在本篇文章中,我们将按照以下流程来介绍广义线性模型。
- 指数族和最大熵模型
- 基于指数族的广义线性模型——广义线性模型的构成、极大似然估计和求解算法
- 广义线性模型的偏差和分析
1、指数族和最大熵模型
1.1 指数族的形式
指数族是概率统计中最重要的一类分布族。具有以下的一般形式:
f(y)=exp[{θy−b(θ)a(ϕ)}+c(y,ϕ)]
这里指数族标准型相较于我们常见的指数族的形式有所不同。之前我们接触到的指数族的标准形式如下:
f(y|θ)=h(y)c(θ)exp{ k∑i=1ωi(θ)ti(y)}
这里我们将θ和ϕ作为两类不同的参数加以区分。θ反映指数族随机变量的集中趋势,ϕ反映指数族随机变量的离散趋势。
我们称θ为指数族的典型参数(Canonical Parameter),ϕ为指数族的离散参数(Dispersion Parameter),在给定指数族分布时,函数a(.),b(.),c(.,.)是已知函数。
1.2 指数族的性质
设l(θ)为对数似然函数,指数分布族有以下的性质:
- E(l′(θ))=0;E(Y)=b′(θ)
- −E(l′′(θ))=E(l′(θ)2);Var(Y)=a(ϕ)b′′(θ)
证明:
(1)l(θ)=θy−b(θ)a(ϕ)+c(y,ϕ)
E(l′(θ))=E(∂f(y;θ)∂θ/f(y;θ))=∫y∈D∂∂θf(y;θ)dy
由莱布尼茨法则,这里的积分和求导可以互换:
E(l′(θ))=∂∂θ∫y∈Df(y;θ)dx=0
故有:
E(l′(θ))=E[(y−b′(θ))a(ϕ)]=0
E(y)=b′(θ)
(2) ∂∂θE(l′(θ))=∂∂θ∫l′(θ)fy(y;θ)dy
由莱布尼茨定理交换积分求导次序:
∫∂∂θl′(θ)fy(y;θ)dy=∫l′′(θ)fy(y;θ)dy+∫l′(θ)∂∂θfy(y;θ)dy
=∫l′′(θ)fy(y;θ)dy+∫l′(θ)[∂fy(y;θ)∂θ/fy(y;θ)]fy(y;θ)dy
=∫l′′(θ)fy(y;θ)dy+∫l′(θ)2fy(y;θ)dy
=E(l′′(θ))+E(l′(θ)2)=0
又有:
−E(l′′(θ))=−E[∂∂θ(y−b′(θ))a(ϕ)]=E(b′′(θ)a(ϕ))=b′′(θ)a(ϕ)
=E(l′(θ)2)=E((y−b′(θ))2a(ϕ)2)=Var(y)a(ϕ)2
故有:Var(Y)=a(ϕ)b′′(θ)
下面给出后文构建广义线性模型时候的重要定义。由指数族性质知,函数b′(.)将前文提到的典型参数θ和Y的期望E(Y)=μ联系在一起,当b′(.)存在逆函数的时候,令g(.)=(b′)−1(.)有:
b′(θ)=μ⇔(b′)−1(μ)=θ⇔g(μ)=θ
称g(μ)为典型链接函数(Canonical Link function),名如其意,是将随机变量的期望和典型参数链接起来的函数。此外,称b′′(θ)为 方差函数,记作V(θ),
1.3 常见指数族的标准型&典型链接函数
下面是常见的指数族分布随机变量的标准型。
一维正态分布N(μ,σ2):
f(y;μ,σ2)=exp{yμ−μ22σ2−y22σ2−log(√2πσ)}
二项分布b(n,p):
P(Y=y)=exp{ylog(p1−p)+mlog(1−p)+log(my)}
泊松分布P(λ):
P(Y=y)=exp{ylog(λ)−λ−log(y!)}
Gamma分布Gamma(α,αμ):
f(y;α,μ)=1Γ(α)(μyα)α1yexp{−μyα}
