JVM内存结构与内存模型
这篇文章重点讲一下jvm的内存结构和内存模型的知识点。(2023.3.11)
1、内存结构
jvm内存区域主要分为线程私有区域【程序计数器,虚拟机栈,本地方法栈】,线程共享区域【堆,方法区】,直接内存,其中线程私有区域和线程共享区域又统称为运行时数据区
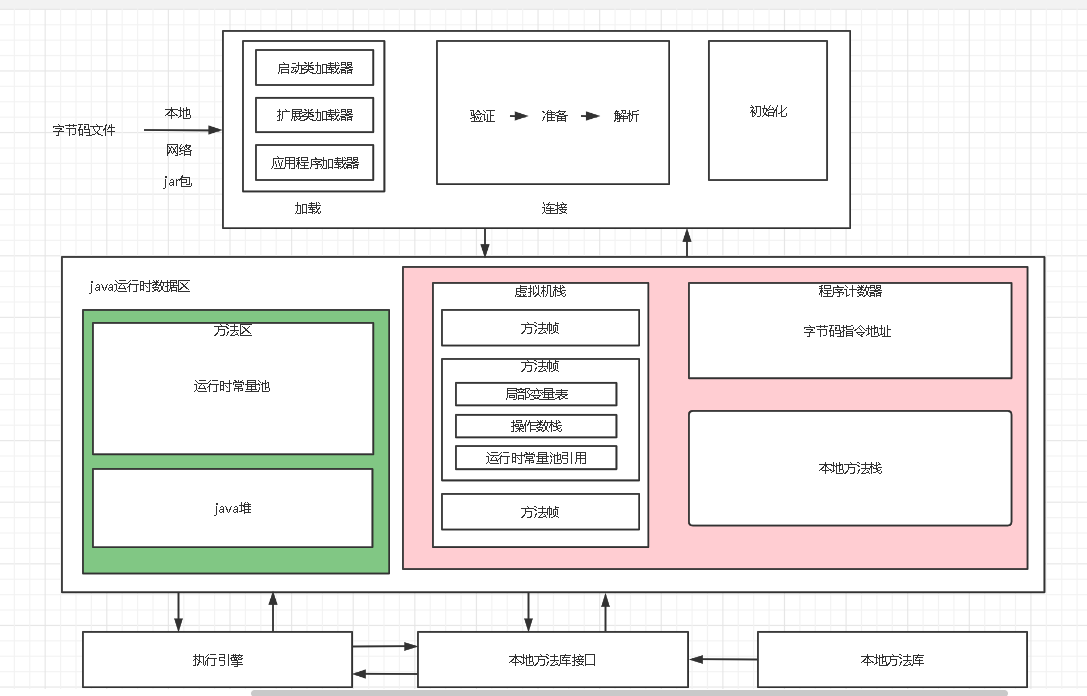
- 程序计数器并不是物理存储器,而是jvm对物理pc计数器的模拟,是一块较小的内存,可以看作是字节码文件的行号指示器,指针指的就是当前字节码执行的指令地址,这个区域是整个jvm内存区域中唯一的没有OOM的
- 虚拟机栈,里面存储的是栈帧,遇到调动方法帧,则压入栈,调用完了则出栈,此外这块区域不存在垃圾回收问题,而且这个区域大小可固定也可以动态,如果是固定虚拟机栈,可能存在方法帧无法压入栈的情况,发生StackOverflow异常,如果是动态虚拟机栈,则新线程没有足够内存创建这块区域,发生OOM异常,而且也要关注下栈帧的结构
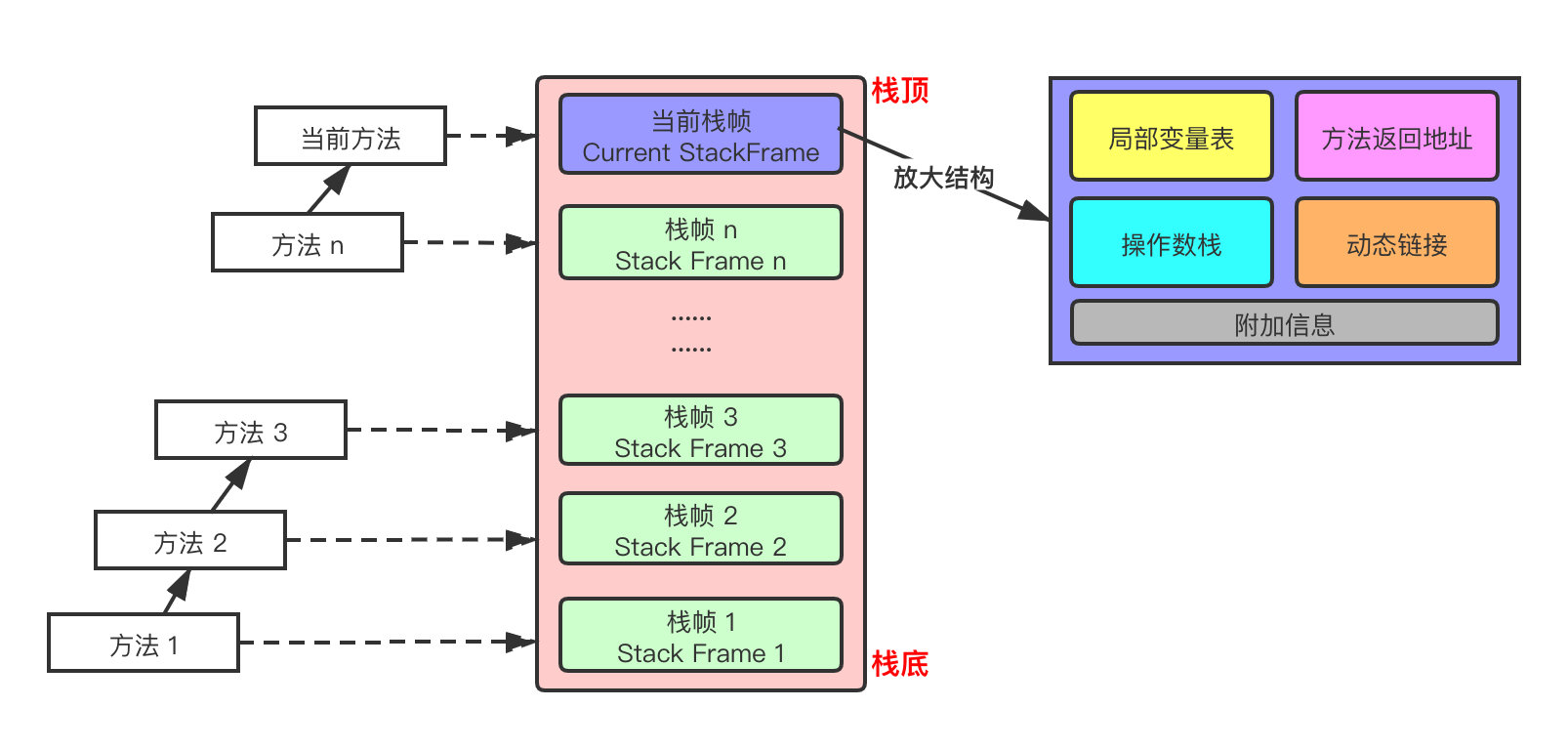
操作数栈存放的是计算过程中的临时变量或者中间结果
动态连接就是对运行常量池的引用,类加载机制过程中解析那一步的作用是将常量池中的符号引用替换成直接引用,这叫静态链接,而这里的动态连接的意思是在运行过程中转换成直接引用。 - 本地方法栈,顾名思义,调用本地方法时使用的栈,所谓本地方法就是java程序使用非java语言编写的接口
