大数据文件存储格式与压缩格式
数据仓库能支持多种文件格式,如hive可以支持textfile,RCFile,SequenceFile,ORC,Parquet格式等,我们使用最多的是textfile,SequenceFile,ORC以及parquet格式。
- TextFile
TextFile的特点就是行存储,是hive默认存储格式,可以使用任意分隔符,格式本身不支持压缩,不支持切割,但可以结合Vzip2和lzo等使用,这样就可以切割了 - SequenceFile
SequenceFile是一种二进制存储结构,可压缩,可切分,直接将<Key,Value>键值对序列化到文件中,所以适合处理小文件,将小文件合并成一个大的SequenceFile文件
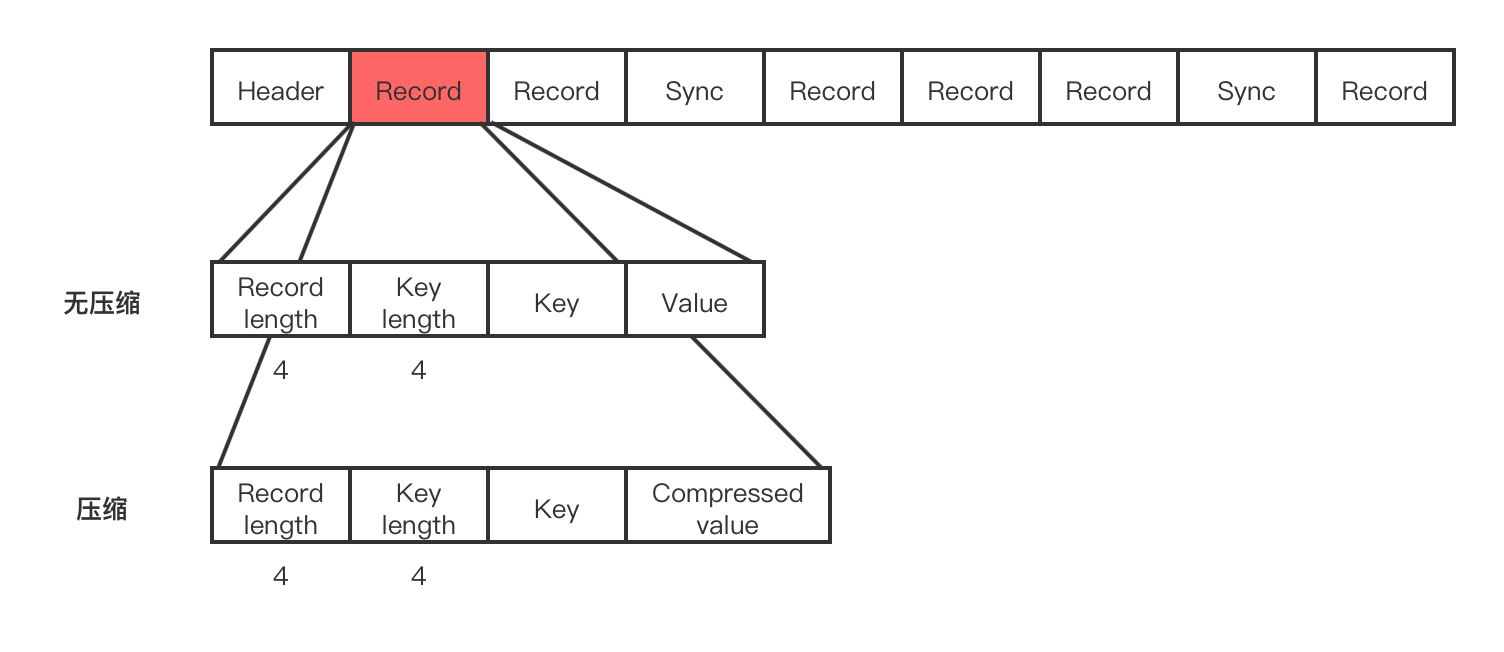
上图可以看出,SequenceFile由header和Record组成,提供两种压缩方式,一种是基于Record的压缩,另一种是Block压缩
