼀期上线,2022 年 3 ⽉完成⼆期上线。
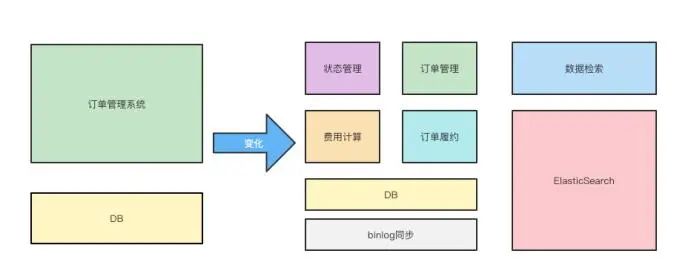
伴随着业务成长和多样性的变化,要及时响应新需求,同时要避免对现有业务产⽣影响,本着提⾼⼈效,降低成本的原则,中商惠民推出了强中台发展战略。对系统⽽⾔,要降低系统之间的耦合度,增加可扩展性,提取业务共性的同时要保证低延迟。在 2021 年之初完成了对之前订单管理系统(OMS)的重构,推出了以订单的交易过程为核⼼的交易中台项⽬,分为以下四个核⼼模块:订单状态流转系统,订单管理系统,订单履约系统,订单费⽤计算系统。同时,基于业务分层,又拆分为订单查询系统,报表系统,订单管理后台等。
在系统的重构过程中避免技术需求对业务需求产⽣阻碍,上线过程分为两个阶段:应⽤系统拆分和数据拆分。
系统拆分
作为业务“重灾区”的订单管理系统,在业务快速成长的过程中,频繁地对系统作出调整还需要适配多个业务线,会把研发同学搞的焦头烂额,疲惫不堪……基于这些问题,制定以下原则对系统进⾏拆分重构:
-
避免不同业务线处理逻辑耦合,互相牵制和影响,降低逻辑复杂度。
-
根据订单⽣命周期中职责进⾏划分,保证每个系统领域独⽴职责单⼀。
-
进⾏读写分离,保证核⼼功能的稳定性,避免频繁迭代影响核⼼功能。
-
引⼊ ElasticSearch,解决外置索引问题,降低数据库索引压⼒ 。
数据拆分
数据拆分的⽬的是降低单表维护压⼒,数据量达到千万级别时,数据库表的索引和字段维护都会对线上环境产⽣不⼩的影响。决定对数据表做拆分时,需要⾯临以下⼏个问题:
-
制定拆分原则:什么样的表属于数据密集型?拆分的数量怎么定?
-
数据读写问题:如何解决表拆分后的读写问题?
-
上线⽅案:如何做到平滑上线?
拆分原则
以 3 年作为⼀个迭代周期,拆分数量=((每⽉新增的数据量* 36)+ 历史数据量)/单表数据量上限
根据我们维护阿⾥云 RDS MySQL 的经验来看,基于在使⽤ Innodb 引擎下,进⾏ DDL 操作时,⼩于 500 万数据量,执⾏时间⼤概⼏⼗秒;⼤于 500 万,⼩于 1000 万数据量,执⾏时间⼤概 500 秒左右;⼤于 1000 万数据量,⼩于 5000 万左右,执⾏时间⼤概 1000 多秒;⼤于 5000 万以上数据量,执⾏时间在 2000 秒以上。
单表分配上限可以取决于单表操作对业务带来的影响,当然也有⼀些⽅案可以解决 DDL 操作锁表的问题,例如双表同步,切换表名的⽅式可以将影响降低为秒级。
库表的拆分数量最好是 2 的 N 次⽅,有利于后期做⽔平扩容。
技术选型
数据表拆分之后,需要解决数据散列和查询问题。作为⼀家中⼩型企业,⾃研⼀套分库分表的中间件成本过⾼,初期还会⾯临各种踩坑的风险,合理的⽅案是采⽤⼀套开源的数据库分库分表的中间件。
Apache ShardingSphere
Apache ShardingSphere 是⼀套开源的分布式数据库解决⽅案组成的⽣态圈,由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独⽴部署,又⽀持混合部署配合使⽤的产品组成,均提供标准化的数据⽔平扩展、分布式事务和分布式治理等功能,可适⽤于如 Java 同构、 异构语⾔、云原⽣等各种多样化的应⽤场景。
