Apache ShardingSphere 如何实现分布式事务
陆敬尚,Apache ShardingSphere Committer,SphereEx 基础设施研发工程师,热爱开源,热爱数据库技术,目前专注于 Apache ShardingSphere 事务模块的开发。

背景
随着业务的快速发展,数据的不断膨胀,流量负载的增加,业务系统遇到了强烈的挑战,对数据库系统可扩展性提出了强烈的诉求。Oracle、MySQL、SQL Server、PostgreSQL 传统单机数据库在线扩展上的问题日益凸显。为了解决扩展问题,出现了可水平扩展的分布式数据库,于是分布式事务问题成为了必须面对的问题。
在这种背景下,ShardingSphere 提供了一套分布式数据库增强计算引擎,通过可插拔架构构建基于数据库之上的生态系统,提供了分布式事务的能力。
事务介绍
事务语义
事务语义定义了四个特性:原子性(Atomicity)、持久性(Durability)、一致性(Consistency)、隔离性(Isolatation)。
原子性(Atomicity)
在分布式场景下,一个事务的操作可能分布在多个物理节点上,保证在多个节点上的操作都成功,或都不成功。
持久性(Durability)
事务提交后,即使断电,事务的操作也是有效的。
一致性(Consistency)
注意:不是 CAP 理论中 C,CAP 中的 C 指的是多副本之间的数据一致问题,这里是不同层次的抽象。
站在用户的角度,数据从一个状态,转移到另外一个状态,两个状态都满足一定的约束。比如:
银行账户数据,账户 A 有 500 元,账户 B 有 500 元,总额 1000,在一个事务中,执行完 A 和 B 的转账操作后,A 和 B 的账户总额还是 1000。
隔离性(Isolatation)
事务并发执行时,保证并发时数据的正确性。比如:两个事务同时修改一条数据,保证两个事务按一定顺序执行,使数据保持在一个正确的状态。
面临的挑战
分布式事务相对单机事务来说面临下面的挑战:
-
原子性,对于单机事务来说,使用 undo log 和 redo log 就可以保证全部提交或者全部回滚。而分布式事务涉及多个物理节点,每个节点情况是不同的,有的节点日志写成功,有的节点日志写不成功。
-
网络的不稳定,对于单机来说,通讯是稳定的,任何操作都可以得到回复,不论成功与失败。而分布式场景下,网络是不稳定的,有可能一个操作是得不到回复的,怎样保证分布式事务的可用性(异常事务的清理、恢复等)是一个问题。
-
并发控制,随着 MVCC 的出现,操作的可线性化(linearizable)成为了刚需。在单机数据库中,可以很容易地产生全局单调递增的事务号,在分布式场景中则不然。
解决方案
原子提交
针对原子性和网络不稳定问题,目前主流的解决方案是 2PC,2PC 定义了两个角色 TM(Transaction Manager)、RM(Resource Manager)。
在分布式场景下,一个事务的操作可能分布在多个节点上,整个事务分两个阶段。
-
第一阶段,RM 锁定相关资源并执行具体操作,返回成功与否给 TM。
-
第二阶段,TM 更具第一阶段 RM 返回的结果,如果全部成功,执行最后的提交操作(事务状态的更改,锁状态删除等),如果有失败的,则回滚。
说明:当然会有一些优化点,比如不涉及多节点的事务转化为一阶段提交等。
注意:两阶段提交协议只解决了提交的问题,要么提交成功,要么不成功,不存在部分成功的中间状态。和事务隔离级别没有必然关系。
并发控制
并发控制,就是保证并发执行的事务在某一种隔离级别上的执行策略。自从多版本控制(MVCC)出现,主流数据库基本抛弃了以前的两阶段锁模型。
并发控制本质是对数据读和写的并发的控制。并发控制的策略决定了隔离级别,并发控制要解决两个问题。
-
决定并发的粒度,比如 MySQL 有行锁(粒度为一行),表锁(粒度为一个表)等
-
三种并发场景的行为:
a. 读读并发,不需要特殊处理,因为不涉及数据的变更。
b. 写写并发,不能同时并发,否则会产生数据混乱。
c. 读写并发,性能优化主要在这里做,有多种并发控制机制,基本都选择了多版本并发控制(MVCC)。
MVCC 并发控制模型
现有主流实现方式有两种:
- 基于事务 ID 和 ReadView
每次事务获取事务 ID,标识事务的开启顺序,通过活跃事务列表来获取快照,存储多个以事务 ID 为版本的数据,从而达到并发控制的效果。MySQL、Postgres-XL 都是采取的这种方案。
- 基于 timestamp
引入 timestamp,通过在数据中添加 timestamp 相关属性,通过对比数据的 commitTs(commit timestamp) 和 Snapshot timestamp 来判断可见性,从而达到可线性化的并发控制效果。Spanner 采用的这种方案。
上面两种方案都离不开全局事务号的生成,常见的全局事务号生成机制有 TrueTime(Spanner 采用),HLC(CockroachDB 采用有误差的 HLC),TSO(Timestamp Oracle),详细原理见参考文献。
ShardingSphere 事务设计
ShardingSphere 事务功能建立在存储 DB 的本地事务之上,提供 LOCAL、XA、BASE 三种模式事务,使用者只需使用原生事务方式(begin/commit/rollback),就可以使用三种模式,在一致性和性能做合适的权衡。
LOCAL
LOCAL 模式直接建立在存储 DB 的本地事务上的,会存在一定的原子性问题,当然性能是最高的,如果可以容忍这个问题,这将是一个不错的选择。
XA
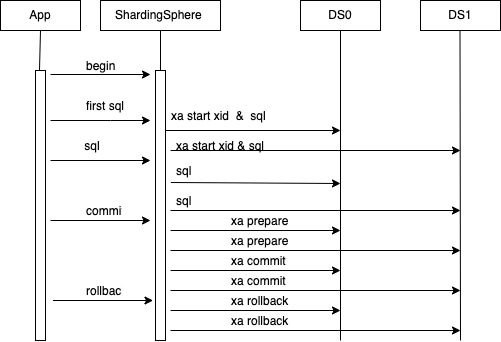
XA 模式,XA 协议是基于 2PC 定义的一套交互协议,定义了 xa start/prepare/end/commit/rollback 等接口,常用的实现有 Narayana、Atomics, ShardingSphere 集成了 Narayana、Atomics 的 XA 实现。
-
app 连接到 Proxy 上,Proxy 创建一个 session 的对象和这个 connection 绑定。
-
app 执行 begin,Proxy 通过 Narayana TM 新建一个逻辑 transaction,和当前 session 绑定。
-
app 执行具体 SQL,session 负责建立到存储 DB 的 connection,并把 connection 通过 Transaction.enlistResource() 接口把 connection 注册到 transaction,执行 XA START {XID} 开启事务,并执行路由改写后的 SQL。
-
app 执行 commit 命令,transaction 中注册的连接存储 DB 的 connection,分别执行 xa prepare,当所有 connection 返回 ok,更新 transaction 状态为 prepared,每个 connection 执行 xa commit,都返回 ok 更新 transaction 状态为 commited,提交成功。如果 prepare 过程部分失败,用户可以通过 rollback 命令出发回滚,不处理则有后台进程进行清理。
