
文件和IO
一. 打开文件
在python中无论是从文件中读取内容还是把内容写到文件中,都需要打开文件。打开文件使用的是内置函数open。
open函数有许多参数,在官方文件中open函数定义如下:

可以从函数定义中看到,open函数只有file参数是必须传递的,其他参数都有默认值。
1. 文件模式
open函数的参数mode十分重要,它指明了要以何种方式打开文件。使用不同的方式打开文件,即使操作相同,产生的效果也会有所不同。默认的模式是”r“,即以读的方式打开文件,文件只能阅读但不能进行写的操作。可用的模式如下:

Python在读写文件时会区分二进制和文本两种方式。如果以二进制方式打开文件(模式中带有”b“),内容将作为字节对象返回,不会对文件内容进行任何解码;如果以文本方式打开文件(模式中不带”b“,默认文本方式),内容将会作为字符串str类型返回,文件内容他会根据平台相关编码或者指定了的”encoding“参数的编码进行解码。
2. 文件编码
在文本方式下,如果没有指定编码,Python解释器会根据不同的系统使用不同的编码来解码。默认情况下,Python会调用标准库locale的getpreferredencoding方法来获取系统默认编码[locale.getpreferredencoding(False)],以作为文本方式解码文件内容的编码。
这里需要注意的一点是,不同的编码对阿拉伯数字和英文字符”a ~ z“和”A ~ Z“等基本字符的编码是一样的,区别在于对那些特有字符的编码上,例如中文等。如果使用UTF-8编码保存文件,然后使用GBK编码读取文件,就会产生乱码甚至程序出错;反之亦然。所以在文件读写前,请务必确认文件的编码以及应用场景。
默认情况下,大部分系统使用的编码都是UTF-8,比如Web应用程序,但是Windows操作系统默认使用的编码是GBK。Python支持非常多的文本编码,其中常见的是ASCII,Latin-1,UTF-8和UTF-16。
