
Python文件操作、函数、装饰器基础
一、文件操作
说明:
文件操作步骤:1)、打开文件,产生文件文件句柄
2)、操作文件句柄(读、写、追加等操作)
3)、关闭文件
1、文件操作之r、rb、r+、r+b


# r = 只读模式,读的时候注意文件编码,如果被读文件是gbk编码,读的时候需指定encoding = "gbk"(在不知道文件编码的情况下,可以通过第三方模块chardet获取文件编码) # rb = 以二进制方式读,一般操作图片、视频等非文字类文件。 # r+ = 以读写的方式读,先读在写入,顺序不能变! # r+b = 以二进制的方式进行读写。 # read() 文件路径可以使用绝对路径和相对路径,如果文件和py在同一目录则使用相对路径 f1 = open('D:\logo.txt', encoding='utf-8', mode='r') content = f1.read() print(content) f1.close() # read 全部读出,mode默认是r f1 = open('log1', encoding='utf-8') content = f1.read() print(content) f1.close() # read(n) 在mode=r的情况下按照字符读取 f1 = open('log1', encoding='utf-8') content = f1.read(5) # r 模式 按照字符读取。 print(content) f1.close() # read(n) 在mode=rb的情况下按照字节读取,注意编码中文占的位数,位数不对会乱码 f1 = open('log1', mode='rb') content = f1.read(3) # rb模式 按照字节读取。 print(content.decode('utf-8')) # utf-8 一个中文占3个字节 f1.close() # readline() 逐行读取,每次只读取一行 f1 = open('log1', encoding='utf-8') print(f1.readline()) # 读取第一行 print(f1.readline()) # 读取第二行 print(f1.readline()) # 读取第三行 print(f1.readline()) # 读取第四行 f1.close() # readlines() 将每一行作为列表的一个元素并返回这个列表 f1 = open('log1', encoding='utf-8') print(f1.readlines()) f1.close() # for循环 推荐这一种,只占用一行内存空间 f1 = open('log1', encoding='utf-8') for i in f1: print(i) f1.close() # r+ 读写 f1 = open('log1', encoding='utf-8', mode='r+') print(f1.read()) f1.write('666') f1.close() # seek 光标 按照字节去运转。 # 读写模式下,先写后读需要调整光标,不建议这样写 f1 = open('log1', encoding='utf-8', mode='r+') f1.seek(0, 2) # 调整光标到文件尾 f1.write('6666') f1.seek(0) # 调整光标到文件头 print(f1.read()) f1.close() # rb 以二进制方式读 f2 = open('log1', mode='rb') print(f2.read()) f2.close()
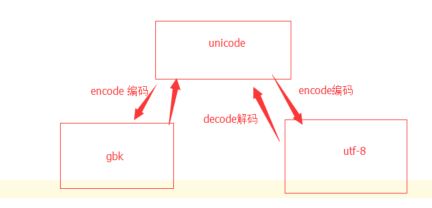
# 编码的补充: s = "中国" # 字符串在python3中为unicode编码 ,python2中为ascii编码 s1 = s.encode("gbk") # s1是str(即unicode) 转换成 gbk编码的bytes类型 # s1 = b'\xd6\xd0\xb9\xfa' # 以GBK编码存储的bytes类型 s2 = s1.decode('gbk') # s2是由gbk编码的bytes类型 转换成str(即unicode)类型 # s2 = "中国" # s2 = s1 s3 = s2.encode('utf-8') # s3 是str(即unicode) 转换成 utf-8编码的bytes类型,gbk不能直接转换成utf-8,需要先转成unicode类型 # s3 = b'\xe4\xb8\xad\xe5\x9b\xbd' # 一行命令实现gbk(bytes)到utf-8(bytes)的转换 s4 = b'\xd6\xd0\xb9\xfa'.decode('gbk').encode('utf-8') # s4 = b'\xe4\xb8\xad\xe5\x9b\xbd'
图示:
2、文件操作之w、wb、w+、w+b
# 1、没有文件,则创建文件,写入内容 # 2、文件已经存在,则将原文件所有内容清空,写入新内容。 # w模式, f1 = open('log2', encoding='utf-8', mode='w') f1.write('alex是披着高富帅外衣的纯屌丝.....') f1.close() # wb模式,以bytes方式存储,需要指定编码类型 f1 = open('log2', mode='wb') f1.write('alex是披着高富帅外衣的纯屌丝.....'.encode('utf-8')) f1.close() # w+ 写读模式,写入一行光标跑到尾部,读不到内容,需要移动光标到头部 f1 = open('log2', encoding='utf-8', mode='w+') f1.write('666') f1.seek(0) print(f1.read()) f1.close()
3、文件操作之a、ab、a+、a+b