-
app 执行 rollback 命令,transaction 中注册的连接存储 DB 的 connection,分别执行 xa rollback,进行回滚。
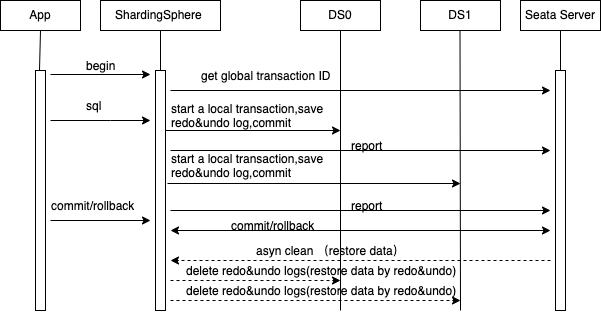
BASE
Base(Basically Available, Soft State, Eventually Consistent)模式,BASE 事务是 CAP 理论中 C 和 A 权衡的结果,Seata 的 AT 模式是 Base 事务的一种实现,ShardingSphere 集成了 Seata 的 AT 实现。
-
app 连接到 Proxy 上,Proxy 创建一个 session 的对象和这个 connection 绑定。
-
app 执行 begin,Proxy 通过 Seata TM 新建一个逻辑 transaction,和当前 session 绑定,并注册到 Seata Server。
-
app 执行一条逻辑 SQL,session 负责建立到存储 DB 的 connection,每个 connection 是 Seata 的 ConnectionProxy 实例,对路由改写后的 actual sql 进行解析, 做一些拦截,比如:如果是修改操作,执行 begin 获取本地锁,执行一条 SQL, 执行 commit 释放本地锁,上报分支事务结果到 Seata Server。
-
app 执行 commit 命令,Proxy 中的 Seata TM 通知 Seata Server 后,直接返回 app,Seata Server 异步和 Proxy 交互,进行删除事务日志。
-
app 执行 rollback 命令,Proxy 中的 Seata TM 通知 Seata Server 后,直接返回 app,Seata Server 异步和 Proxy 交互,执行补偿操作,删除事务日志。
详细流程参考 Seata 官网。
使用示例
安装包准备
以支持较好的 XA,集成 Narayana 的实现为例,进行介绍。由于 Narayana 的 License 问题,不能直接打包到安装包内,需要添加额外的依赖。
根据官网下载好安装包,解压到 ${ShardingSphere} 目录,往 ${ShardingSphere}/lib 目录下添加以下 jar 包。(下载地址:https://mvnrepository.com/)
jta-5.12.4.Final.jar
arjuna-5.12.4.Final.jar
common-5.12.4.Final.jar
jboss-connector-api_1.7_spec-1.0.0.Final.jar | ------------------------------------------------------------------------------------------------------------------------------------
jboss-logging-3.2.1.Final.jar | ------------------------------------------------------------------------------------------------------------------------------------
jboss-transaction-api_1.2_spec-1.0.0.Alpha3.jar | ------------------------------------------------------------------------------------------------------------------------------------
jboss-transaction-spi-7.6.0.Final.jar
mysql-connector-java-5.1.47.jar | ------------------------------------------------------------------------------------------------------------------------------------
narayana-jts-integration-5.12.4.Final.jar
shardingsphere-transaction-xa-narayana-5.1.1-SNAPSHOT.jar
MySQL 实例准备
-
准备两个 MySQL 实例,127.0.0.1:3306,127.0.0.1:3307。
-
两个 MySQL 实例分别创建用户 root, 密码为 12345678。
-
两个 MySQL 实例分别创建 test 库。
ShardingSphere-Proxy 配置
修改 server.yaml 事务配置
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
- !TRANSACTION
defaultType: XA
providerType: Narayana
修改 conf/conf-sharding.yaml
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/test?serverTimezone=UTC&allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 12345678
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://127.0.0.1:3307/test?serverTimezone=UTC&allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 12345678
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
account:
actualDataNodes: ds_${0..1}.account${0..1}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: account_inline
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
defaultDatabaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${id % 2}
account_inline:
type: INLINE
props:
algorithm-expression: account${id % 2}
