数据库之表与表之间建关系
一、一对多关系
定义一张部门员工表

我们就会发现把所有数据存放于一张表的弊端:
1.组织结构不清晰
2.浪费硬盘空间
3.扩展性极差
这样的弊端是不是看着很眼熟,没错!这就类似于我们代码全部写在一个py文件中,那么当我们发现一个py文件中的代码冗余度很高会怎么做呢?当然就是要进行解耦合!
那么我再来分析这张表数据之间的关系:多个用户对应一个部门,一个部门就对应了多个用户,那么他们之间的关系就应该是一对多的关系,我们可以将上面的表拆开成两张表,一张是记录用户信息,另一张记录部门信息,再用某种方法使者两张表关联起来,这个方法就是:使用Foreign Key
确立表与表之间的关系一定要换位思考(必须两方面都考虑周全之后才能得出结论)
Foreign Key:外键约束
1.在创建表的时候,必须先创建被关联表
2.插入数据的时候,也必须先插入被关联表的数据
创建表:
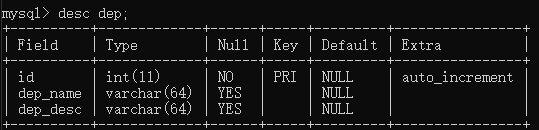
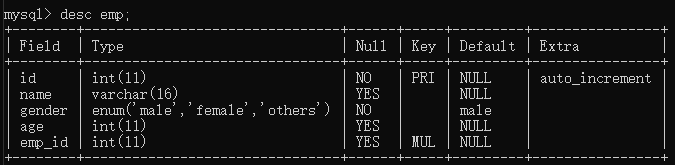
1 #在创建表的时候,一定要先建被关联的表,才能创建关联表 2 create table dep( 3 id int primary key auto_increment, 4 dep_name varchar(64), 5 dep_desc varchar(64) 6 ); 7 8 create table emp( 9 id int primary key auto_increment, 10 name varchar(16), 11 gender enum('male','female','others')not null default 'male', 12 age int, 13 emp_id int, 14 foreign key(emp_id) references dep(id) 15 );
插入记录:
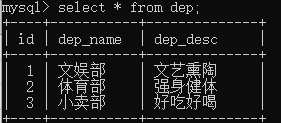
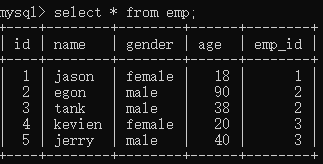
1 #插入记录时,必须先插被关联的表dep,才能插关联表emp 2 insert into dep(dep_name,dep_desc) values 3 ('文娱部','文艺熏陶'), 4 ('体育部','强身健体'), 5 ('小卖部','好吃好喝'); 6 7 insert into emp(name,gender,age,emp_id) values 8 ('jason','female',18,1), 9 ('egon','male',90,2), 10 ('tank','male',38,2), 11 ('kevien','female',20,3), 12 ('jerry','male',40,3);
这样我们就把表都创建好了,并且表与表之间也建立了联系,但是问题也接踵而来,当我想修改emp里的dep_id或dep里面的id(修改成两张表都没有id)或者删除dep表里的记录时都会报错,如下图:


解决方式有两种:
方式1:先删除部门对应的所有的员工,在删除这个部门
★方式2:先把之前创的表删除,先删除员工表,再删除部门表,最后按照下面的方式重新创建表关系
更新与删除都需要考虑到关系与被关联的关系,也就是做到同步更新,同步删除
1 create table dep( 2 id int primary key auto_increment, 3 dep_name varchar(64), 4 dep_desc varchar(64) 5 ); 6 create table emp( 7 id int primary key auto_increment, 8 name varchar(16), 9 gender enum('male','female','others')not null default 'male', 10 age int, 11 emp_id int, 12 foreign key(emp_id) references dep(id) 13 on update cascade 14 on delete cascade 15 );
插入记录:
1 insert into dep(dep_name,dep_desc) values 2 ('文娱部','文艺熏陶'), 3 ('体育部','强身健体'), 4 ('小卖部','好吃好喝'); 5 6 insert into emp(name,gender,age,emp_id) values 7 ('jason','female',18,1), 8 ('egon','male',90,2), 9 ('tank','male',38,2), 10 ('kevien','female',20,3), 11 ('jerry','male',40,3);
删除部门后,对应的部门里面的员工表数据同步对应删除
更新部门后,对应员工表中的标识部门的字段同步更新
二、多对多
例:图书表与作者表之间的关系
我们仍然站在两张表的角度来分析:
1.站在图书表:一本书可不可以有多个作者,可以的!那么就是书籍多对一了作者
2.站在作者表:一个作者可不可以写多本书,也可以!那么就是作者多对一了书籍
双方都能一条数据对应对方多条记录,这种关系就是多对多!