ASCII对应Unicode编码在U+0000到U+007F范围内的7位字符;Latin-1是字节0~255到U+0000至U+00FF范围内Unicode字符的直接映射。当读取一个未知编码的文本时,使用Latin-1编码永远不会产生编码错误。使用Latin-1编码读取文件,也许不能产生完全正确的文本解码数据,但是它也能从中取出足够多的有用数据。同时,如果你之后将数据回写,原先的数据还是会被保留。
3. 文件缓冲
缓冲的目的是减少系统的IO调用,只有在符合一定条件(比如缓冲数量)之后系统才调用IO写入磁盘。
缓冲参数buffering是用于设置缓冲策略的可选整数,设置为”0“时用以关闭缓冲(仅允许在二进制下使用);设置为”1“时选择行缓冲(仅在文本模式下可用);当参数是大于”1“的整数时,可以指示固定大小的块缓冲区的大小(以字节为单位)。如果未给出缓冲参数,则默认缓冲策略的工作方式如下:
二进制文件在固定大小的块中进行缓冲,缓冲区的大小则是通过使用试探法来试图确认底层设备的”块大小“的,然后将之后储存到io.DEFAULT_BUFFER_SIZE变量当中。在许多系统中,缓冲区的长度通常是4096个或8192个字节长。
二. 文件基本操作
1. 读文件
使用open函数返回的是一个对象,有了文件对象就可以开始读取其中的内容了。如果只是希望读取整个文件并保存到一个字符串中,就可以使用read方法。
使用read方法能够从一个打开的文件中读取内容到字符串。需要注意的是,Python的字符串可以是二进制的数据,而不仅仅是文字。
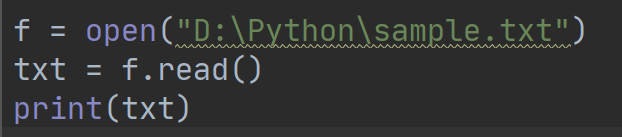
执行结果如下:
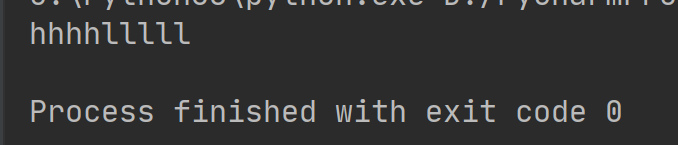
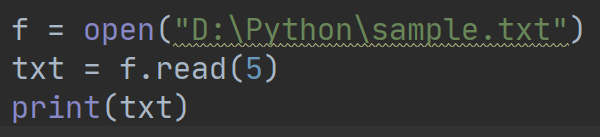
read方法也可以传递参数,用于指定读取多少个字符,例如:
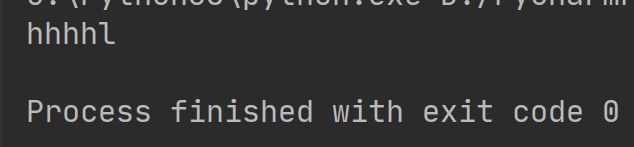
执行结果如下:
2. 写文件
如果使用只读模式打开文件,那么就不能在文件上执行写的操作,所以如果要写文件,则必须使用带”w“模式的方式打开文件。打开文件后可以使用文件对象write方法,将任意字符串写入到文件中。需要提醒的是,Python的字符串可以是二进制数据,而不仅仅是文字。write方法返回写入文件中的字符串的长度,例如:
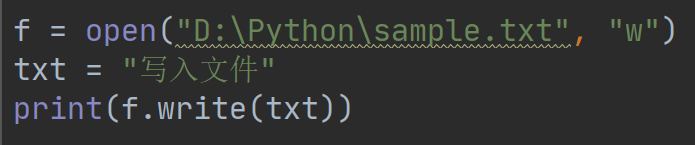
执行结果如下:
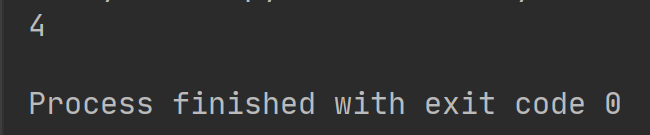
从结果上看,write方法返回了数字”4“,表示我们成功地在”txt"变量上写入了“txt”变量中的四个中文字符。
我们可以尝试多次运行整个例子,就能发现无论运行多少次程序,文件中都只有“写入文件”四个字符,看上去像只执行了一次。事实并非如此,实际上使用了“w“模式打开文件进行写文件操作”write“,此操作每次都会从头开始覆盖原有的内容,无论文件是否有内容,文件的内容都会被替换掉。
如果我们想在已有的文件内容后面追加内容,可以在打开文件时使用”a"模式,这样就能在文件中追加内容了,例如:
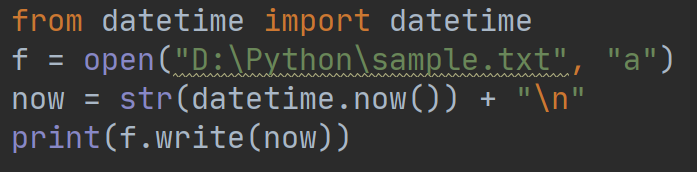
执行结果:
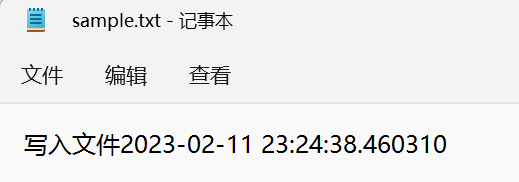
我们使用了datatime模块来获取当前时间,每次运行这个程序,文件都会追加一行写入文件的时间信息。
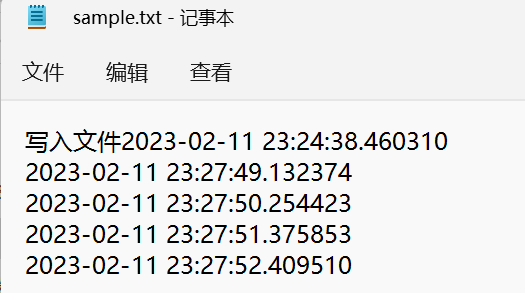
3. 按行读文件
前面章节介绍读文件 是读取整个文件到变量中,这在处理小文件时非常有用。但是如果要处理的文件很大,例如有上百万行的学生数据要处理,那么读取整个文件到一个变量就显得不是很明智。因为将整个文件导入到系统内存中时,如果系统内存不足可能会使程序崩溃。因此,Python提供了一个按行读取文件内容的方法,使用readline函数可以逐行读取文件内容。
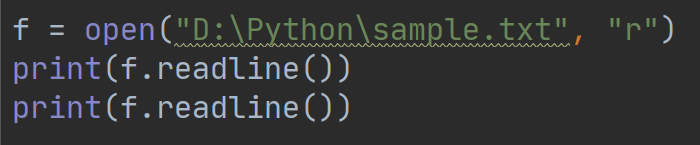
执行这个例子会打印出两行我们之前使用“a”模式写入的时间信息,执行结果如下:
readlines函数和read函数类似,都是读取整个文件,但是readline函数会把文件内容按行切割,返回一个list列表对象。例如:

执行这个例子会把文件中的日期一行行地打印在频幕上。
注意:readlines函数会保留结尾的换行符,所以直接print列表元素会发现每次输出都跟随一个空白行。