# a 追加,不会删除原文件内容 f1 = open('log2', encoding='utf-8', mode='a') f1.write('\n老男孩') f1.close() # ab 以二进制方式追加,需要指定编码格式 f1 = open('log3', mode='ab') f1.write('\n老男孩'.encode("gbk")) f1.close() # a+ 追加写 和w+类似。同样需要调整光标位置 f1 = open('log2', encoding='utf-8', mode='a+') f1.write('fdsafdsafdsagfdg') f1.seek(0) print(f1.read()) f1.close()
4、文件操作之其他方法
#其他操作方法: # readable writable 判断是否可以读和可写返回True或False f1 = open('log2', encoding='utf-8', mode='w') f1.write('fdsafdsafdsagfdg') print(f1.readable()) print(f1.writable()) f1.close() # tell 告诉指针的位置 f1 = open('log2', encoding='utf-8', mode='w') f1.write('fdsafdsafdsagfdg') print(f1.tell()) f1.close() # seek(参数),seek(0)调至文件最开始,seek(0,2)调至最后。按照字节去调整光标
# with open() as ,会自动关闭文件 with open('log1', encoding='utf-8') as f1: print(f1.read()) # 可以同时操作多个文件 with open('log1', encoding='utf-8') as f1,\ open('log2', encoding='utf-8', mode='w')as f2: print(f1.read()) f2.write('777')
# 文件的改 # 1,打开原文件,产生文件句柄。 # 2,创建新文件,产生文件句柄。 # 3,读取原文件,进行修改,写入新文件。 # 4,将原文件删除。 # 5,新文件重命名原文件。 import os """ log1的内容: 你好,我是坏人! 你好,我是坏人! 你好,我是坏人! 你好,我是坏人! 需求,把所有的坏人变成好人 """ # 方法1 read会把文件的所有内容读取出来在进行修改,如果文件很大则会卡死 # readlines 同样是读取文件的所有内容,并按行为单个元素存在一个列表里。 with open("log1", encoding="utf-8") as f1,\ open("log1.bak", encoding="utf-8", mode="a") as f2: f2.write(f1.read().replace("好人", "坏人")) os.remove("log1") os.rename("log1.bak", "log1") # 方法2,不占用内存空间。处理大文件效果更好 with open("log1", encoding="utf-8") as f1,\ open("log1.bak", encoding="utf-8", mode="a") as f2: for i in f1: f2.write(i.replace("坏人", "好人")) os.remove("log1") os.rename("log1.bak", "log1")
二、函数基础
说明:
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。函数能提高应用的模块性,和代码的重复利用率。
1、为什么要用函数,示例如下
# 分别计算列表和字符串的长度,不适用内置函数len()的情况下 li = [1, 2, 3, 43, 'fdsa', 'alex'] count = 0 for i in li: count += 1 print(count) s1 = 'fdsgdfkjlgdfgrewioj' count = 0 for i in s1: count += 1 print(count) # 发现问题,计算列表和字符串长度代码是重复的。 li = [1, 2, 3, 43, 'fdsa', 'alex'] s1 = 'fdsgdfkjlgdfgrewioj' # 定义my_len函数 def my_len(argv): count = 0 for i in argv: count += 1 return count print(my_len(li)) print(my_len(s1))
2、函数的返回值 return
# 函数的返回值 return # 1、遇到return,结束函数。不执行return下面的代码和break类型 # 下面代码不会的打印3和4 def func1(): print(1) print(2) return print(3) print(4) func1() # 2、给函数的调用者(执行者)返回值。 """ 无 return 则返回None return 不写 或者 None 返回None return 返回单个数. return 返回多个数,将多个数放在元组中返回。 """ # 示例1: s1 = "1235sdafadf234afsfdafas" def my_len(argv): count = 0 for i in argv: count += 1 return count print(my_len(s1),type(my_len(s1))) # 返回值类型和原来保持一致 # 示例2(返回多个值,多个值存储在元组中返回): def my_len(): count = 0 for i in s1: count += 1 return 666, 222, count, '老男孩' print(my_len(),type(my_len())) # 示例3,返回值的分别赋值: def my_len(): count = 0 for i in s1: count += 1 return 666, 222, count ret1, ret2, ret3 = my_len() # (666, 222, 23,) print(ret1) print(ret2) print(ret3)
3、函数的传参
4、函数的参数类型