SequeceFile存储时会存储一些额外信息,所以一般不作为存储格式的选择
SequeceFile格式支持切分,所以不用考虑压缩格式是否支持压缩,更关注压缩效果,压缩/解压速度 - RCFile
数据按行分组,每组按列存储,整合了行存储和列存储的优点,属于列式存储
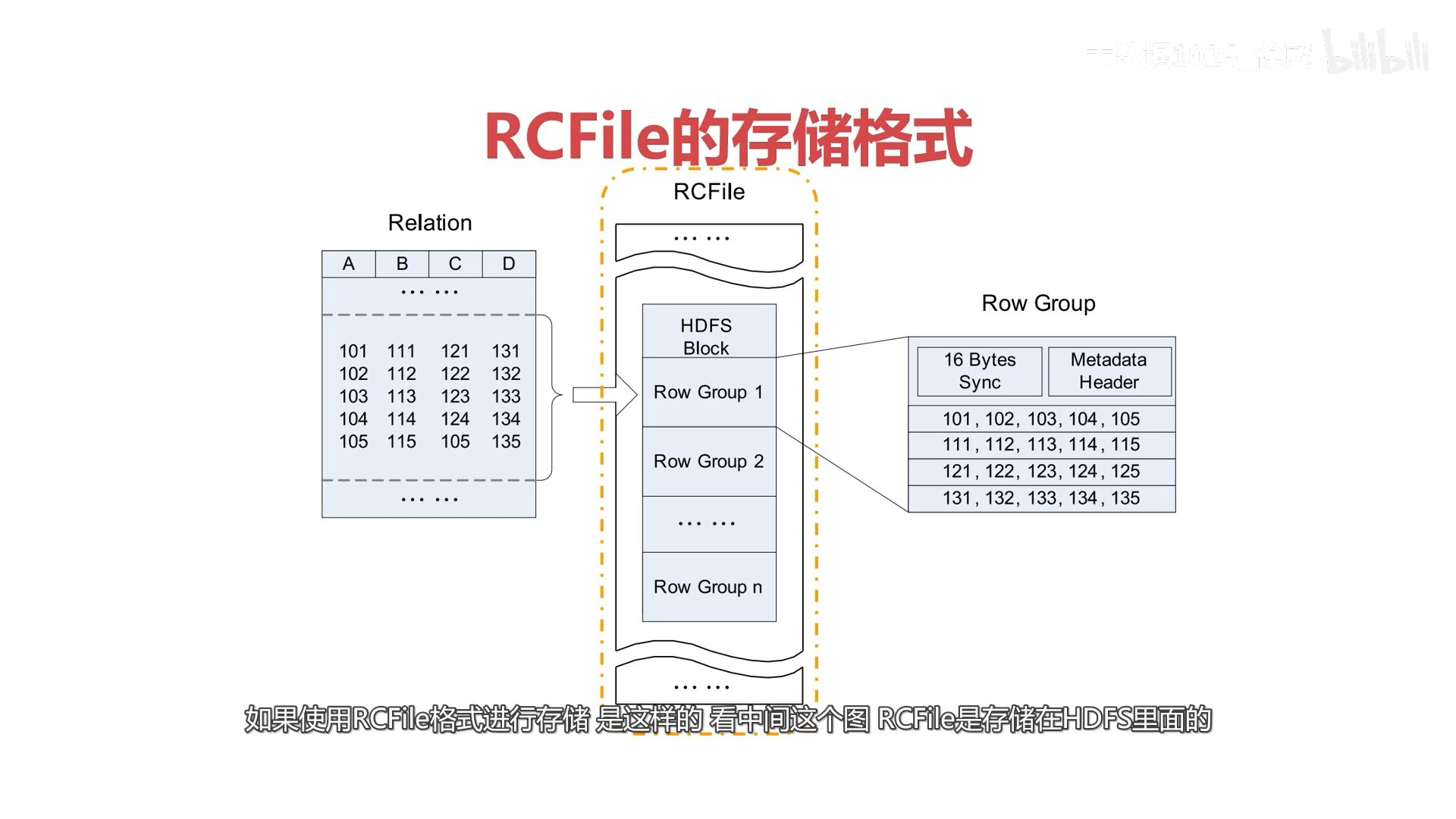
RCFile本身支持压缩,切分,因此选择压缩格式的时候更关注压缩/解压速度,压缩比 - ORC
优化后的RCFile
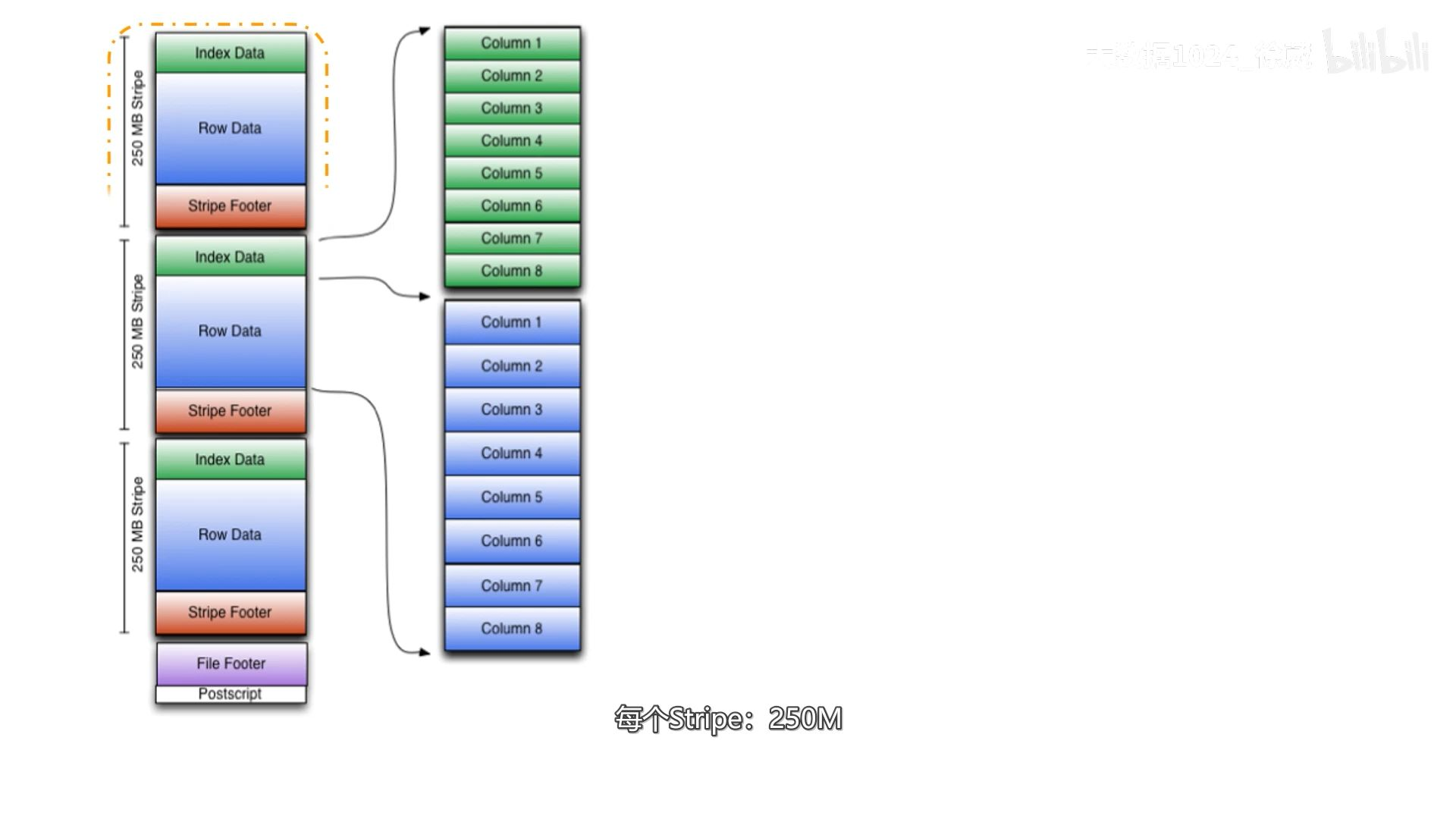
在RCFile行组的基础上增加了index data和stripe footer组成了stripe的颗粒度
此外,使用ORC格式,hive中不能直接使用set设置压缩等参数,要使用tblproperties关键字,即
点击查看代码
create table t1(
id int,
name string,
)stored as orc tblproperties("orc.compress"="LZO","其他”)