f(y;α,μ)=exp{α(−y/μ)+(α−1)log(y)+αlog(α)−log(Γ(α))}
|
θ |
ϕ |
a(ϕ) |
b(θ) |
c(y,θ) |
Canonical Link |
Range |
| Normal |
μ |
σ2 |
σ2 |
θ22 |
−y22σ2−log(√2πσ) |
g(μ)=μ |
(−∞,∞) |
| Binomial |
log(p1−p) |
1 |
1 |
mlog(1−p)=−mlog(1+exp(θ)) |
log(my) |
g(μ)=log(μ) |
(−∞,∞) |
| Possion |
log(λ) |
1 |
1 |
λ=exp(θ) |
log(y!) |
g(μ)=log(μ1−μ) |
(−∞,∞) |
| Gamma |
−1μ |
1α |
1α |
log(u)=−log(−θ) |
(α−1)log(y)+αlog(y)−log(Γ(α)) |
g(μ)=−1μ |
(−∞,0) |
1.4 常见指数族分布的关系
下面我们不假证明的说明指数族分布之间的一些联系。
- Bernoulli→Binomial:概率为p的独立重复的伯努利试验
我们在独立重复实验的背景下做一个推广,我们假定一个独立同分布的实验场景:将单位时间或者空间n等分,每一份上随机事件X都独立等概率发生,且假定单位时间内随机事件X的平均发生次数为λ。后文我们称之为单位时间内推广的独立重复试验场景(很不严谨)。
- Binomial→Possion:在单位时间内推广的独立重复试验场景下,单位时间内事件发生的次数服从参数为λ的Possion分布。时二项分布在n趋于无穷且np=λ的情形下的推广。
- Possion→Gamma(α,λ=α/μ):依旧是在单位时间内推广的独立重复试验场景下,我们假定单位时间内事件X平均发生次数为λ,事件X第α次发生的时间服从Gamma(α,λ=α/μ)。当α=1时,即事件第一次发生的时间服从指数分布Exp(λ)即Gamma(1,λ)。
- 二项分布、泊松分布的正态近似:极限性质下有中心极限性定理中最早的棣莫弗拉普拉斯定理,即二项分布的正态近似。一个更直观的例子是高尔顿板,即一维左右等概率的随机游走。
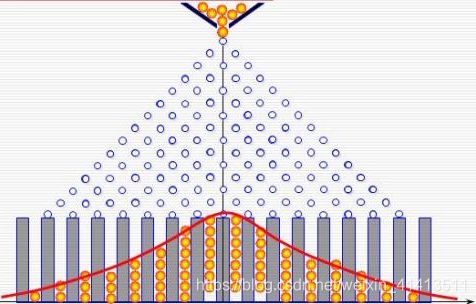
下面是流传已久的机器学习常用分布的关系图:

1.5 指数族与最大熵模型
指数族分布被证实是满足最大熵的一族分布,在自然界中最常见也是我们研究中最偏好的一类概率模型。指数族分布广泛存在于自然界和统计应用当中是有原因的。由以上的关系可以直观体会到这一众指数族分布之间存在的关系,其中很核心的一点是“等概率”,从熵的视角去看,“等概率=最大熵”。
- 最大熵原理
最大熵原理是概率学习模型的一个准则。最大熵原理认为,学习概率模型时,在模型假设空间里,熵最大的模型是最好的模型。
熵是由概率定义的一个随机事件的混乱程度的度量,其在样本空间内的元素等可能发生时达到最大值。
H(X)=−∫X∈Dfx(x)log(fx(x))dx
模型若要熵最大,在已知条件之外应当是等可能地无知的。由此求最大熵模型的问题转化为了以模型熵值为目标函数,以已知条件为约束的优化问题。此处不加证明给出符合最大熵原理的概率模型经证明服从指数族分布。(详细证明见李航《统计学习方法》第六章)。下面是几个给定约束的最大熵分布的例子:

2、基于指数族的广义线性模型