#函数的传参 li = [1, 2, 3, 43, 'fdsa', 'alex'] s1 = 'fdsgdfkjlgdfgrewioj' def my_len(argv): # 函数的定义()放的是形式参数,形参 count = 0 for i in argv: count += 1 return count ret = my_len(li) # 函数的执行() 放的是实际参数,实参 print(ret)
1)从实参角度:
a、位置参数,必须按顺序一一对应
# 位置参数,必须按顺序一一对应。 def func1(x,y): print(x,y) func1(1, 2) # x = 1, y = 2
b、关键字参数,可以不分顺序,但必须一一对应
#关键字参数,可以不分顺序,但参数必须一一对应。 def func1(x, y, z): print(x, y, z) func1(y=2, x=1, z=5)
c、混合参数(位置参数和关键字参数混合),位置参数同样是一一对应,关键字参数必须在位置参数后面
# 三元运算 # 比较两个数的大小,普通写法 def max(a, b): if a > b: return a else: return b print(max(100, 102)) # 三元运算写法 def max(a, b):return a if a > b else b print(max(100,102))
# 混合参数。位置参数顺序一一对应 且关键字参数必须在位置参数后面。 def func2(argv1,argv2,argv3): print(argv1) print(argv2) print(argv3) func2(1, 2, argv3=4)
2)从形参角度:
a、位置参数,必须和实参按顺序一一对应
# 位置参数。 按顺序必须一一对应 def func1(x,y): print(x,y) func1(1,2)
b、默认参数,顺序必须在位置参数的后面
# 默认参数。 必须在位置参数后面。 # 统计姓名和性别 def register(name, sex='男'): with open('register', encoding='utf-8', mode='a') as f1: f1.write('{} {}\n'.format(name, sex)) while True: username = input('请输入姓名 q退出:') if not username:continue if username.upper() == 'Q':break sex = input('请输入性别:') if not sex: register(username) else: register(username, sex)
c、混合参数(*args和**kwargs),也叫万能参数
# 动态参数 *args,**kwargs 万能参数 # *args 以元组的方式存储所有的位置参数 , **kwargs 以字典的方式存储所有关键字参数 def func2(*args, **kwargs): print(args) # 元组(所有的位置参数) print(kwargs) # 字典(所有的关键字参数) func2(1, 2, 3, 4, 5, 6, 7, 11, 'alex', '老男孩', a='ww', b='qq', c='222') # 当有位置参数,默认参数,动态参数(*args)的时候,顺序如下: # 位置参数--->*args--->默认参数 def func3(a, b, *args, sex='男'): print(a) print(b) print(sex) print(args) func3(1,2,'老男孩','alex','wusir',sex='女') # 当有位置参数,默认参数,动态参数(*args和**kwargs)的时候,顺序如下: # 位置参数--->*args--->默认参数--->**kwargs def func3(a,b,*args,sex='男',**kwargs): print(a) print(b) print(sex) print(args) print(kwargs) func3(1,2,'老男孩','alex','wusir',name='alex',age=46) # 函数的定义: * 聚合。 def func1(*args,**kwargs): print(args) print(kwargs) # 把以下数据类型以元素的方式分别传给动态参数 l1 = [1, 2, 3, 4] t1 = (1, 2, 3, 4) l2 = ['alex', 'wusir', 4] dic1 = {'name1': 'alex'} dic2 = {'name2': 'laonanhai'} # 函数的执行:* 打散功能。 func1(l1, t1, l2, dic1, dic2) # 错误写法 func1(*l1, *l2, *t1, **dic1, **dic2) # 正确写法等于 func1(1,2,3,4,'alex','wusir',4,1,2,3,4,"name1"="alex","name2"="laonanhai")
三、函数进阶
1、名称空间
def func1(): m = 1 print(m) print(m) #这行报的错 # 报错了: # NameError: name 'm' is not defined
上面为什么会报错呢?现在我们来分析一下python内部的原理是怎么样:
我们首先回忆一下Python代码运行的时候遇到函数是怎么做的,从Python解释器开始执行之后,就在内存中开辟里一个空间,每当遇到一个变量的时候,就把变量名和值之间对应的关系记录下来,但是当遇到函数定义的时候,解释器只是象征性的将函数名读如内存,表示知道这个函数存在了,至于函数内部的变量和逻辑,解释器根本不关心。
等执行到函数调用的时候,Python解释器会再开辟一块内存来储存这个函数里面的内容,这个时候,才关注函数里面有哪些变量,而函数中的变量回储存在新开辟出来的内存中,函数中的变量只能在函数内部使用,并且会随着函数执行完毕,这块内存中的所有内容也会被清空。
我们给这个‘存放名字与值的关系’的空间起了一个名字-------命名空间。
代码在运行伊始,创建的存储“变量名与值的关系”的空间叫做全局命名空间;
在函数的运行中开辟的临时的空间叫做局部命名空间。
