
java集合之Map接口及其实现类
一、Map集合
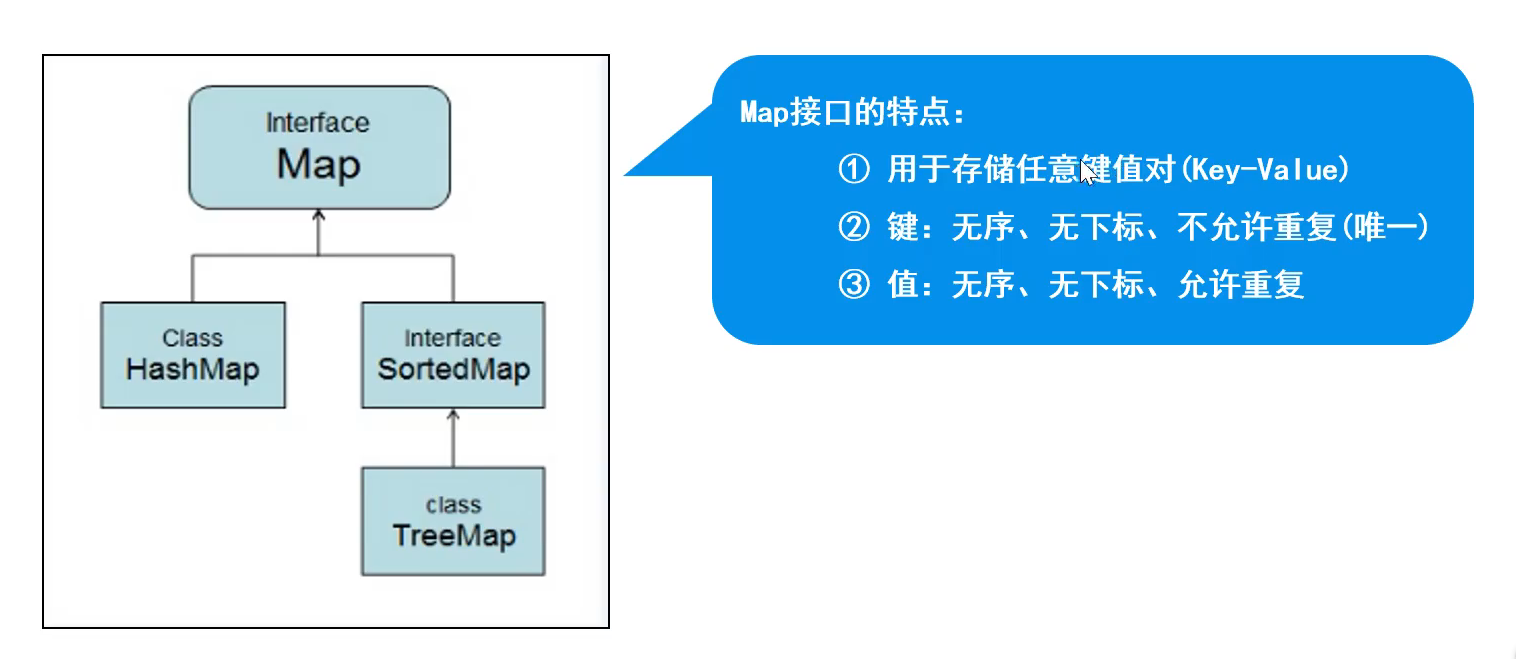
- 特点:存储一对数据(Key-Value),无序、无下标,键不可重复,值可重复。
- 方法:
- put(K key,V value)//将对象存入到集合中,关联键值。key重复则覆盖原值。
- get(Object key)//根据键获取对应的值
- keySet()//返回所有的key的集合
- values()//返回包含所有值的Colletion集合
- Map.Entry<K,V>//键值匹配的Set集合
二、Map接口的使用
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
/**
* Map集合是键值对的集合,无顺序,无下标,键不能重复,值可以重复
*/
public class MapInterfacDemo {
public static void main(String[] args) {
Map<String,String> map=new HashMap<String,String>();
//添加数据
map.put("CH","中国");
map.put("FA","法国");
map.put("USA","美国");
map.put("USA","meiguo");
System.out.println(map.size());
System.out.println(map);
//删除数据
// map.remove("USA");//按键删除
// map.remove("FA","法国");//按键值删除
// System.out.println(map.size());
// System.out.println(map);
//遍历
//方法一,通过keySet方法获取key的Set集合
Set<String> set = map.keySet();//获取key的Set集合
for (String s : set) {
System.out.println(s+"----"+map.get(s));//get方法通过键获取值
}
//方法二,通过entrySet方法获取键值对的封装entry
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
System.out.println(entry.getKey()+"---"+entry.getValue());
}
//判断
System.out.println(map.containsKey("USA"));
System.out.println(map.containsValue("meiguo"));
}
}
三、hashMap的使用
- JDK1.2后加入使用,线程不安全,适用于单线程,运行效率快,允许用null作为键或值
import java.util.HashMap;
import java.util.Map;
/**
* Hashmap存储结构
* 数组+链表+红黑树
*/
public class HashMapdemo {
public static void main(String[] args) {
HashMap<Student,String> hashMap=new HashMap();
Student s1=new Student("刘备",001);
Student s2=new Student("关羽",002);
Student s3=new Student("张飞",003);
//添加
hashMap.put(s1,"逐县");
hashMap.put(s2,"小沛");
hashMap.put(s3,"巨鹿");
//hashMap.put(s3,"xiaopei");//键相同,则会覆盖之前的值
//如果不重写hashcode和equals方法,则这个地方默认会添加一个数据,如果重写hashcode和equals方法就会将s3和
//new Student("张飞",003)视为同一个对象,此时,因为键相同,所以不会添加,而进行替换
hashMap.put(new Student("张飞",003),"洛阳");
System.out.println(hashMap.size());
System.out.println(hashMap);
//删除
//hashMap.remove(s1);//通过键删除
// hashMap.remove(s1,"逐县");//通过键值删除
// System.out.println(hashMap.size());
