
Scala和Java二种方式实战Spark Streaming开发
一、Java方式开发
1、开发前准备:假定您以搭建好了Spark集群。
2、开发环境采用eclipse maven工程,需要添加Spark Streaming依赖。

3、Spark streaming 基于Spark Core进行计算,需要注意事项:
设置本地master,如果指定local的话,必须配置至少二条线程,也可通过sparkconf来设置,因为Spark Streaming应用程序在运行的时候,至少有一条线程用于不断的循环接收数据,并且至少有一条线程用于处理接收的数据(否则的话无法有线程用于处理数据),随着时间的推移,内存和磁盘都会不堪重负)。
温馨提示:
对于集群而言,每隔exccutor一般肯定不只一个Thread,那对于处理Spark Streaming应用程序而言,每个executor一般分配多少core比较合适?根据我们过去的经验,5个左右的core是最佳的(段子:分配为奇数个core的表现最佳,例如:分配3个、5个、7个core等)
接下来,让我们开始动手写写Java代码吧!
第一步:创建SparkConf对象

第二步:创建SparkStreamingContext
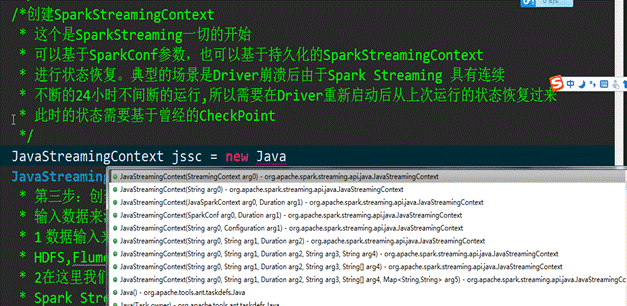
我们采用基于配置文件的方式创建SparkStreamingContext对象:


第三步,创建Spark Streaming输入数据来源:
我们将数据来源配置为本地端口9999(注意端口要求没有被占用):

第四步:我们就像对RDD编程一样,基于DStream进行编程,原因是DStream是RDD产生的模板,在Spark Streaming发生计算前,其实质是把每个Batch的DStream的操作翻译成为了RDD操作。
1、flatMap操作:

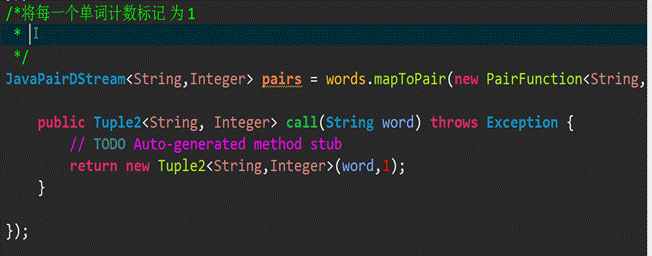
2、 mapToPair操作:
3、reduceByKey操作:

4、print等操作:

温馨提示:
除了print()方法将处理后的数据输出之外,还有其他的方法也非常重要,在开发中需要重点掌握,比如SaveAsTextFile,SaveAsHadoopFile等,最为重要的是foreachRDD方法,这个方法可以将数据写入Redis,DB,DashBoard等,甚至可以随意的定义数据放在哪里,功能非常强大。
一、Scala方式开发
第一步,接收数据源:
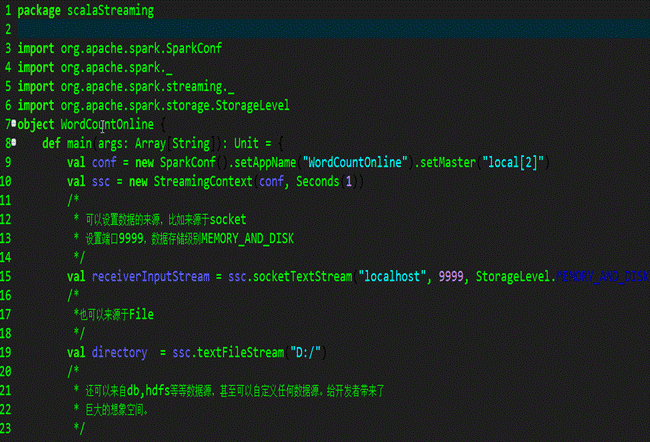
第二步,flatMap操作:

第三步,map操作:

第四步,reduce操作:

第五步,print()等操作:

第六步:awaitTermination操作

总结:
备注:83课
更多私密内容,请关注微信公众号:DT_Spark

 浙公网安备 33010602011771号
浙公网安备 33010602011771号