Apache ShardingSphere 5.x 版本提出 Database Plus 概念。Database Plus 是一种分布式数据库系统的设计理念,通过在碎片化的同构或异构数据库之上搭建使用和交互的标准层和生态层,并叠加扩展更多计算能力,例如数据分片、数据加解密等,使得所有应用和数据库之间的交互面向 Database Plus 构建的标准层,从而屏蔽数据库碎片化对上层业务带来的差异化影响。
新版本开始致⼒于可插拔架构,项⽬的功能组件能够灵活的以可插拔的⽅式进⾏扩展。⽬前,数据分⽚、读写分离、数据加密、影⼦库压测等功能,以及 MySQL、PostgreSQL、SQL Server、Oracle 等 SQL 与协议的⽀持,均通过插件的⽅式织⼊项⽬,开发者能够像使⽤积⽊⼀样定制属于⾃⼰的独特系统。Apache ShardingSphere ⽬前已提供数⼗个 SPI 作为系统的扩展点,仍在不断增加中。
选择 Apache ShardingSphere 有以下⼏点理由:
-
Apache ShardingSphere 功能符合预期,可以解决⽬前的问题并且有丰富的扩展性。
-
Apache ShardingSphere 社区活跃度⾼,遇到问题会有专⼈及时响应。
-
公司采⽤ SpringCloud 技术栈,集成⽅便,成本低。
-
性能表现参考官⽅⽂档符合预期,完全可以⽀撑现有业务。
ShardingSphere ⽀持以下 3 种模式:
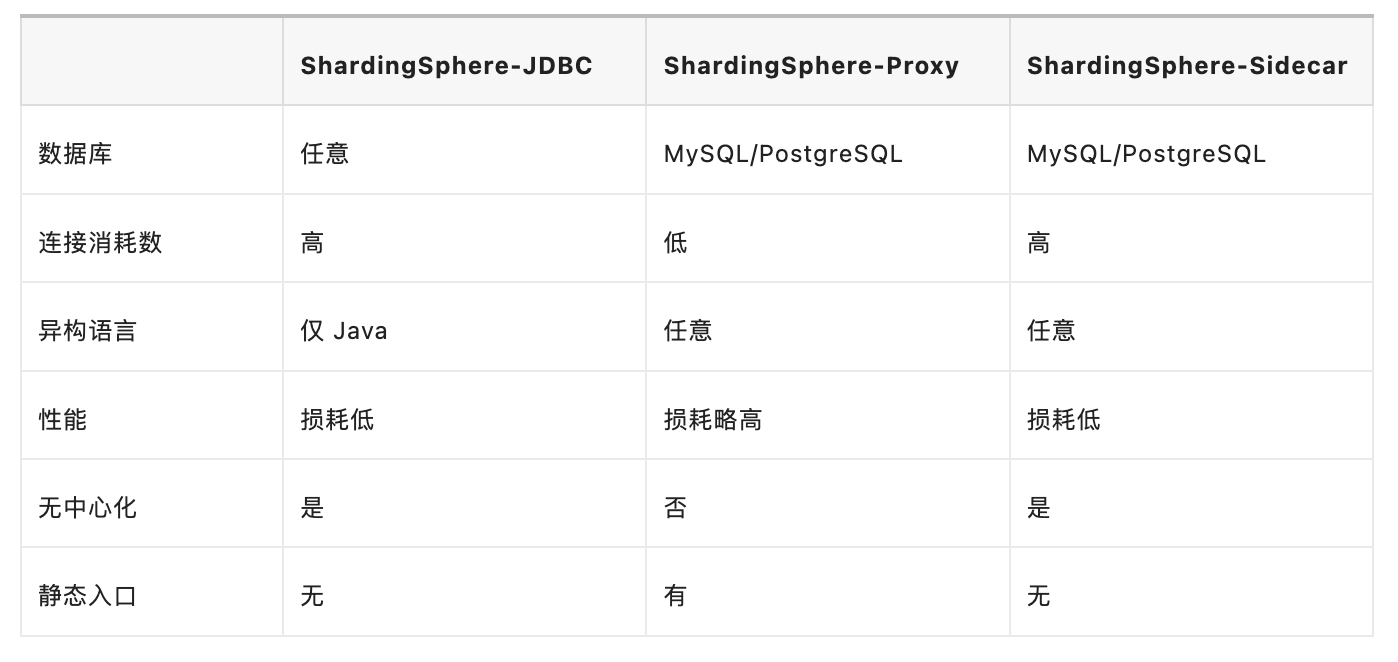
公司⽬前服务端技术栈只涉及 Java 语⾔,暂时不需要考虑异构的场景,出于对灵活性、代码侵⼊性和部署成本⽅⾯的综合考虑,最终选⽤ ShardingSphere-JDBC 的实现⽅案。
技术实现
过程中最复杂的部分其实不是插件集成部分,⽽是上线环节。
上线过程避免被业务团队“投诉”,需要尽可能规避对终端⽤户产⽣的影响,做到⽆感知并且可回滚,最终我们将上线过程拆解为以下⼏步,如图所示:
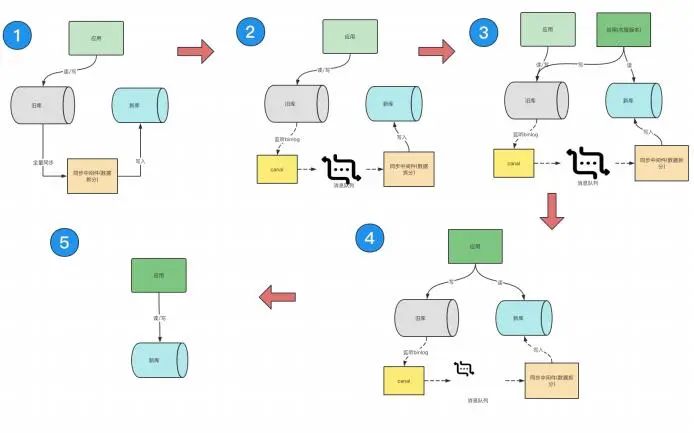
下⾯来解释⼀下这⼏步过程:
第⼀步:处理全量数据的过程,需要保证新⽼库的数据保持⼀致。因为涉及到数据分⽚策略,⽬前市⾯上没有⽀持数据分⽚策略的同步⼯具,这块我们⾃研了⼀个数据同步⼯具,⽀持配置分⽚策略。
第⼆步:处理增量数据,保持新旧库的数据⼀致性。此处我们的实现⽅案是采⽤开源组件 canal 来监听数据库的 binlog,将数据库修改同步到消息队列,再由数据同步⼯具监听消息写⼊新库。架构⽅案并不复杂,但是这个环节要注意的是数据⼀致性问题,增量数据不能丢数据,同时要控制单⾏数据的顺序写⼊,防⽌出现 ABA 的问题。
第三步:处理读流量灰度上线。根据公司业务的敏感度,进⾏灰度上线,测试读流量是否正常,直⾄完成所有的读流量切换到新库的过程。此时我们服务的状态对于数据库来讲就是⼀个写⽼库,读新库的状态。此环节要注意的是业务对数据⼀致性的敏感度问题,因为⽼库到新库⼤概是秒级的延迟,在部分对⼀致性要求较⾼的敏感场景需要考虑读⽼库。