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
启动ShardingSphere-Proxy
参考如下命令启动 Proxy:
cd ${ShardingSphere}
./bin/start.sh
使用 ShardingSphere-Proxy
使用 MySQL Client 连接 ShardingSphere-Proxy 进行测试,参考如下命令。
mysql -h127.0.0.1 -P3307 -uroot -proot
mysql> use sharding_db;
Database changed
mysql> create table account(id int, balance float ,transaction_id int);
Query OK, 0 rows affected (0.12 sec)
mysql> select * from account;
Empty set (0.02 sec)
mysql> begin;
Query OK, 0 rows affected (0.09 sec)
mysql> insert into account(id, balance, transaction_id) values(1,1,1),(2,2,2);
Query OK, 2 rows affected (0.53 sec)
mysql> select * from account;
+------+---------+----------------+
| id | balance | transaction_id |
+------+---------+----------------+
| 2 | 2.0 | 2 |
| 1 | 1.0 | 1 |
+------+---------+----------------+
2 rows in set (0.03 sec)
mysql> commit;
Query OK, 0 rows affected (0.05 sec)
mysql> select * from account;
+------+---------+----------------+
| id | balance | transaction_id |
+------+---------+----------------+
| 2 | 2.0 | 2 |
| 1 | 1.0 | 1 |
+------+---------+----------------+
2 rows in set (0.02 sec)
未来规划
现在 ShardingSphere 的分布式事务集成了第三方的 2PC 实现方案,提供了原子性的保证,隔离性依赖于存储 DB 的隔离保证,提供了可用的事务功能。未来基于全局 Timestamp 实现 MVCC,结合 2PC,对事务隔离语义提供更好的支持。欢迎大家关注 ShardingSphere 的成长。
如果大家对 Apache ShardingSphere 有任何疑问或建议,欢迎在 GitHub issue 列表提出,或可前往中文社区交流讨论。
GitHub issue:https://github.com/apache/shardingsphere/issues
贡献指南:https://shardingsphere.apache.org/community/cn/contribute/
中文社区:https://community.sphere-ex.com/
参考文献
1.ACID wiki:https://en.wikipedia.org/wiki/ACID
2.ANSI isolation levels:https://renenyffenegger.ch/notes/development/databases/SQL/transaction/isolation-level
3.《Distributed Transactions Are Evil》:https://wiki.c2.com/?DistributedTransactionsAreEvil
4.《Distributed transactions and why you should care》:https://towardsdatascience.com/distributed-transactions-and-why-you-should-care-116b6da8d72
5.《Fault-Tolerant Stream Processing at Internet Scale》:http://static.googleusercontent.com/media/research.google.com/en/us/pubs/archive/41378.pdf
6.《Oracle Two Phase Commit 2PC Tips》:http://www.dba-oracle.com/ttwophasecommit2pc.htm
7.《2PC: Concurrency Control and Recovery in Database Systems》:https://courses.cs.washington.edu/courses/cse551/09au/papers/CSE550BHG-Ch7.pdf
8.《An Empirical Evaluation of In-Memory Multi-Version Concurrency Control》:https://15721.courses.cs.cmu.edu/spring2018/papers/05-mvcc1/wu-vldb2017.pdf
9.《Concurrency Control And Recovery In Database Systems》:https://courses.cs.washington.edu/courses/cse551/09au/papers/CSE550BHG-Ch7.pdf
10.《Optimistic Concurrency Control》:https://15721.courses.cs.cmu.edu/spring2018/slides/04-occ.pdf)
11.《Base: An Acid Alternative》:https://queue.acm.org/detail.cfm?id=1394128
12.《Jepsen: CockroachDB beta-20160829》:https://jepsen.io/analyses/cockroachdb-beta-20160829
13.《Spanner: Google’s Globally-Distributed Database》:https://static.googleusercontent.com/media/research.google.com/en//archive/spanner-osdi2012.pdf


 浙公网安备 33010602011771号
浙公网安备 33010602011771号