// System.out.println(hashMap);
//遍历
//1.keyset
for (Student student : hashMap.keySet()) {
System.out.println(student+"----"+hashMap.get(student));
}
//2.entrySet,效率高于keyset
System.out.println("=============entrySet==============");
for (Map.Entry<Student, String> studentStringEntry : hashMap.entrySet()) {
System.out.println(studentStringEntry.getKey()+"---"+studentStringEntry.getValue());
}
//判断
System.out.println(hashMap.containsKey(s1));
System.out.println(hashMap.containsValue("小沛"));
}
}
//Student类:
import java.util.Objects;
public class Student {
private String name;
private int stuNO;//学号
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getStuNO() {
return stuNO;
}
public void setStuNO(int stuNO) {
this.stuNO = stuNO;
}
public Student() {
}
public Student(String name, int stuNO) {
this.name = name;
this.stuNO = stuNO;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", stuNO=" + stuNO +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return stuNO == student.stuNO && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, stuNO);
}
}
四、hashMap源码分析
DEFAULT_INITIAL_CAPACITY = 1 << 4 //初始容量=1左移4位=16
MAXIMUM_CAPACITY = 1 << 30 //最大容量=1左移30位=2的30次方
DEFAULT_LOAD_FACTOR = 0.75f //扩容加载因子为0.75,如有100个数的话,进行扩容,会扩容100*0.75=75
TREEIFY_THRESHOLD = 8 //JDK1.8后HashMap引入红黑树,当链表(单向)的数据个数大于8个时,并且数组的长度大于64,将链表转换为红黑树,这样的目的是提升查找效率
UNTREEIFY_THRESHOLD = 6 //红黑树的数据个数小于6,则转换为链表的存储方式
MIN_TREEIFY_CAPACITY = 64 //进行树化的最小数组长度
Node<K,V> //链表结节
table //数组
size //hashmap的数据长度
- 重点:(针对数组的扩容)
- 默认加载因子为0.75,当size大于0.75*当前容量时(默认为16),进行扩容,此时临界值变为之前的2倍(2乘12),容量变为之前的两倍(2乘以16)
//默认无参构造方法
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // loadFactor是加载因子
}
static final float DEFAULT_LOAD_FACTOR = 0.75f;//默认加载因子为0.75
//put方法,调用putVal
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; //创建一个Node数组
Node<K,V> p; //创建一个Node
int n, i;
//当没有调用put方法时,table=null,size=0
//将table赋值给tab,如果为空,后面短路
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;//调用resize方法,将返回数组的长度赋值给n