首先回顾一下经典线性模型的假定:
经典线性回归模型的5个假定
Y=XTβ+ϵ
- 假设1 线性假设E(Y|X)=Xβ
- 假设2 X严格外生,E(ϵ|X)=0
- 假设3 E(XX′)非奇异且最小特征值λmin→+∞(n→+∞)
- 假设4 随机误差项条件同方差且条件不相关
- 假设5 随机误差项ϵ∼N(0,σ2I)
当我们模型的响应变量Y是离散型的时候,贸然套用经典的线性回归模型是完全错误的。因此我们基于指数族(不限于离散型)设计了广义的线性模型。对于设计的广义线性模型应当满足以下基本要求:
- 经典的正态假定下线性模型应当是广义回归的特例
- 回归函数应当是关于Xβ的单调函数,以保证我们的系数有更好的解释性
2.1 广义线性模型构成
广义线性模型由三部分构成:响应变量分布、线性预测量和链接函数。
- 响应变量分布
给定观测变量X的条件下,响应变量Y的概率分布属于指数族。f(y|X)=exp([θ(X)y−b(θ(X))]/a(ϕ)+c(y,ϕ))这里我们令典型参数θ=θ(X),表明典型参数θyou观测变量决定
- 链接函数和线性预测量
假定μ(X)=E(Y|X),定义链接函数g(.) (区分这里的链接函数和前文的典型链接函数),g(μ(X))=XTβ,μ(X)=g−1(XTβ)。给定链接函数g(.),若链接函数满足g(.)=(b′)−1时,即链接函数是将条件期望和典型参数链接起来的典型链接函数,可以将典型参数θ(X)写为: θ(X)=(b′)−1(μ(X))=(b′)−1(g−1(XTβ))=(g∘b′)−1(XTβ)=h(XTβ)此处h(XTβ)在g(.)是典型链接函数时,h(XTβ)=XTβ=θ(X).
2.2 广义线性模型的极大似然估计
以往我们处理经典线性模型的参数估计时,更多看到的是最小二乘法的视角下的参数估计,但是极大似然估计法是更加广泛的参数估计方法。在经典线性模型中,极大似然估计和最小二乘法是等价的。
经典线性模型MLE求解参数估计(考虑异方差存在的情形,ϵ∼N(0,Wσ2))
l(β)=−n2log(2π)−n2log(detW)+n∑i=1(Yi−X′iβ)2Wi,i σ2
∝(Y−Xβ)′W−1(Y−Xβ)∝−2β′X′W−1Y+β′X′W−1Xβ
l′(β)∝−2W−1X′Y+2X′W−1Xβ=0
解得:
^β=(X′W−1X)−1X′W−1Y
此处略过对二阶条件得验证,等价于最小二乘法或者最大投影法的角度下的参数估计值
2.2.1 广义线性模型似然函数
- 似然函数
单个样本的似然函数f(Yi|X,θ,ϕ)=exp{(θiyi−b(θi))/ai(ϕ)+c(yi,ϕ)}(注意广义线性模型的典型参数θ 由 Xi 决定,故有下标),我们将θ(X)=(g∘b′)−1(X′β)=h(X′β)带入,写出对数似然函数如下:
ln(β,ϕ)=n∑i=1[Yih(X′iβ)−b(h(X′β))]/a(ϕ)+∑i=1nc(Yi,ϕ)
最大似然估计即求解:
(^βmle,^ϕmle)=argmaxβ,ϕln(β,ϕ)
- 关于离散参数ϕ
由前文中关于对数似然导数的期望:E(∂∂θl(θ,ϕ))=E[(y−b′(θ))a(ϕ)]-E(∂2∂θ ∂ϕl(θ,ϕ))=a′(ϕ)E[−(y−b′(θ))a(ϕ)2]
由于E(y)=b′(θ),故此处的混合偏导为0,由样本数据中,倘若对θ有渐进无偏的估计,通过混合求导为0,可以说明由样本计算得到的^βmle,^ϕmle是渐进不相关的。对典型参数β和离散参数ϕ采取相对独立的估计方法是可行的。实际应用中参数ϕ通常采用矩估计而非最大似然估计。