除了使用readline和readlines方法,还能直接迭代文件对象本身,例如:
这个例子的输出结果和readlines例子中的一模一样,区别在于readlines会读取整个文件并返回一个list,但是直接迭代文件对象是一种“惰性”读取文件的方式,只有迭代到需要读取的一行,才会真的执行操作。这样的好处使如果文件十分大,并且只需要一行一行的处理文件,就不用把整个文件都导入到内存中。
4. 按行写文件
写文件不仅仅可以像前面介绍的按字符串来写,也可以按行来写,Python提供了writeline方法,把列表作为参数写入文件,因为Python并不会帮我们添加换行符。
writelines方法接收一个参数,这个参数必须是列表,列表的每个元素就是想写入的每行文本内容。但是我们在列表中需要自行添加换行符,writerlines不会帮我们在每行之后添加换行符。例如:
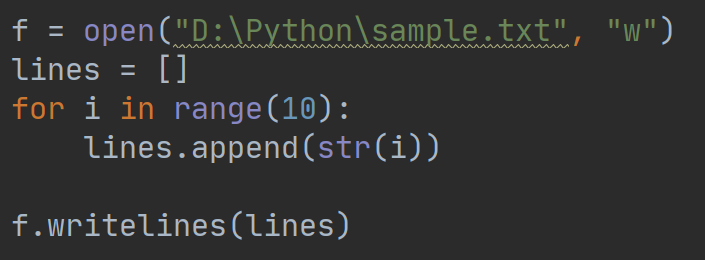
执行结果:

这个例子运行之后会在文件中生成0到9十个数字,并且不会换行。
5. 关闭文件
前面介绍了各种文件的读取和写入操作,但都没有提及在读取和写入文件的过程中出现异常该怎么处理。在读取文件的时候会因为一些外界因素而出现异常,特别是在大文件的读取和写入时,稍不注意就容易产生异常(例如:内存不足或者磁盘空间不够等)。
使用try语句捕获可能出现的相关异常,然后进行对应的处理(需要注意一点,无论是否有异常都需要关闭文件)
一般情况下,文件对象在程序退出后都会自动关闭,但是为了安全起见,最好还是显示调用close方法来关闭文件比较好。一般使用方法如下:
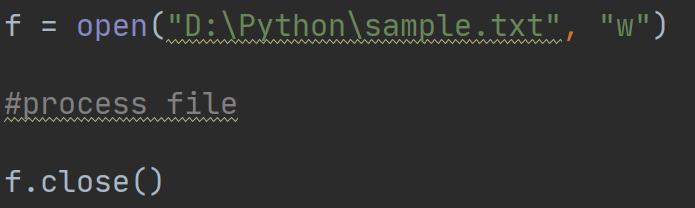
这个例子中代码最后一行f.close()执行和不执行,看到的结果都是一样,但如果在执行close方法之后再进行相关文件操作就会出现ValueError:I/O operation on clased file.的异常提示,说明该文件已经被关闭,不能再进行操作了。显示的调用close方法可以避免在某些操作系统或者设置中进行无用的修改,也可以避免用完操作系统中所打开文件的配额。