----在有一些JVM并不支持本地方法栈,Hotspot jvm更是将虚拟机栈和本地方法栈合并
宏观来看,两者都是栈,是程序运行时的数据结构,帮助程序执行,处理数据,而堆是存储数据结构,解决数据存储问题 - java堆
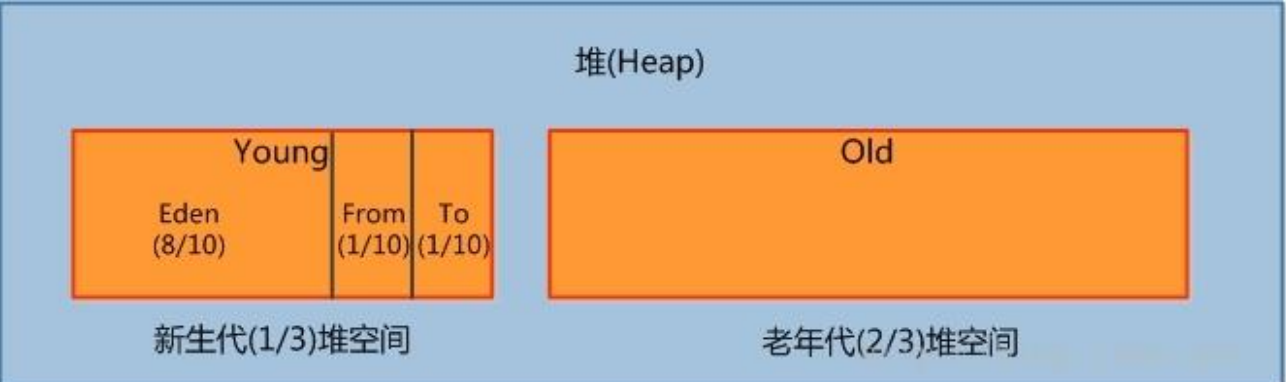
java堆分成了两个部分,分为新生代和老年代,新生代有分为Eden区,servivorFrom区,servivorTo区
新生代占java堆三分之一大小,存放新对象(不过如果新对象无法在新生代存放,则放入老年代),由于新对象频繁创建销毁,所以在新生代经常发生MinorGC。
Eden区是新对象的出生地,如果Eden区内存不够,则触发MinorGC,From,To区域又叫幸存者区,多次GC后还幸存者就会转换到老年代。
MinorGC的过程主要可以概括成 “复制”-->“清空”-->“交换”,“复制”指得是每一次GC后,把Eden和From区域的存活的对象复制到To区域,年龄+1,如果年龄过大则会放入老年代内存中,然后清空Eden和From区域,最后From和To区域身份互换
而老年代存放的是年龄大的对象和大对象,采用的MajorGC,MajorGC主要分为两步“扫描”-->“清除”,所以又叫标记清除算法,先扫描整个老年代,标记可以存活的对象,将没有标记的对象清除 - 方法区
