Bash : IO 重定向
标准输入/输出(standard I/O)可能是软件设计原则里最重要的概念了。这个概念就是:程序应该有数据的来源端、数据的目的端(输出结果的地方)已经报告问题的地方,它们分别被称为标准输入(standard input)、标准输出(standard output)以及标准错误输出(standard error)。程序不必知道也不用关心它的输入与输出背后是什么设备,当程序运行时,这些标准 IO 就已经打开并准备就绪了。
运行时的程序称为进程,在 Linux 系统中,对于每个进程来说,始终有 3 个"文件"处于打开状态:
- stdin
- stdout
- stderr
这三个文件就是进程默认的标准输入、标准输出和标准错误输出。每个打开的文件都会被分配一个文件描述符。stdin,stdout 和 stderr 的文件描述符分别是 0,1 和 2(一个文件描述符说白了就是文件系统为了跟踪这个打开的文件而分配给它的一个数字)。对于 Bash 进程来说,stdin 默认就是键盘,stdout 和 stderr 默认都是屏幕。
我们可以把 IO 重定向简单理解为:
系统捕捉一个文件、命令、程序或脚本的输出,然后将这些输出作为输入发送到另一个文件、命令、程序或脚本中。
IO 重定向的基本概念
把标准输出重定向到文件
> 和 >> 符号把标准输出重定向到文件中
> 会覆盖掉已经存在的文件中的内容
>> 则把新的内容追加到已经存在的文件中的内容的尾部
比如下面的命令将会把文件 log.txt 变为一个空文件(就是 size 为 0):
$ : > log.txt
下面的命令则把 ls 命令输出的结果追加到 log.txt 文件的尾部:
$ ls >> log.txt
其实这是省略了标准输出的文件描述符 1 的写法,完整的写法为:
$ ls 1> log.txt
把标准错误输出重定向到文件
标准错误的文件描述符为 2,所以重定向标准错误到文件的写法为:
$ ls 2> error.txt
如果想同时把标准输出和标准错误输出重定向到同一个文件中,可以使用下面的方法:
$ ls &> log.txt
还有另外一种写法为:
$ ls >log.txt 2>&1
重定向到另一个文件描述符
比如通过这种方式把标准输出和标准错误输出重定向到同一个文件中:
$ ls >log.txt 2>&1
注意:& 符号后面跟的是文件描述符而不是文件。
总结一下,我们大概可以得到下面两条规则:
M>N
# "M" 是一个文件描述符,如果没有明确指定的话默认为 1。
# "N" 是一个文件名。
# 文件描述符 "M" 被重定向到文件 "N"。
M>&N
# "M" 是一个文件描述符,如果没有明确指定的话默认为 1。
# "N" 是另一个文件描述符。
关闭文件描述符
文件描述符是可以关闭的,典型的写法有下面几种:
n<&- # 关闭输入文件描述符 n
0<&-, <&- # 关闭 stdin
n>&- # 关闭输出文件描述符 n
1>&-, >&- # 关闭 stdout
>/dev/null 2>&1 和 2>&1 >/dev/null
Linux 系统中有一个特殊的设备文件 /dev/null,发送给它的任何内容都会被丢弃,因此如果需要丢弃标准输出和标准错误输出的内容时可以使用下面的方法:
1>/dev/null 2>/dev/null
下面的写法与上面的写法是等同的,接下来我们重点来解释下面的写法:
>/dev/null 2>&1
>/dev/null
>/dev/null 的作用是将标准输出 1 重定向到 /dev/null 中,因此标准输出中的内容被完全丢弃了。
2>&1
2>&1 用到了重定向绑定,采用 & 可以将两个输出绑定在一起,也就是说错误输出将会和标准输出输出到同一个地方。
其实 Linux 在执行 shell 命令之前,就会确定好所有的输入输出位置,解释顺序为从左到右依次执行重定向操作。所以 >/dev/null 2>&1 的作用就是让标准输出重定向到 /dev/null 中,接下来因为错误输出的文件描述符 2 被重定向绑定到了标准输出的描述符 1,所以错误输出也被定向到了 /dev/null 中,错误输出同样也被丢弃了。
2>&1 >/dev/null
2>&1 >/dev/null 执行的结果和 >/dev/null 2>&1 是不一样的!它的执行过程为:
- 2>&1,将错误输出绑定到标准输出上。由于此时的标准输出是默认值,也就是输出到屏幕,所以错误输出会输出到屏幕。
- >/dev/null,将标准输出1重定向到 /dev/null 中。
exec 与重定向
exec <filename 命令会将 stdin 重定向到文件中。 从这句开始, 所有的 stdin 就都来自于这个文件了, 而不是标准输入(通常都是键盘输入)。 这样就提供了一种按行读取文件的方法。当然,也可以用这种方法来重定向标准输出和标准错误输出。下面的 upper.sh 程序把输入文件中的字母转换为大写并输出到另外一个文件中,脚本中使用 exec 同时重定向了 stdin 和 stdout:
#!/bin/bash E_FILE_ACCESS=70 E_WRONG_ARGS=71 if [ ! -r "$1" ] # 判断指定的输入文件是否可读 then echo "Can't read from input file!" echo "Usage: $0 input-file output-file" exit $E_FILE_ACCESS fi # 即使输入文件($1)没被指定 if [ -z "$2" ] then echo "Need to specify output file." echo "Usage: $0 input-file output-file" exit $E_WRONG_ARGS fi exec 4<&0 # 保存默认 stdin exec < $1 # 将会从输入文件中读取. exec 7>&1 # 保存默认 stdout exec > $2 # 将写到输出文件中. # 假设输出文件是可写的 # ----------------------------------------------- cat - | tr a-z A-Z # 转换为大写 # 从 stdin 中读取 # 写到 stdout 上 # 然而,stdin 和 stdout 都被重定向了 # ----------------------------------------------- exec 1>&7 7>&- # 恢复 stout exec 0<&4 4<&- # 恢复 stdin # 恢复之后,下边这行代码将会如预期的一样打印到 stdout 上 echo "File \"$1\" written to \"$2\" as uppercase conversion." exit 0