对文件进行写操作之后一定要记得关闭文件,因为写入的数据可能会被缓存,如果程序或者系统因为某些原因崩溃了的话,缓存的数据是不会写入文件中的。所以安全起见,在使用完文件之后一定要记得关闭文件。
在使用try语句出现异常之后,Python解释器会放弃之后的语句而去执行catch捕获到异常的语句,所以建议close方法在finally语句中执行,保证无论是否异常都会执行close方法并关闭文件。例如:
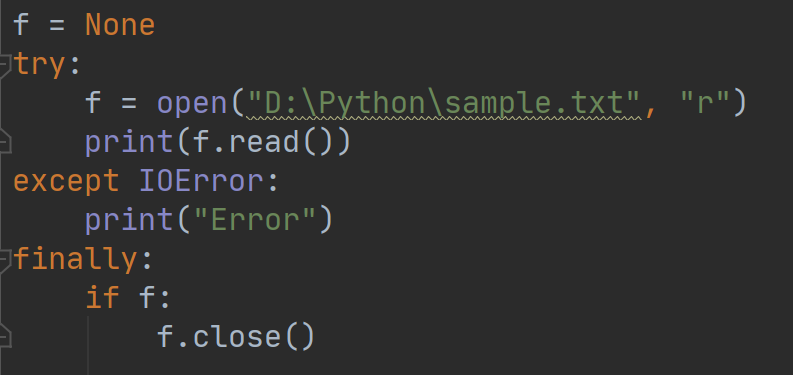
这个例子在文件处理的异常语句finally语句块中执行了close方法,确保了文件会被关闭。
每个打开的文件要执行close方法关闭文件,但有时候文件处理的逻辑比较复杂,很容易忘记关闭文件。Python引入了with语句来帮助我们自动调用close方法。例如:

这段代码中,我们没有手动调用close函数,但是由于我们使用了with语句,Python解释器会在with语句的代码块执行完之后帮助我们执行close语句。使用with语句比不适用with语句的代码更简洁。
三. StringIO和ByteIO
前面介绍了Python对于文件的读取和写入,但有时候数据并不需要真正地写入到文件中,只需要在内存中做读取写入即可。Python的IO模块提供了对str操作的StringIO函数。
要把str写入StringIO,我们需要先创建一个StringIO对象,然后像文件一样写入即可,例如:
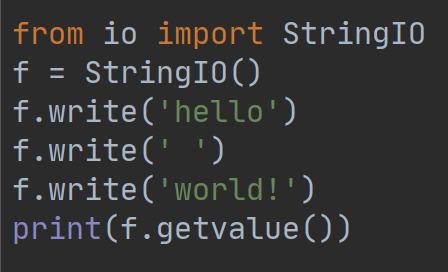
执行结果如下:
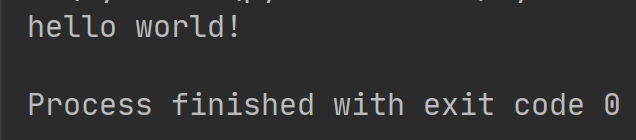
创建StringIO对象,然后调用write方法写入数据,和文件操作几乎相同。getvalue方法用于获得写入后的str。
要读写StringIO,可以先用一个str初始化StringIO,然后像都文件一样读取。例如:
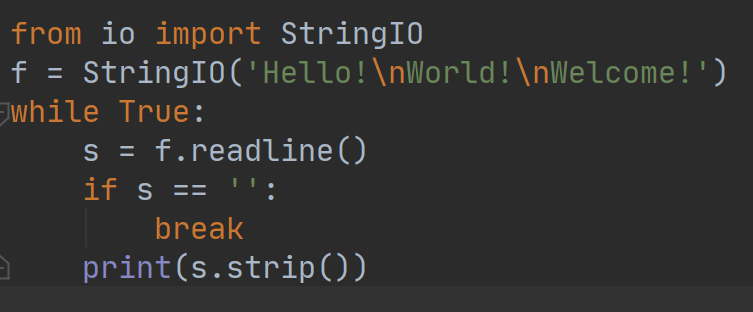
执行结果如下:
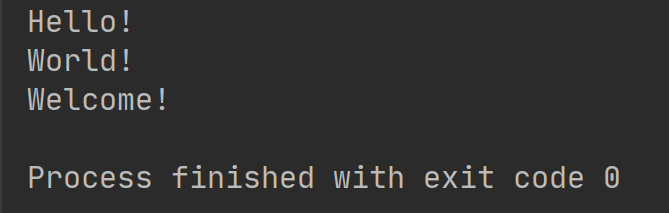