方法区在JAVA7及之前由JVM 堆中永久带实现,JDK8之后永久代取消了,这不是说没有了方法区(注意这只是JVM的内存结构,不同的JVM有不同的实现),此外编译后和解析后又不一样,总得来说分成了一个作用,就是存放加载后字节码文件内容的,两个部分,第一个是存放类的基本信息,比如版本,接口,字段等,第二个就是运行时常量池,存放的是字节码文件中常量池中书面量和符号引用。
2.GC
请参考GC详解
在讲GC算法之前,要了解如何判断为垃圾
有两种方法,一是计数引用,顾名思义,对象如果没有任何与之关
联的引用,即他们的引用计数都不为 0,则说明对象不太可能再被用到,那么这个对象就是可回收对象。但存在bug就是循环引用(类似死锁)的问题,所以第二种方法就是可达性分析,从GC root到对象没有一个可以到达的路径,存是不可达对象,两次标记为不可打对象则转换为可回收的垃圾。GCRoot指得是的当前活跃的栈帧中指向堆对象的引用
GC方法可以分为MinorGC(复制-->清除-->交换),MajorGc(扫描标记-->清除),Full GC
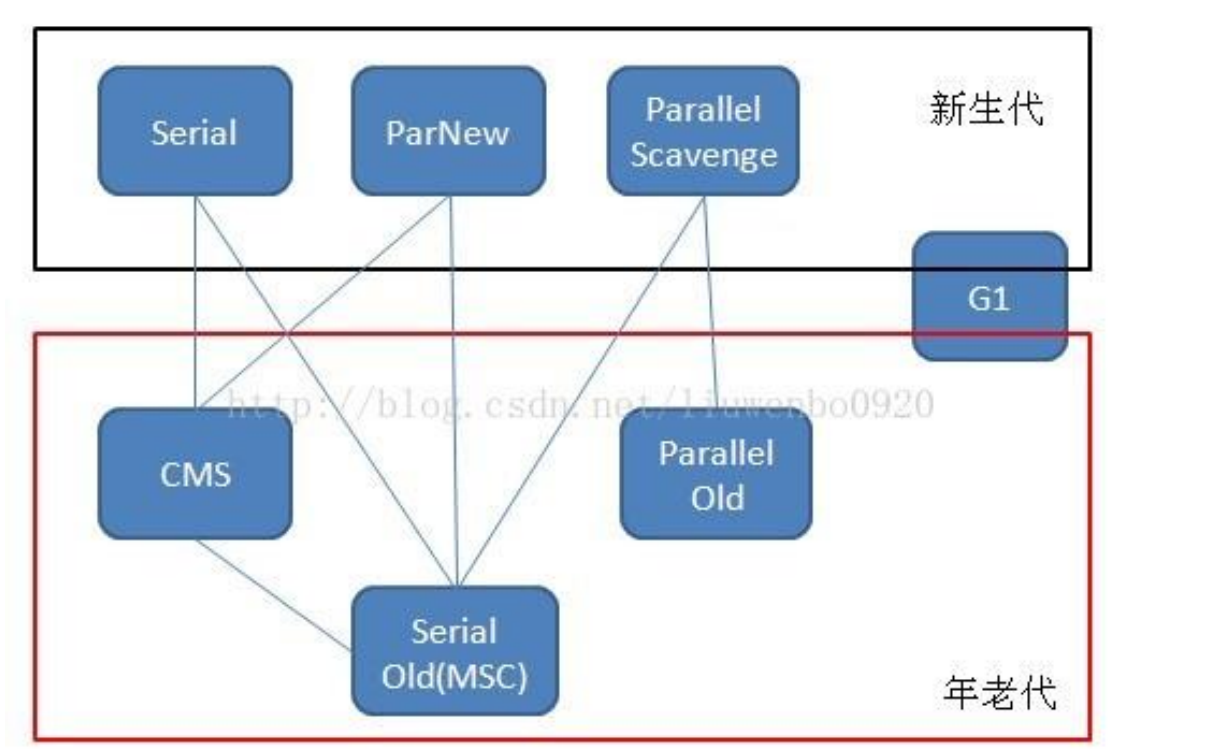
* 垃圾收集器
新生代垃圾收集器有Serial,ParNew,Parallel Scavenge
1.Serial的特点是单线程,使用复制算法,启动Serial垃圾收集器要停止其他的用户工作线程,优点就是没有线程交互,效率高,是JVM客户端默认的收集器
2.ParNew就是Serial+多线程,也要暂停所有用户线程,是JVM服务端默认的收集器
3.Parallel Scavenge也是多线程,使用复制算法,也要暂停所有用户线程,这个收集器更关注的是吞吐量指标,吞吐量就是运行用户代码时间/(运行用户代码时间+垃圾收集时间)),所以它也采用了一个自适应调节策略,这也是与ParNEW最大的区别