1)全局命名空间
2)局部命名空间:存入函数里面的变量与值的关系,随着函数的执行结束,局部名称空间消失。
3)内置命名空间
4)命名空间加载顺序:内置命名空间(程序运行前加载)->全局命名空间(程序运行中:从上到下加载)->局部命名空间(程序运行中:调用时才加载)
5)命名空间取值顺序:
在局部调用:局部命名空间->全局命名空间->内置命名空间
在全局调用:全局命名空间->内置命名空间
2、作用域
作用域就是作用范围,按照生效范围可以分为全局作用域和局部作用域。
1)全局作用域:包含内置名称空间、全局名称空间,在整个文件的任意位置都能被引用、全局有效
2)局部作用域:局部名称空间,只能在局部范围内生效
3)globals和locals方法
# global和locals 是以字典的方式返回命名空间 global 使用于全局 locals适用于局部 # 在全局执行,locals 和 globals返回值是一样的 print(globals()) print(locals()) # 在局部执行,locals只取局部名命名空间,globals取全局所有命名空间 name = "123" def fun1(): name1 = "123" print(globals()) print(locals()) fun1()
4)global关键字,nonlocal关键字。
global:
1,声明一个全局变量。
2,在局部作用域想要对全局作用域的全局变量进行修改时,需要用到 global(限于字符串,数字)。
def func(): global a a = 3 func() print(a) count = 1 def search(): global count count = 2 search() print(count)
ps:对可变数据类型(list,dict,set)可以直接引用不用通过global。
li = [1,2,3] dic = {'a':'b'} def change(): li.append('a') dic['q'] = 'g' print(dic) print(li) change() print(li) print(dic) 对于可变数据类型的应用举例
nonlocal:
1,不能修改全局变量。
2,在局部作用域中,对父级作用域(或者更外层作用域非全局作用域)的变量进行引用和修改,并且引用的哪层,从那层及以下此变量全部发生改变。
def add_b(): b = 42 def do_global(): b = 10 print(b) def dd_nonlocal(): nonlocal b b = b + 20 print(b) dd_nonlocal() print(b) do_global() print(b) add_b()
3、闭包
# 闭包 内层函数对外层函数非全局变量的引用,外层函数的返回值是内层函数。叫做闭包 # 闭包的好处:如果python 检测到闭包, # 他有一个机制,你的局部作用域不会随着函数的结束而结束。 def wrapper(): name1 = '老男孩' def inner(): print(name1) inner() wrapper() # 判断是不是闭包 def wrapper(): name1 = '老男孩' def inner(): print(name1) inner() print(inner.__closure__) # 返回cell....则是闭包 wrapper() # 判断是不是闭包 name1 = '老男孩' def wrapper(): def inner(): print(name1) inner() print(inner.__closure__) # 返回None则不是闭包 wrapper() # 判断是不是闭包 name = 'alex' def wrapper(argv): def inner(): print(argv) inner() print(inner.__closure__) # cell wrapper(name)
# 闭包-小爬虫
from urllib.request import urlopen def index(): url = "http://www.cnblogs.com/jin-xin/articles/8259929.html" def get(): return urlopen(url).read() return get content1 = index()() print(content1)
四、装饰器初识
说明:
装饰器:在不改变原函数即原函数的调用的情况下,为原函数增加一些额外的功能,如打印日志,执行时间,登录认证等等。
import time # 装饰器:在不改变原函数即原函数的调用的情况下,为原函数增加一些额外的功能,如打印日志,执行时间,登录认证等等。 # 最简单版的装饰器,测试函数执行效率 def timer(f1): # f1 = 被装饰的函数名 def inner(): start_time = time.time() f1() end_time = time.time() print('此函数的执行效率%s' %(end_time-start_time)) return inner def func1(): print('晚上回去吃烧烤....') time.sleep(0.3) func1 = timer(func1) func1() def func2(): print('晚上回去喝啤酒....') time.sleep(0.3) func2 = timer(func2) func1() # @装饰器名称,装饰器简写 def timer(f1): # f1 = 被装饰的函数名 def inner(): start_time = time.time() f1() end_time = time.time() print('此函数的执行效率%s' % (end_time-start_time)) return inner @timer # func1 = timer(func1) def func1(): print('晚上回去吃烧烤....') time.sleep(0.3) @timer # func2 = timer(func2) def