第四步:将应⽤的所有读流量切到新库上,保持写⽼库读新库的状态。
第五步:处理写流量的过程,为了考虑降低程序的复杂度,没有考虑灰度发布的场景,当然灰度的⽅案也是可以做到的,此处不过多展开。我们的做法是将新库数据回写到⽼库,来⽀持回滚策略,然后⼀次发布将所有流量统⼀切到新库。(此⽅案风险较⾼,可能会对⼤⾯积⽤户产⽣影响,尽量在测试环境进⾏充分评估,需要关注代码覆盖率和性能测试是否达标。)
⾄此就完成了整个发布上线的过程,由于借助了 ShardingSphere-JDBC 中间件对 SQL 改写和结果归并的能⼒完成整个改造的成本不⾼,对代码⼏乎没有侵⼊性,上线过程也⽐较平滑。
另外还有⼀些在接⼊ ShardingSphere-JDBC ⽅案⾥可能需要注意的问题。
-
ShardingSphere-JDBC 对于数据插⼊逻辑⾥有个默认处理,在 SQL 内不存在分⽚列进⾏数据插⼊操作时,会导致每个分⽚表都插⼀条相同的数据。
-
ShardingSphere-JDBC 对于批量的 SQL 语义分析时,只会解析第⼀条 SQL 的逻辑表,会导致执⾏报错。这个问题已经反馈给官⽅,近期应该会修复此问题。另外官⽅也提供了详细的 SQL 示例,详细列举了哪些在⽀持的范围内,开发之前需要详细的阅读⽂档。
-
ShardingSphere-JDBC 连接模式的选择。
从资源控制的角度看,业务⽅访问数据库的连接数量应当有所限制。它能够有效地防⽌某⼀业务操作过多的占⽤资源,从⽽将数据库连接的资源耗尽,以至于影响其他业务的正常访问。特别是在⼀个数据库实例中存在较多分表的情况下,⼀条不包含分⽚键的逻辑 SQL 将产⽣落在同库不同表的⼤量真实 SQL,如果每条真实 SQL 都占⽤⼀个独⽴的连接,那么⼀次查询⽆疑将会占⽤过多的资源。
从执⾏效率的角度看,为每个分⽚查询维持⼀个独⽴的数据库连接,可以更加有效的利⽤多线程来提升执⾏效率。为每个数据库连接开启独⽴的线程,可以将 I/O 所产⽣的消耗并⾏处理,为每个分⽚维持⼀个独⽴的数据库连接,还能够避免过早的将查询结果数据加载⾄内存。独⽴的数据库连接,能够持有查询结果集游标位置的引⽤,在需要获取相应数据时移动游标即可。
以结果集游标下移进⾏结果归并的⽅式,称之为流式归并,它⽆需将结果数据全数加载⾄内存,可以有效的节省内存资源,进⽽减少垃圾回收的频次。当⽆法保证每个分⽚查询持有⼀个独⽴数据库连接时,则需要在复⽤该数据库连接获取下⼀张分表的查询结果集之前,将当前的查询结果集全数加载⾄内存。因此,即使可以采⽤流式归并,在此场景下也将退化为内存归并。
⼀⽅⾯是对数据库连接资源的控制保护,⼀⽅⾯是采⽤更优的归并模式达到对中间件内存资源的节省,如何处理好两者之间的关系,是 ShardingSphere 执⾏引擎需要解决的问题。具体来说,如果⼀条 SQL 在经过 ShardingSphere 的分⽚后,需要操作某数据库实例下的 200 张表。那么,是选择创建 200 个连接并⾏执⾏,还是选择创建⼀个连接串⾏执⾏呢?效率与资源控制又应该如何抉择呢?