老年代垃圾收集器有Serial Old,Parallel Old,CMS
Serial Old是老年代的Serial,不同的是采用的是标记整理算法,Parallel Old是Parallel Scavenge老年版,采用的是标记整理算法,重点理解一下CMS
CMS(Concurrent Mark Sweep),使用的是标记清除算法,他分为四个阶段,初始标记阶段,并发标记阶段,重新标记阶段,并发清除四个阶段,并发标记和并发清除是垃圾回收线程和用户线程一起工作,占用大部分时间,所以CMS整体来看是与用户线程并发执行的
除次之外,还有个G1收集器,它的特点是可以同时作用于新生代和老年代,采用的分区划分,把整个堆内存分成几块,同时追踪,优先清除垃圾较多的区域,使用的标记整理算法,避免造成内存碎片,G1回收器避免了全区域垃圾收集,同时也避免了内存碎片
3.JVM内存模型(JMM)
在学习JMM之前,要对堆、栈的概念十分清楚,可以试着回答下堆、栈分别存储什么,从JVM角度回答堆、栈的区别。我的理解是从存储内容角度上看,堆存储实例对象,而栈存储基本数据类型以及堆上对象的引用,从功能上看,堆主要负责存储数据,栈是处理数据,因为栈的单元是方法帧,有出栈,入栈的动作,此外,jvm角度,堆是线程共享的而栈是线程私有的。
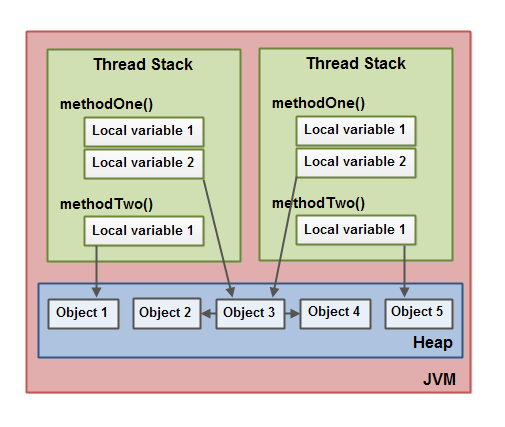
