深度优先搜索— —提高Ⅰ
DFS连通性模型
1. 算法分析
使用dfs来判断是否两个点连通,也可以通过dfs来做计数
2.例题
一天Extense在森林里探险的时候不小心走入了一个迷宫,迷宫可以看成是由 n∗n 的格点组成,每个格点只有2种状态,.和#,前者表示可以通行后者表示不能通行。
同时当Extense处在某个格点时,他只能移动到东南西北(或者说上下左右)四个方向之一的相邻格点上,Extense想要从点A走到点B,问在不走出迷宫的情况下能不能办到。
如果起点或者终点有一个不能通行(为#),则看成无法办到。
注意:A、B不一定是两个不同的点。
输入格式
第1行是测试数据的组数 k,后面跟着 k 组输入。
每组测试数据的第1行是一个正整数 n,表示迷宫的规模是 n∗n 的。
接下来是一个 n∗n 的矩阵,矩阵中的元素为.或者#。
再接下来一行是 4 个整数 ha,la,hb,lb,描述 A 处在第 ha 行, 第 la 列,B 处在第 hb 行, 第 lb 列。
注意到 ha,la,hb,lb 全部是从 0 开始计数的。
输出格式
k行,每行输出对应一个输入。
能办到则输出“YES”,否则输出“NO”。
数据范围
1≤n≤100
输入样例:
2
3
.##
..#
#..
0 0 2 2
5
.....
###.#
..#..
###..
...#.
0 0 4 0
输出样例:
YES
NO
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 110;
int n;
char g[N][N];
int xa, ya, xb, yb;
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
bool st[N][N];
bool dfs(int x, int y)
{
if (g[x][y] == '#') return false;
if (x == xb && y == yb) return true;
st[x][y] = true;
for (int i = 0; i < 4; i ++ )
{
int a = x + dx[i], b = y + dy[i];
if (a < 0 || a >= n || b < 0 || b >= n) continue;
if (st[a][b]) continue;
if (dfs(a, b)) return true;
}
return false;
}
int main()
{
int T;
scanf("%d", &T);
while (T -- )
{
scanf("%d", &n);
for (int i = 0; i < n; i ++ ) scanf("%s", g[i]);
scanf("%d%d%d%d", &xa, &ya, &xb, &yb);
memset(st, 0, sizeof st);
if (dfs(xa, ya)) puts("YES");
else puts("NO");
}
return 0;
}
有一间长方形的房子,地上铺了红色、黑色两种颜色的正方形瓷砖。
你站在其中一块黑色的瓷砖上,只能向相邻(上下左右四个方向)的黑色瓷砖移动。
请写一个程序,计算你总共能够到达多少块黑色的瓷砖。
输入格式
输入包括多个数据集合。
每个数据集合的第一行是两个整数 W 和 H,分别表示 x 方向和 y 方向瓷砖的数量。
在接下来的 H 行中,每行包括 W 个字符。每个字符表示一块瓷砖的颜色,规则如下
1)‘.’:黑色的瓷砖;
2)‘#’:红色的瓷砖;
3)‘@’:黑色的瓷砖,并且你站在这块瓷砖上。该字符在每个数据集合中唯一出现一次。
当在一行中读入的是两个零时,表示输入结束。
输出格式
对每个数据集合,分别输出一行,显示你从初始位置出发能到达的瓷砖数(记数时包括初始位置的瓷砖)。
数据范围
1≤W,H≤20
输入样例:
6 9
....#.
.....#
......
......
......
......
......
#@...#
.#..#.