那么我们应该如何创建表呢?图书表需要有一个外键关联作者,作者也需要有一个外键来关联书籍,然后问题来了,那我到底先创建谁呢?怎么解决这个问题呢?
解决方案:创建第三张表,该表中应该有一个foreign key字段关联图书表中的id,还应该有一个foreign key字段来关联作者表中的id,这样这两张表就通过一个中间者,建立起了联系。
1 create table author( 2 id int primary key auto_increment, 3 name char(16) 4 ); 5 6 create table book( 7 id int primary key auto_increment, 8 b_name varchar(32), 9 price int 10 );
插入记录:
1 insert into author(name) values 2 ('jason'), 3 ('tank'), 4 ('egon'); 5 6 insert into book(b_name,price) values 7 ('葵花宝典',66), 8 ('九阴真经',99), 9 ('python大法',88), 10 ('jason写真集',10);
★关键的来了:
创建第三张表格:
1 create table booktoauthor( 2 id int primary key auto_increment, 3 book_id int, 4 author_id int, 5 foreign key(book_id) references book(id) 6 on update cascade 7 on delete cascade, 8 foreign key(author_id) references author(id) 9 on update cascade 10 on delete cascade 11 );
插入记录:
1 insert into booktoauthor(book_id,author_id) values 2 (1,1), 3 (1,3), 4 (2,1), 5 (2,2), 6 (3,1), 7 (3,2), 8 (3,3), 9 (4,1);
至此,多对多的表关系已经建立成功了!
三、一对一
依然是举个栗子:
会员表与顾客表(客户与顾客之间,只要消费了就是会员,反之没有消费的就是顾客)
站在双方的角度来看,会员表的一条记录对应了顾客表的另一条记录,反之也一样,那么这种关系就是一对一的关系
创建表:
1 create table vip( 2 id int primary key auto_increment, 3 birthday data, 4 qq int not null, 5 addr varchar(32), 6 ); 7 8 create table customer( 9 id int primary key auto_increment, 10 name varchar(20) not null, 11 phone int not null, 12 vip_id int unique, #该字段一定是要唯一的 13 foreign key(vip_id) references vip(id) #外键的字段一定要保证unique 14 on update cascade 15 on delete cascade 16 );
插入记录:
1 insert into vip(birthday,qq,addr) values 2 ('1980-8-8',66666666,'上海'), 3 ('1990-8-16',77777777,'香港'), 4 ('2000-6-6',88888888,'台湾'); 5 6 7 insert into customer(name,phone,vip_id) values 8 ('薛之谦',18888888888,1), 9 ('陈赫',16666666666,null), 10 ('邓紫棋',17777777777,2), 11 ('林俊杰',15555555555,null), 12 ('罗志祥',19999999999,3);
总结:三种外键关系都是用foreign key,区别在于如何使用以及其他条件限制即可做出三种关系
四、修改表
语法:
1 #1. 修改表名 2 ALTER TABLE 表名 3 RENAME 新表名; 4 #2. 增加字段 5 ALTER TABLE 表名 6 ADD 字段名 数据类型 [完整性约束条件…], 7 ADD 字段名 数据类型 [完整性约束条件…]; 8 ALTER TABLE 表名 9 ADD 字段名 数据类型 [完整性约束条件…] FIRST; 10 ALTER TABLE 表名 11 ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名; 12 #3. 删除字段 13 ALTER TABLE 表名 14 DROP 字段名; 15 #4. 修改字段 # modify只能改字段数据类型完整约束,不能改字段名,但是change可以! 16 ALTER TABLE 表名 17 MODIFY 字段名 数据类型 [完整性约束条件…]; 18 ALTER TABLE 表名 19 CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…]; 20 ALTER TABLE 表名 21 CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];
五、复制表
语法:
1 # 查询语句执行的结果也是一张表,可以看成虚拟表 2 3 # 复制表结构+记录 (key不会复制: 主键、外键和索引) 4 create table new_service select * from service; 5 6 # 只复制表结构 7 select * from service where 1=2; //条件为假,查不到任何记录 8 9 create table new1_service select * from service where 1=2; 10 11 create table t4 like employees;