StringIO的操作对象只能是str,如果要操作二进制数据,就需要使用BytesIO。
BytesIO实现了在内存中读写bytes,我们可以先创建一个BytesIO,然后写入一些bytes,例如:
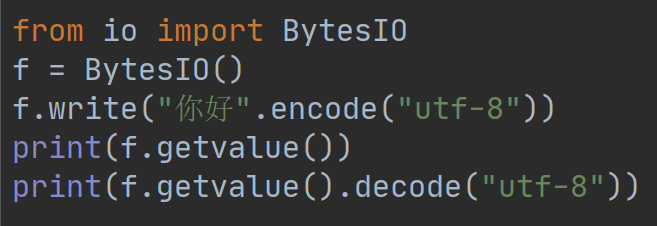
执行结果如下:
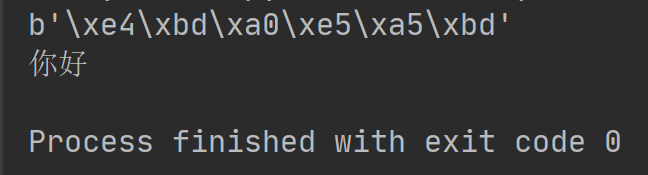
注意:写入的不是str,而是经过UTF-8编码的bytes。
和StringIO类似,可以先用一个bytes初始化BytesIO,然后像读文件一样读取,例如:
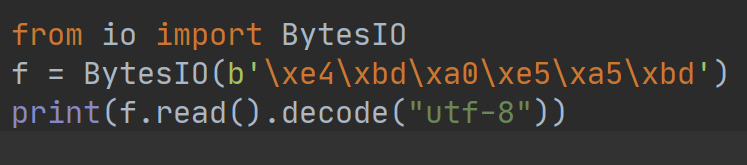
执行结果如下:
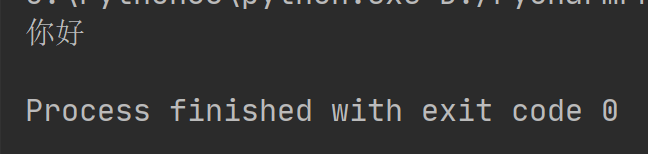
四. 序列化和反序列化
程序在运行的时候,所有变量都是保持在计算机内存中的,我们可以把变量从内存中转存到磁盘或者别的存储介质上,这个把变量从内存中变成可存储或传输的过程被称为序列化。我们可以把序列化后的内容写入磁盘或者通过网络传输到别的计算机上。反过来,我们把变量内容从序列化的对象重新读取到内存的过程被称为反序列化。
简单来说,序列化就是将数据结构或者对象转换成二进制串的过程,反序列化就是将序列化过程中生成的二进制串转回成数据结构或对象的过程。
1. pickle模块
pickle模块使Python标准库中的模块,它实现了一些基本数据的序列化和反序列化。
通过pickle模块的序列化操作,我们可以将程序中运行的对象信息保存到文件中,永久存储;通过pickle模块的反序列化操作,我们可以从文件中恢复或者创建上次程序保存下来的对象。
pickle模块的dumps方法可以把对象序列化成bytes,例如:
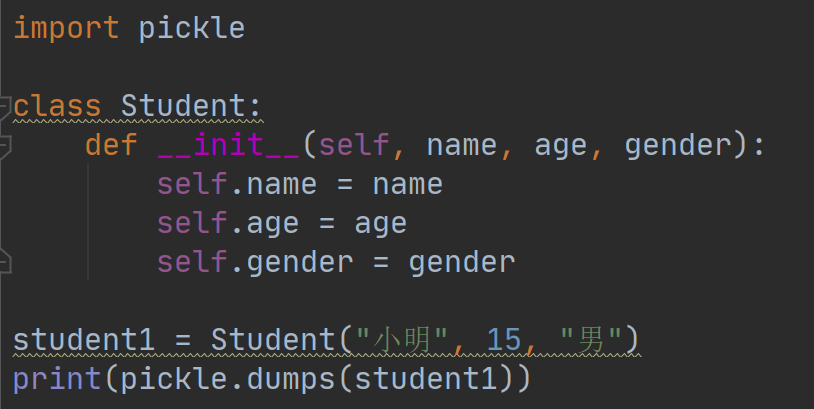
执行这个例子会打印出序列化后的bytes对象。pickle.dumps可以把任意对象序列化成bytes对象,然后写入文件中永久存储。
pickle.dump方法可以帮助我们任意对象序列化成bytes,然后直接写入到文件对象中,不需要我们再一步一步地写入到文件中。例如:
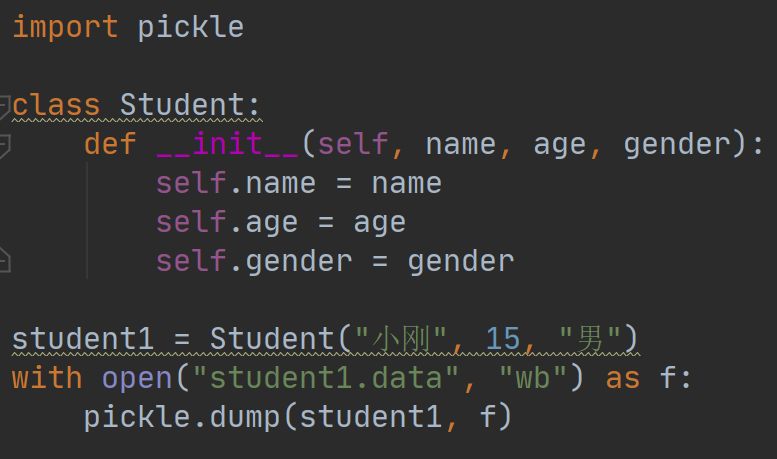
执行这个例子会生成student1.data,这个文件包含了代码中student1对象的信息。用文本编辑器打开student1.data文件会看到一堆看不懂的内容,这些都是pickl保存的对象信息。
既然已经将序列化的内容保存到文件中了,在使用文件时自然也可以把对象从磁盘读取到内存中。我们可以先把内容读取到一个bytes对象中,然后使用pickle.loads方法获取反序列化后的对象,例如:
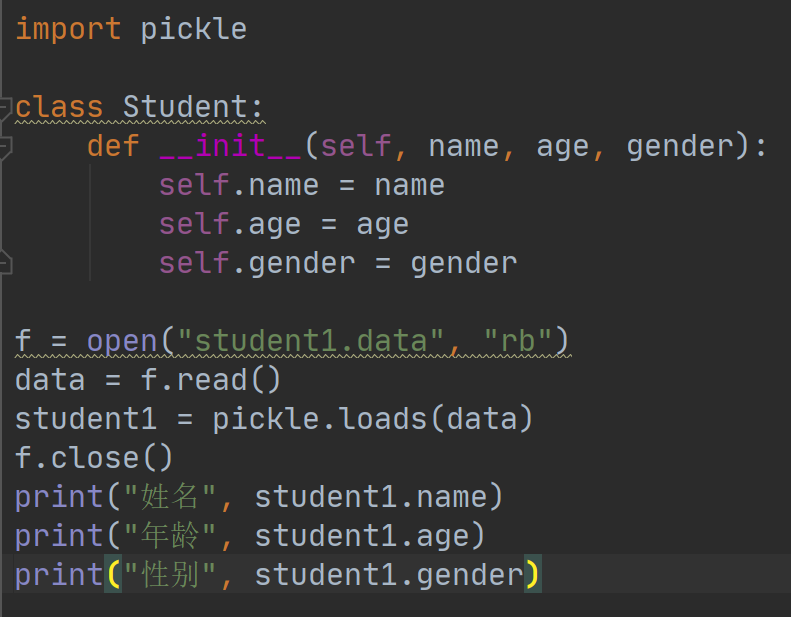
执行结果如下:
从这个例子可以看到文件中的student1对象被正确地读出来并加载到变量中(注意:类定义不能省略)
序列化的时候可以直接写入文件对象,读取的时候当然也可以直接从文件对象中读取,例如:
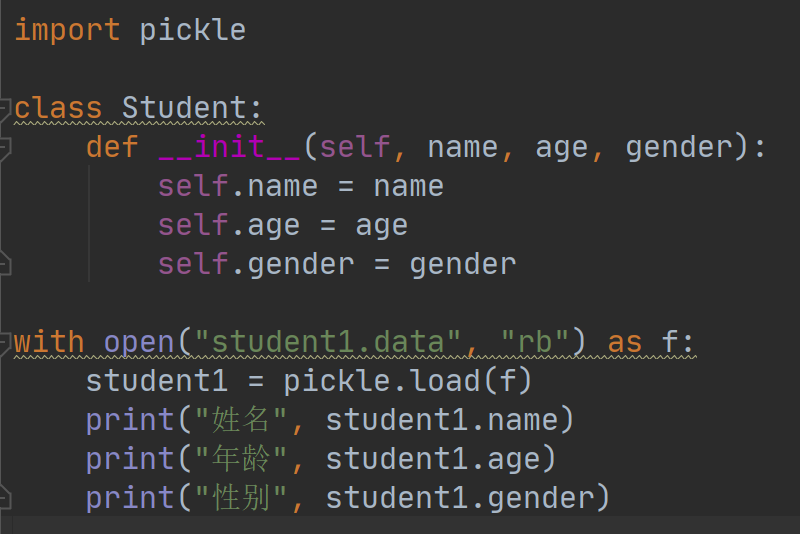
执行结果如下:
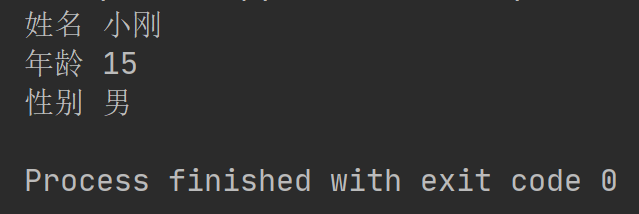
这个执行结果和我们手动读取bytes然后是哦那个loads方法反序列化的效果是一样的。
注意:pickle的序列化和反序列化操作只能用于Python而不能被其他怨言读取,并且不同版本的Python之间也可能存在兼容性问题,所以在使用pickle做序列化与反序列化操作的时候要注意一点。
2. JSON序列化与反序列化
上面已经介绍了模块pickle能偶用于序列化和反序列化,但是pickle有一个致命缺点,就是只支持Python,并不支持其他语言,幸好Python还内置了JSON模块,也可以用于序列化和反序列化。
JSON(JavaScript Object Notation,JavaScript对象表示法)是一种轻量级的数据交换格式,易于阅读和编写,也易于机器解析和生成。它是基于JavaScript编程语言的。JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C,C++,C#,Java,JavaScript,Perl,Python等),这些特性使JSON成为理想的数据交换语言。