0 0
输出样例:
45
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 25;
int n, m;
char g[N][N];
bool st[N][N];
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
int dfs(int x, int y)
{
int cnt = 1;
st[x][y] = true;
for (int i = 0; i < 4; i ++ )
{
int a = x + dx[i], b = y + dy[i];
if (a < 0 || a >= n || b < 0 || b >= m) continue;
if (g[a][b] != '.') continue;
if (st[a][b]) continue;
cnt += dfs(a, b);
}
return cnt;
}
int main()
{
while (cin >> m >> n, n || m)
{
for (int i = 0; i < n; i ++ ) cin >> g[i];
int x, y;
for (int i = 0; i < n; i ++ )
for (int j = 0; j < m; j ++ )
if (g[i][j] == '@')
{
x = i;
y = j;
}
memset(st, 0, sizeof st);
cout << dfs(x, y) << endl;
}
return 0;
}
DFS搜索顺序
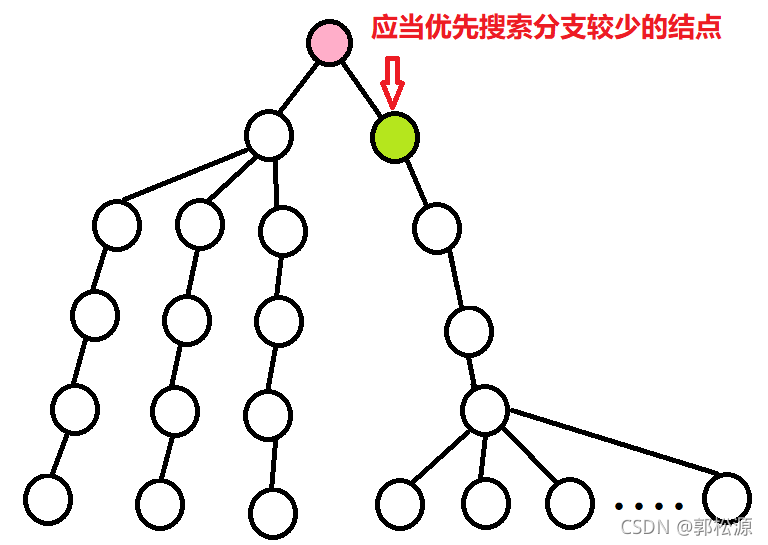
优化搜索顺序(非常重要)
大部分情况下,我们应该优先搜索分支较少的结点。
原因在于我们搜索分支较少的结点时,更有可能更快地得到一些局部最优解的方案结果,可以利用这个局部最优解的结果来对后面搜索高分支数量的结点进行剪枝,以达到减少时间的效果。
如果对应到背包问题,可以理解为先放一些大体积的物体进入背包,这样就减少了后续可能的分支数,可以尽快的先得出一些结果,然后利用这些结果对其他分支先进行剪枝。
排除等效冗余
比如我们从 n nn 种物品中挑选 m mm个物品,问一共有多少种不同的方案,同时要输出不同的方案。我们知道在某个方案中,比如 [1,2,3],那么它应该和 [2,1,3] 是完全等价的。因此,如果不需要考虑顺序的情况下,尽量用求组合数的方式来搜索。
例题
马在中国象棋以日字形规则移动。
请编写一段程序,给定 n∗m 大小的棋盘,以及马的初始位置 (x,y),要求不能重复经过棋盘上的同一个点,计算马可以有多少途径遍历棋盘上的所有点。
输入格式
第一行为整数 T,表示测试数据组数。
每一组测试数据包含一行,为四个整数,分别为棋盘的大小以及初始位置坐标 n,m,x,y。
输出格式
每组测试数据包含一行,为一个整数,表示马能遍历棋盘的途径总数,若无法遍历棋盘上的所有点则输出 0。
数据范围
1≤T≤9,
1≤m,n≤9,
0≤x≤n−1,
0≤y≤m−1
输入样例:
1
5 4 0 0
输出样例:
32
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 10;
int n, m;
bool st[N][N];
int ans;
int dx[8] = {-2, -1, 1, 2, 2, 1, -1, -2};
int dy[8] = {1, 2, 2, 1, -1, -2, -2, -1};
void dfs(int x, int y, int cnt)
{
if (cnt == n * m)
{
ans ++ ;
return;
}
st[x][y] = true;
for (int i = 0; i < 8; i ++ )
{
int a = x + dx[i], b = y + dy[i];
if (a < 0 || a >= n || b < 0 || b >= m) continue;
if (st[a][b]) continue;
dfs(a, b, cnt + 1);
}
st[x][y] = false;
}
int main()
{
int T;
scanf("%d", &T);
while (T -- )
{
int x, y;
scanf("%d%d%d%d", &n, &m, &x, &y);
memset(st, 0, sizeof st);
ans = 0;
dfs(x, y, 1);
printf("%d\n", ans);
}
return 0;
}
单词接龙是一个与我们经常玩的成语接龙相类似的游戏。
现在我们已知一组单词,且给定一个开头的字母,要求出以这个字母开头的最长的“龙”,每个单词最多被使用两次。