在ORC文件中保存了三种颗粒层次的统计信息,分别是文件级别(上图最底下的File Footer)这个层次级别主要是考虑到需要整个文件列统计信息查询的场景,比如max,min,sum这种需要整个文件数据的聚合操作,stripe级别,stripe级别保留的行级别的统计信息,用于根据where条件读取记录(orc格式文件读取时以行组为单位进行读取),row group级别,行组级别根据index data来过滤掉不必要的数据(也就是读取感兴趣的列)
- Parquet
Parquet也是列式存储,也是适合大数据场景下的OLAP
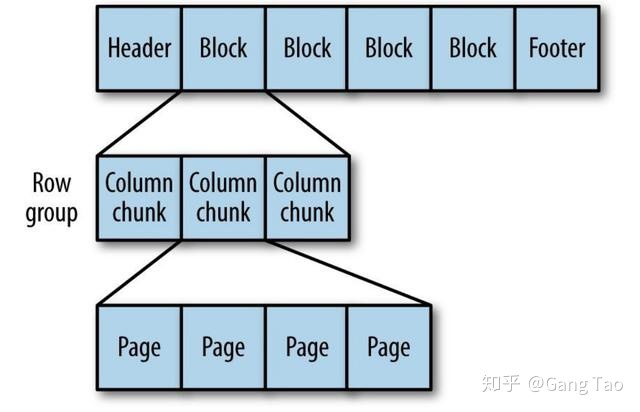
Parquet格式由一个个行组构成,一个行组可以由多个列块组成(每一列都是一个列块),每个列快由可以分为不同的页,我们只需要读取自己感兴趣的页就可以,这也是与ORC不同的地方,在列的颗粒度下还细分了页的颗粒度,这也是Parquet支持读取嵌套结构的原因。
此外还有一些其他的存储格式,如Avro,Arrow,CarbonData等
压缩格式

在MR过程中一般有两个地方需要压缩
其一,在Map输出阶段,这个阶段需要执行map逻辑,需要消耗cpu,而压缩本身也需要一定的cpu,压缩比越高需要更多cpu时间,那么这个阶段尽可能使用一些压缩.解压比较快的压缩格式,采用速度快的lzo,snappy比较合适
其二,在reduce输出阶段,这里要考虑不同的场景,如果reduce后是另一个map,那么这个阶段主要考虑是否可以切分(Bzip2,lzo可以切分),另一个场景是reduce后永久保留在数仓中,那么更关注压缩效果好不好。
压缩格式和存储格式在数仓中的选择
在实际工作中,不仅结合存储格式和压缩格式的组合以及实际场景所关注的侧重点,还要考虑到未来技术框架扩展的兼容度,是否支持多种计算引擎
数仓选择需要根据业务实际考虑,没有统一的答案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号