在 upper.sh 程序所在的目录下创建 in.txt 和 out.txt 文件,编辑 in.txt 文件的内容为:
abcd
xxyy
然后运行 upper.sh 程序:
$ ./upper.sh in.txt out.txt

其实还有一种稍微简单一些的方式把标准输入和标准输出重定向到文件:
[j]<>myfile
# 为了读写 myfile,把文件 myfile 打开, 并且将文件描述符 j 分配给它。
# 如果文件 myfile 不存在, 那么就创建它。
# 如果文件描述符 j 没指定,那默认是 fd 0,即标准输入。
这种应用通常是为了把内容写到一个文件中指定的地方,比如下面的 demo:
echo 1234567890 > myfile # 写字符串到 myfile exec 6<> myfile # 打开 myfile 并且将 fd 6 分配给它 read -n 4 <&6 # 只读取4个字符 echo -n . >&6 # 写一个小数点 exec 6>&- # 关闭 fd 6 cat myfile # ==> 1234.67890
避免子 shell
默认情况下,不能在子 shell 中改变父 shell 中变量的值。下面的 demo 通过 exec 重定向 IO 有效的规避了子 shell 问题:
#!/bin/bash E_WRONG_ARGS=71 if [ -z "$1" ] then echo "Usage: $0 input-file" exit $E_WRONG_ARGS fi Lines=0 cat "$1" | while read line; # 管道会产生子 shell do { echo $line (( Lines++ )); # 增加这个变量的值 # 但是外部循环却不能访问 } done echo "Number of lines read = $Lines" # 0 # 错误! echo "------------------------" exec 3<> "$1" while read line <&3 do { echo "$line" (( Lines++ )); # 增加这个变量的值 # 现在外部循环就可以访问了 # 没有子shell, 现在就没问题了 } done exec 3>&- echo "Number of lines read = $Lines" exit 0
把上面的代码保存到 avoid-subshell.sh 文件中,然后运行下面的命令:
$ ./avoid-subshell.sh in.txt
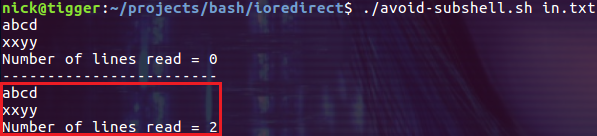
使用重定向 IO 的方式获得了正确的结果。
代码块重定向
像 while、until、for 和 if/then 等代码块也是可以进行 IO 重定向的,下面的 demo 把 while 循环的标准输入重定向到一个文件:
#!/bin/bash E_WRONG_ARGS=71 if [ -z "$1" ] then echo "Usage: $0 input-file" exit $E_WRONG_ARGS fi count=0 while [ "$name" != xxyy ] do read name if [ -z "$name" ]; then break fi echo $name let "count += 1" done <"$1" echo "$count names read" exit 0
把上面的代码保存到文件 whileblock.sh 中,然后执行下面的命令,可以看到标准输入重定向后的结果:
$ ./whileblock.sh in.txt

下面的 demo 则同时重定向了 for 循环的标准输入和标准输出:
#!/bin/bash E_WRONG_ARGS=71 if [ -z "$1" ] then echo "Usage: $0 input-file output-file" exit $E_WRONG_ARGS fi if [ -z "$2" ] then echo "Usage: $0 input-file output-file" exit $E_WRONG_ARGS fi FinalName="xxyy" line_count=$(wc "$1" | awk '{ print $1 }') for name in $(seq $line_count) do read name echo "$name" if [ "$name" = "$FinalName" ] then break fi done < "$1" > "$2" exit 0
把上面的代码保存到文件 forblock.sh 中,然后执行下面的命令,终端上没有任何输出,因为输出都被重定向到了 out.txt 文件:
$ ./forblock.sh in.txt out.txt
总结
在众多的场景中,IO 重定向的结果是显而易见的。但在一些特殊的用例中结果就不是那么明显了,需要我们理解重定向的基本规则,才能理解哪些特殊写法的含义或是写出我们自己满意的脚本。
参考:
《高级 Bash 脚本编程》
shell 中的>/dev/null 2>&1 是什么鬼?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号