上图有两个线程栈,代码是一样的,都是调用methodOne,methodOne再调用methodTwo,
但不同局部变量的引用是不一样的,首先看,methodOne的local variable 1没有堆中对象的引用,所以是基本类型变量,local variable 2指向了堆上同一个实例对象,这是个静态变量,同时这个静态变量Object 3也有两个引用Object2和Object4,这应该是Object3对象中有两个实例对象,不同线程的methodTwo的local variable 1对应着不同的Object的引用,所以这应该是一个普通实例对象,不同线程不同引用。
但无论是堆还是栈,都是存储在主存储器上的(也有可能存储在寄存器缓存以及CPU高速缓存中),所以要保证共享对象的修改是对所有线程是可见的,这里就涉及到并发关键字volatile,还有就是多个线程操作共享变量的竞态问题,这就涉及到了并发关键字synchronize,总之JMM的诞生是为了解决共享变量操作问题。JMM抽象了线程与主内存的关系,共享变量存储在主内存中,线程有一块工作内存存储共享变量的副本。
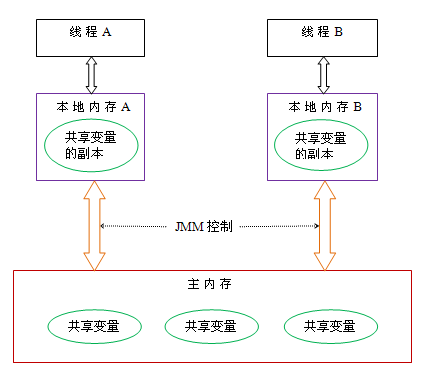
更详细的JMM请参考我的另一篇博客(https://www.cnblogs.com/spark-cc/p/17100278.html)
本人菜鸡,哪里写的有问题欢迎指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号