在两个单词相连时,其重合部分合为一部分,例如 beast 和 astonish ,如果接成一条龙则变为 beastonish。
我们可以任意选择重合部分的长度,但其长度必须大于等于1,且严格小于两个串的长度,例如 at 和 atide 间不能相连。
输入格式
输入的第一行为一个单独的整数 n 表示单词数,以下 n 行每行有一个单词(只含有大写或小写字母,长度不超过20),输入的最后一行为一个单个字符,表示“龙”开头的字母。
你可以假定以此字母开头的“龙”一定存在。
输出格式
只需输出以此字母开头的最长的“龙”的长度。
数据范围
n≤20
输入样例:
5
at
touch
cheat
choose
tact
a
输出样例:
23
提示
连成的“龙”为 atoucheatactactouchoose。
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 21;
int n;
string word[N];
int g[N][N];
int used[N];
int ans;
void dfs(string dragon, int last)
{
ans = max((int)dragon.size(), ans);
used[last] ++ ;
for (int i = 0; i < n; i ++ )
if (g[last][i] && used[i] < 2)
dfs(dragon + word[i].substr(g[last][i]), i);
used[last] -- ;
}
int main()
{
cin >> n;
for (int i = 0; i < n; i ++ ) cin >> word[i];
char start;
cin >> start;
for (int i = 0; i < n; i ++ )
for (int j = 0; j < n; j ++ )
{
string a = word[i], b = word[j];
for (int k = 1; k < min(a.size(), b.size()); k ++ )
if (a.substr(a.size() - k, k) == b.substr(0, k))
{
g[i][j] = k;
break;
}
}
for (int i = 0; i < n; i ++ )
if (word[i][0] == start)
dfs(word[i], i);
cout << ans << endl;
return 0;
}
给定 n 个正整数,将它们分组,使得每组中任意两个数互质。
至少要分成多少个组?
输入格式
第一行是一个正整数 n。
第二行是 n 个不大于10000的正整数。
输出格式
一个正整数,即最少需要的组数。
数据范围
1≤n≤10
输入样例:
6
14 20 33 117 143 175
输出样例:
3
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 10;
int n;
int p[N];
int group[N][N];
bool st[N];
int ans = N;
int gcd(int a, int b)
{
return b ? gcd(b, a % b) : a;
}
bool check(int group[], int gc, int i)
{
for (int j = 0; j < gc; j ++ )
if (gcd(p[group[j]], p[i]) > 1)
return false;
return true;
}
void dfs(int g, int gc, int tc, int start)
{
if (g >= ans) return;
if (tc == n) ans = g;
bool flag = true;
for (int i = start; i < n; i ++ )
if (!st[i] && check(group[g], gc, i))
{
st[i] = true;
group[g][gc] = i;
dfs(g, gc + 1, tc + 1, i + 1);
st[i] = false;
flag = false;
}
if (flag) dfs(g + 1, 0, tc, 0);
}
int main()
{
cin >> n;
for (int i = 0; i < n; i ++ ) cin >> p[i];
dfs(1, 0, 0, 0);
cout << ans << endl;
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号