此外为了设计可能存在的异方差问题,我们假定:ai(ϕ)=ϕωi故有关于ϕ的矩估计推导如下:
Var(Y)=a(ϕ)b′′(θ)=ϕb′′(θ)ωi;S2Y=1n−dn∑i=1(Yi−μi)2
^ϕ=1n−dn∑i=1ωi(Yi−μi)2b′′(θi)
其中d为参数β的维度。此外这里暗含了经典线性模型中的随机扰动项条件不相关假设,以保证样本的方差矩阵是对角阵,才可以类比我们在经典线性回归中的异方差情形。
由此我们得到用于求解最大似然估计的对数似然函数的形式:
ln(β,ϕ)=n∑i=1ωi[Yih(X′iβ)−b(h(X′β))]ϕ+∑i=1n c(Yi,ϕ)
2.2.2 迭代加权最小二乘法求解MLE
求解关于参数β的最大似然估计,等价于求解以下目标函数的最大值(即此时离散参数ϕ=1的情形):
ln(β,ϕ)=n∑i=1ωi[Yih(X′iβ)−b(h(X′β))]
首先了解一下目标函数的性质:
l′′(β)=−n∑i=1ωib′′(θ)XiX′i
目标函数关于参数β的二阶导为半负定的矩阵,即Hessian矩阵为半负定的。而此处参数β取值范围为(−∞,+∞),由凸优化理论知,对于定义在凸集(R为凸集)上的Hessian矩阵为半负定的情形下,目标函数的极大值唯一,且为全局的最大值。因此此处求解最大似然估计是一个凸优化问题。
此处求解采用牛顿法迭代求解。求解思路如下:
β(t+1)=β(t)+[l′′(β(t))]−1l′(β(t))
为了将问题转化为矩阵运算的形式,我们定义矩阵Wn×n=diag(ωi[b′′(θi)g′(μi)]−1), Gn×n=diag(g′(μ))。用矩阵形式表示l′(θ),l′′(θ)的流程如下:
为了方便后面直接使用我们给出θi(Xi)的导数形式
∂∂βθi(Xi)=h(X′iβ)′=(g ∘ b′)′(X′iβ)=Xib′′(θi(X))g′(μ(Xi))
l′(β)=n∑i=1ωi[Yi−b′(h(X′iβ))]Xib′′(θi(X))g′(μ(Xi))
由前文E(Y)=b′(θ)=μ,此处μ(Xi)=b′(h(X′iβ)),令Y=[Y1,Y2...Yn]′,μ(X)=[μ1(X1),μ2(X2)...μn(Xn)]′,Xn×d=[X1,X2...Xn]′,d为随机变Xi的维数,也是β维数。
l′(β)=n∑i=1ωi[Yi−b′(h(X′iβ))]Xib′′(θi(X))g′(μ(Xi))=X′WG(Y−μ(X))
由指数函数的性质知,E(l′(θ)2)=−E(l′′(θ)),矩阵形式下有E(l′(θ)l′(θ)T)=−E(l′′(θ))故由链式法则:
E([l′(θ(β))][l′(θ(β)]′)=E(θ′(β) l′(θ)l′(θ)T θ′(β)))=E(θ′(β) l′′(θ) θ′(β)))=−E(l′′(β))
故:
−E(l′′(β))=E(l′(β)l′(β)T)
=E(X′WG(Y−μ(X))[X′WG(Y−μ(X))]′)
=X′WG E[(Y−μ(X))2] GWX
=X′WG diag(ϕb′′(θi)ωi)GWX
由最大似然目标函数的等价形式下,离散参数ϕ=1,且参照矩阵W,G的定义,可得:
−E(l′′(β))=X′WG diag(b′′(θi)ωi)GWX=X′WW−1WX=X′WX