针对上述场景,ShardingSphere 提供了⼀种解决思路。它提出了连接模式(Connection Mode)的概念,将其划分为内存限制模式(MEMORYSTRICTLY)和连接限制模式(CONNECTIONSTRICTLY)这两种类型。
内存限制模式
使⽤此模式的前提是,ShardingSphere 对⼀次操作所耗费的数据库连接数量不做限制。如果实际执⾏的 SQL 需要对某数据库实例中的 200 张表做操作,则对每张表创建⼀个新的数据库连接,并通过多线程的⽅式并发处理,以达成执⾏效率最⼤化。并且在 SQL 满⾜条件情况下,优先选择流式归并,以防⽌出现内存溢出或避免频繁垃圾回收情况。
连接限制模式
使⽤此模式的前提是,ShardingSphere 严格控制对⼀次操作所耗费的数据库连接数量。如果实际执⾏的 SQL 需要对某数据库实例中的 200 张表做操作,那么只会创建唯⼀的数据库连接,并对其 200 张表串⾏处理。如果⼀次操作中的分⽚散落在不同的数据库,仍然采⽤多线程处理对不同库的操作,但每个库的每次操作仍然只创建⼀个唯⼀的数据库连接。这样即可以防⽌对⼀次请求对数据库连接占⽤过多所带来的问题。该模式始终选择内存归并。
内存限制模式适⽤于 OLAP 操作,可以通过放宽对数据库连接的限制提升系统吞吐量;连接限制模式适⽤于 OLTP 操作,OLTP 通常带有分⽚键,会路由到单⼀的分⽚,因此严格控制数据库连接,以保证在线系统数据库资源能够被更多的应⽤所使⽤,是明智的选择。
我们发现在内存限制模式下,过程中会因为 MySQL 的 innodb 引擎的 cache buffer 加载策略导致操作变为 io 密集型,导致 SQL ⼤量超时,解决此问题的办法就是在不变更数据库资源的情况下我们程序多⼀层处理,如果发现没有分⽚键的时候,先在外置索引中确认⼀下分⽚键,再通过分⽚键来进⾏数据库检索。
价值收益
- 性能提升
通过架构重构,有效控制单表数据量,⼤幅缩减慢 SQL,下降将近 50%。
- 节省研发资源,降低成本
引⼊成熟的 Apache ShardingSphere ⽆需重新开发分表组件,降低了研发和踩坑的成本,研发同学只需要集中精⼒处理业务问题。
- 丰富的扩展性
Apache ShardingSphere 对于数据加密,分布式事务,影⼦库等⽅⾯都具备良好的扩展性。
写到最后
在纽曼(Sam Newman)的《微服务设计》⼀书中曾经写到:“与建造建筑物相⽐,在软件中我们会⾯临⼤量的需求变更,使⽤的⼯具和技术也具有多样性。我们创造的东西并不是在某个时间点之后就不再变化了,甚⾄在发布到⽣产环境之后,软件还能继续演化。对于我们创造的⼤多数产品来说,交付到客户⼿⾥之后,还是要响应客户的变更需求,⽽不是简单地交给客户⼀个⼀成不变的软件包。因此架构师必须改变那种从⼀开始就要设计出完美产品的想法,相反我们应该设计出⼀个合理的框架,在这个框架下可以慢慢演化出正确的系统,并且⼀旦我们学到了更多知识,应该可以很容易地应⽤到系统中。” Apache ShardingSphere 正是这样⼀款极具潜⼒的产品,未来⼀定可期。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号