func2(): print('晚上回去喝啤酒....') time.sleep(0.3) func1() func2() #被装饰函数带参数 def timer(f1): # f1 = 被装饰的函数名 def inner(*args, **kwargs): start_time = time.time() f1(*args, **kwargs) end_time = time.time() print('此函数的执行效率%s' %(end_time-start_time)) return inner @timer # func1 = timer(func1) inner def func1(a, b): print(a, b) print('晚上回去吃烧烤....') time.sleep(0.3) func1(1, 2) # inner(1,2) #被装饰函数带返回值 def timer(f1): # f1 = 被装饰函数名 def inner(*args, **kwargs): start_time = time.time() ret = f1(*args, **kwargs) # func1() end_time = time.time() print('此函数的执行效率%s' %(end_time-start_time)) return ret return inner @timer # func1 = timer(func1) def func1(a, b): print(a, b) print('晚上回去吃烧烤....') time.sleep(0.3) return 666 ret2 = func1(111,222) # inner(111,222) print(ret2) def wrapper(f1): def inner(*args,**kwargs): '''执行函数之前的操作''' ret = f1(*args,**kwargs) '''执行函数之后的操作''' return ret return f1
五、装饰器进阶
六、作业(博客园登录)
#!/usr/bin/env python3 # day3博客地址:http://www.cnblogs.com/spf21/p/8850060.html """作业需求 1),启动程序,首页面应该显示成如下格式: 欢迎来到博客园首页 1:请登录 2:请注册 3:文章页面 4:日记页面 5:评论页面 6:收藏页面 7:注销 8:退出程序 2),用户输入选项,3~6选项必须在用户登录成功之后,才能访问成功。 3),用户选择登录,用户名密码从register文件中读取验证,三次机会,没成功则结束整个程 序运行,成功之后, 可以选择访问3~6项. 4),如果用户没有注册,则可以选择注册,注册成功之后,可以自动完成登录,然后进入首页选择。 5),注销用户是指注销用户的登录状态,使其在访问任何页面时,必须重新登录。 6),退出程序为结束整个程序运行。 测试账号:wxx 密码:123 测试账号:spf 密码:123 """ import time def run_log(func, user): """记录用户调用函数日志""" with open("./file/fun_run_log", mode="a", encoding="utf-8") as f1: timer = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) f1.write("时间:%s 用户:%s 运行函数:%s\n" % (timer, user, func)) def wrapper_outer(run_log_func): def wrapper(main_func): def inner(*args, **kwargs): if user_status["user"] and user_status["status"]: result = main_func(*args, **kwargs) if result != None: return result else: str_func = "%s " % (main_func,) if "blog_exit" in str_func: print("\033[0;31;0mBye Bye!!!\033[0m".center(40, "-")) exit() if "log_out" in str_func: print("\033[0;31;0m用户未登录!!!\033[0m") exit() print("\n\033[0;35;0m>>>欢迎登录:\033[0m") count = 0 while count < 3: username = input("\033[0;35;0m请输入用户名:\033[0m").strip() password = input("\033[0;35;0m请输入密码:\033[0m").strip() if not username or not password: print("\033[0;35;0m用户名或密码不能为空\033[0m") with open("./file/user_list") as f1: for i in f1: user, passwd = i.split() if username == user and password == passwd: print("\n\033[0;35;0m登录成功!欢迎:<%s>\n\033[0m" % (username,)) user_status["user"] = username user_status["status"] = True return username else: print("\033[0;35;0m用户名或者密码错误,请重试!\033[0m") count += 1 else: exit() res_run_log = run_log_func(main_func, user_status["user"]) if res_run_log != None: return run_log_func return inner return wrapper @wrapper_outer(run_log) def login(): if user_status["user"] and user_status["status"]: print("\033[0;31;0m%s用户已经登录!!!