综上我们得到了l′(β)的形式和E(l′′(β))的形式,值得注意的是我们这里没有采用l′′(β)的具体形式,而是选取了l′′(β)的期望这一渐进的估计形式,在样本量足够大的时候,有大数律保证这种替代是有效的。因此牛顿法迭代式可以写为:
β(t+1)=β(t)+[X′WX]−1X′WG(Y−μ)
=[X′WX]−1X′W{G(Y−μ)+Xβ(t)}
2.2.3 迭代加权最小二乘法
- Step1 初始化 β(0),t=0
- Step2 对于给定的t,用β(t)替代β来计算此时的G,μ,计算z=G(Y−μ)+Xβ(t)
- Step3 对于给定的t,用β(t)替代β来计算此时的W,给更新参数
β(t+1)=[X′WX]−1X′Wz
- Step4 重复Step2,Step3直至\beta^{(t)}收敛,记此时计算得到的W为^W,参数收敛后有
^β=(X′^WX)−1X′^Wz
注意到cov(z|X)=cov(G(Y−μ)|X)=GCov(Y)G′
前文已证Cov(Y)=diag(ϕb′′(θi)ωi),故有
cov(z|X)=ϕW−1
将关于离散参数ϕ的估计值^ϕ一并带入,由^β和z的关系,此时的参数的分布我们也可以得到:
^cov(^β|X)=^ϕ(X′^WX)−1X′ ^W^W−1^W X(X′^WX)−1
=^ϕ(X′^WX)−1X′^WX(X′^WX)−1
在实际操作中,对于每一时刻的E(l′′(β))求逆会带来O(d2)的运算复杂度,因此实际计算中更常用的是梯度上升算法来计算。
2.3 广义线性模型的偏差和残差
2.3.1 广义线性模型的偏差以及偏差分析
以上我们已经给出了如何在无参数约束的条件,即β∈Rd下来估计参数β,实际应用中通常这些参数取值存在着一些限制,导致参数β的估计值无法收敛到无约束时的全局最优,出现欠拟合问题。为了诊断由参数取值的约束带来的偏差,我们在广义线性模型中引入了偏差的概念。
此处为了方便表示,我们记无约束典型参数估计值为~θ=θ(~β),有约束下的典型参数估计记作^θ=θ(^β)。下面定义偏差(Deviance) 为两类参数下对数似然之差。
D(Y;^μ)=2n∑i=1ωi{Yi(~θ−^θ)−b(~θ)+b(^θ)}
这在经典的正态线性模型下,若θ(μ)=μ,b(θ)=θ22,有:
D(Y;^μ)=n∑i=1(Yi−^Yi)2
即加权残差平方和。
换个角度看我们这里定义的偏差的概念,其实是在不同的参数空间下的似然比检验的对数结果。
LRT=supθ∈Θ1L(Y;θ)supθ∈ΘL(Y;θ)
log(LRT)=2ϕ(l(Y;~θ)−l(Y;^θ))
=2n∑i=1ωi{Yi(~θ−^θ)−b(~θ)+b(^θ)}=D(Y;^μ)
当比较两个不同大小(参数个数不同)的模型时,即^θ1∈Θ1,^θ2∈Θq,两个参数空间的维度不同,在似然比检验的角度下:
D(Y;^μ,θ1)−D(Y;^μ,θ2)=2ϕ{supθ∈Θ1l(θ)−supθ∈Θ2l(θ)}=2ϕlog(LRT)
由似然比检验的渐进性质可知,ϕD(Y;^μ)→χ2df,即服从参数维度为df=dim(Θ1)−dim(Θ0)的χ2分布.由此我们可以检验两个不同大小的模型的拟合能力。
2.3.2 广义线性模型的残差定义
2.4 广义线性模型的例子
2.4.1 logistic回归
2.4.2 Possion回归
3、广义线性模型的稀疏解
3.1 高置信区间的稀疏解
3.2 采用惩罚似然的特征选择




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?