全局唯一ID的实现方案
为什么需要保证唯一ID?
在单机服务架构中,数据库的每一个业务表的主键ID都是允许自增的,但是在分布式服务架构的分库分表的设计,使得多个库或者多个表存储了相同的业务表,如果没有一个全局的唯一ID设计方案,可能就导致了不同表(但业务逻辑是相同的)的ID相撞了。
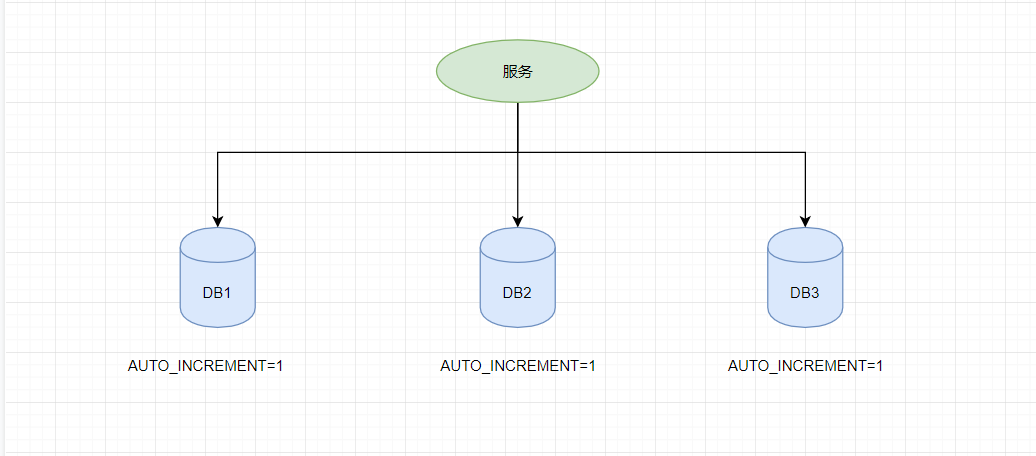
虽然在不同数据库中,但是在用户层是无感知的,都是当做相同的业务表来看。
常见的方案
UUID
UUID是由一组32位16进制数字构成,UUID在java中有五套实现方案,第一是基于时间的UUID,第二是基于名字和MD5算法的UUID,第三是基于名字和SHA1算法的UUID,第四是Distributed Computing Environment(DCE)安全的UUID,第五是基于随机的UUID,这是java中默认的
UUID的缺点就是UUID太长了,不容易存储,以及UUID是无序的,不能比较,不利于innodb的索引,因为UUID无序容易造成记录顺序经常变更。