JSON构建于两种结构:
(1)“名称/值对”的集合。不同的语言中那个,他被理解为对象,记录,结构,哈希表,有键列表或者关联数组等,在Python中对应的就是字典。
(2)值的有序列表。在大部分语言中,它被理解为数组,在Python中对应的就是列表。
JSON类型和Python类型转化对照表如下:

json模块的序列化使用方法和pickle模块一模一样,但是pickle可以序列化任意Python对象,而json模块只能序列化表中对应的类型。
使用json模块序列化字典:
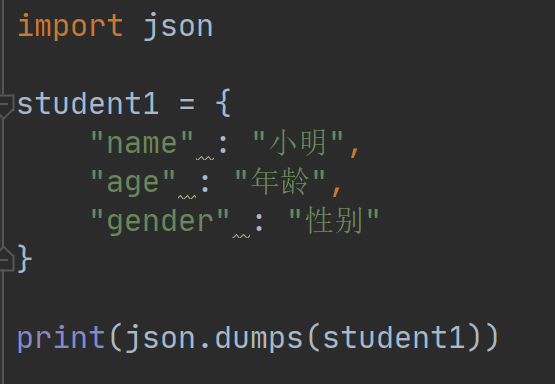
执行结果如下:

注意:json模块会把中文转码为Unicode编码。
和pickle模块一样,json模块也可以直接写入文件对象,例如:
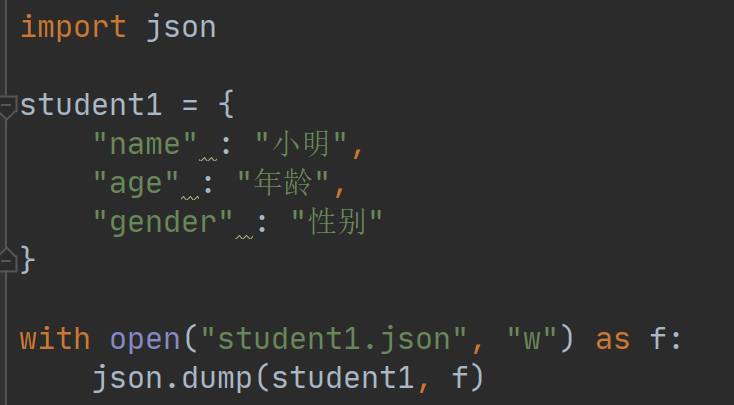
执行这个例子,可以用文本编辑器打开student1.json,看到的结果和先前的例子打印在屏幕上的结果一模一样。
使用json模块反序列化的使用方法和pickle模块也是一样的,不过json反序列化只能应用在使用json序列化的数据上,不能反序列化pickle模块序列化后的bytes数据。例如:
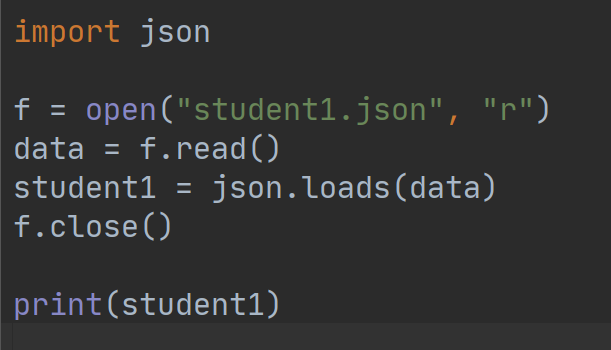
执行结果如下:

和pickle模块一样,json模块也可以直接从文件对象反序列化,例如:
执行结果如下:

可以看到json模块反序列化的使用方式和pickle模块一模一样。
注意:json模块的特点是各种语言都支持JSON格式数据,没有兼容性问题,但是json模块只能序列化部分类型的数据;而pickle模块可以序列化大部分的python对象,但是只有python支持对pickle模块序列化后的数据进行反序列化。这是两个模块的优劣之处。
五. 总结
Python提供了丰富的方法来操作文件和数据,读写文件的时候要特别注意文件的编码,程序中的编码参数需要和文件编码保持一致才能正确地读取内容。Python语言中的序列化和反序列化,JSON格式可以跨语言使用,但是支持的可序列化对象没有pickle模块丰富。