\033[0m" % (user_status["user"],)) def registered(): """注册""" print("\033[0;35;0m\n>>>欢迎注册:") if user_status["user"] and user_status["status"]: print("\033[0;31;0m 当前用户:%s 请先注销在注册!\033[0m" % (user_status["user"],)) else: flag = True while flag: username = input("\033[0;35;0m请输入用户名:").strip() first_password = input("\033[0;35;0m请输入密码:").strip() second_password = input("\033[0;35;0m请确认密码:").strip() if not username or not first_password or not second_password: print("\033[0;35;0m用户名或者密码不能为空!") continue if first_password != second_password: print("\033[0;35;0m两次密码输入不一致,请重新输入!") continue with open("./file/user_list", mode="r") as f1, open("./file/user_list", mode="a") as f2: for i in f1: if username in i: print("\033[0;35;0m用户名已经存在!请重新注册") go_on = input("是否继续尝试Y/N:") if go_on.upper() == "Y": break elif go_on.upper() == "N": flag = False break else: print("\033[0;31;0m请输入正确的字符!!!\033[0m") else: f2.write("%s %s\n" % (username, second_password)) print("\033[0;35;0m注册成功!<%s> 已经自动登录!" % (username,)) user_status["user"] = username user_status["status"] = True return username @wrapper_outer(run_log) def article_page(): """文章页面""" print("文章页面".center(60, "-")) @wrapper_outer(run_log) def logs_page(): """日记页面""" print("日记页面".center(60, "-")) @wrapper_outer(run_log) def comment_page(): """评论页面""" print("评论页面".center(60, "-")) @wrapper_outer(run_log) def collection_page(): """收藏页面""" print("收藏页面".center(60, "-")) @wrapper_outer(run_log) def log_out(): """注销""" if user_status["user"] and user_status["status"]: print("\033[0;31;0m%s 用户已经注销!\033[0m" % (user_status["user"])) user_status["user"] = None user_status["status"] = False else: print("\033[0;31;0m用户未登录!!!\033[0m") @wrapper_outer(run_log) def blog_exit(): """退出""" print("\033[0;31;0mBye Bye!!!\033[0m".center(40, "-")) exit() # user_status 用于存储用户状态 user_status = {"user": None, "status": False} menu = {1: ['请登录', login], 2: ['请注册', registered], 3: ['文章页面', article_page], 4: ['日记页面', logs_page], 5: ['评论页面', comment_page], 6: ['收藏页面', collection_page], 7: ['注销', log_out], 8: ['退出程序', blog_exit]} print("\033[0;31;0m欢迎来到博客园首页\033[0m".center(60, " ")) while True: # 打印菜单 print("-" * 64) for k, v in menu.items(): print("\033[0;34;0m%s %s\033[0m" % (k, v[0])) print("-" * 64) choice = input("\n\033[0;36;0m请选择菜单:\033[0m").strip() if choice.isdigit(): choice = int(choice) # 获取字典里面菜单key,如果不存在则返回1 if menu.get(choice, 1) != 1: # menu[choice][1] = 字典里面存的函数命 res = menu[choice][1] res() else: print("你输入的菜单ID不存在!") else: print("请输入正确的数字ID!")
./file/user_list admin 123 wxx 123 spf 123 allen 123 zmm 123

 浙公网安备 33010602011771号
浙公网安备 33010602011771号