数据库生成
不依赖外界,由数据库自己生产相应的id,比如分库数据库,我们把每张表的起始id设计成不一样的,然后有相同的步长,这样就不会有冲突了了
缺点就是对数据库强依赖
基于Redis生成
略
雪花算法
雪花算法是由推特提出的,将64位(1+41+10+12)数(java中就是long类型)分割成不同含义,然后根据时间戳生成不同的id
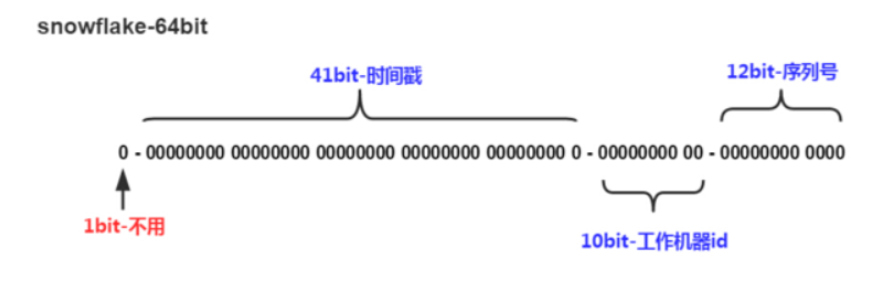
定义各个部分的id以及shift大小
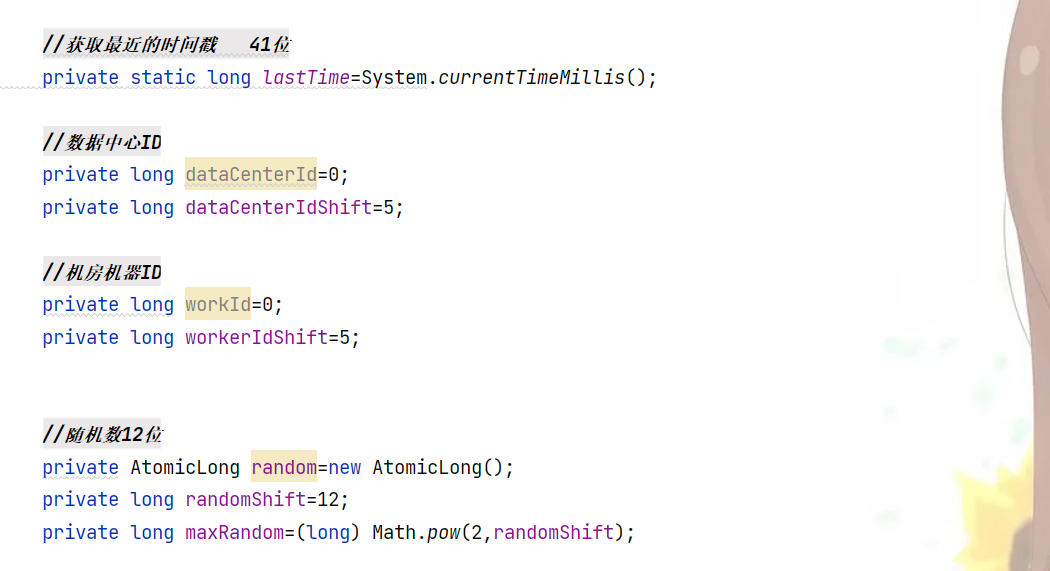
其中,workid和datacenterid可以自定义shift大小,默认是5语
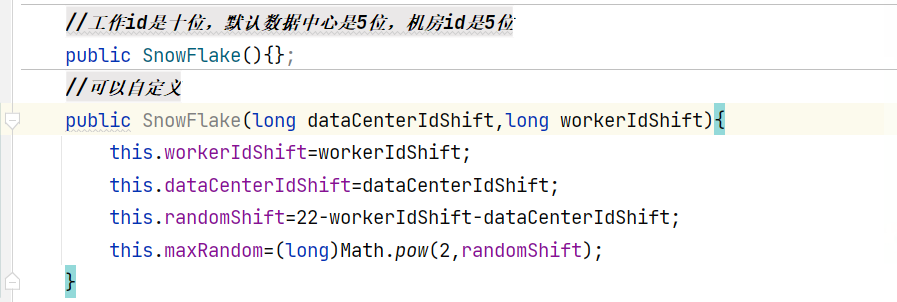
生成id就是将各个部分 或操作

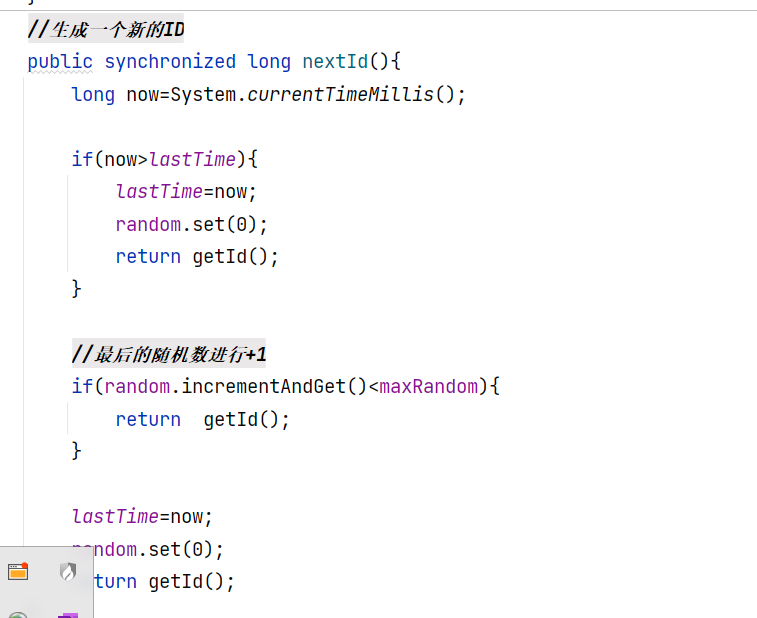
雪花算法要了解基本过程,有很多大厂的分布式唯一id方案是基于雪花算法改良的。其余的分布式唯一id之后再学习记录。