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)//如果在put的过程中,size达到一个临界值,第一次添加变为12
resize();
afterNodeInsertion(evict);
return null;
}
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;//若table为null则返回0
int oldThr = threshold;//threshold默认也是0
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&//oldCap每次扩容增加2倍
oldCap >= DEFAULT_INITIAL_CAPACITY)//DEFAULT_INITIAL_CAPACITY为16
newThr = oldThr << 1; // 临界值每次扩容是之前的2倍
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;//DEFAULT_INITIAL_CAPACITY=16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//等于默认加载因子0.75*默认容量16=12
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;//newThr为新的临界值
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//创建一个容量为16的Node数组
table = newTab;//将这个数组赋值给table
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;//返回值
}
五、HashMap源码分析总结
1、HashMap刚创建时,table是null,为了节省空间;当添加第一个元素时,table容量调整为16
2、当元素个数大于阈值(16*0.75=12)时,会进行扩容,扩容后大小为原来的2倍。目的是减少调整元素的个数。
3、jdk1.8后:当每个链表长度大于8,并且数组元素个数大于等于64时,会调整为红黑树,目的是提高执行效率。
4、jdk1.8后:当红黑树长度小于6时,调整为链表。
5、jdk1.8以前链表是头插入,jdk1.8之后链表是尾插入。
六、HashSet源码分析
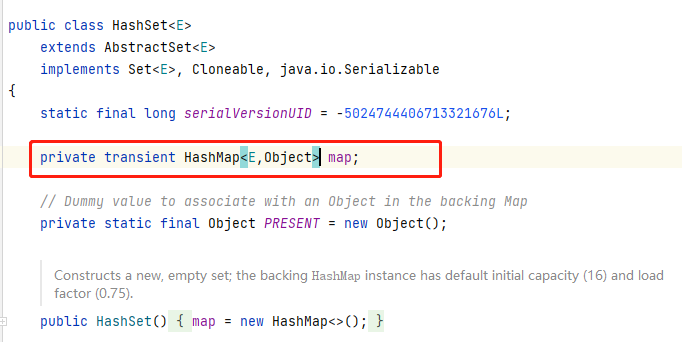
- hashSet底层使用的就是hashMap,只用了hashmap中的key

- add方法是调用的HashMap中的put方法,只使用key。
七、HashTable和Propeties
- Hashtable
jkd1.0版本,线程安全,运行效率低,现在用的不多。
Hashtable是同步的。
不允许null作为key或value。
无参构造方法的默认初始容量(11)、负载因子(0.75)。 - Properties
Hashtable的子类,要求key或value都是String。
通常用于配置文件的读取。
常和IO流联系在一起。
八、TreeMap
-
实现了SortedMap接口(Map的子接口),可以对key自动排序。
-
put时调用compare方法来进行比较,如果没有比较器,则用Comparable接口实现类的compareTo来进行比较

-
//例子 import java.util.Map; import java.util.TreeMap; public class TreeMapDemo { public static void main(String[] args) { TreeMap<Person,String> treeMap=new TreeMap<>(); //添加 Person p1=new Person("韩信",001); Person p2=new Person("项羽",002); Person p3=new Person("钟离昧",003); treeMap.put(p1,"汉中");//ClassCastException,需要实现Comparable接口并重写CompareTo方法,如果不重写Compare方法,会报以上错误,因为put方法调用后的数据排列规则没有定义 treeMap.put(p2,"巨鹿"); treeMap.put(p3,"汉水"); //treeMap.put(new Person("钟离昧",003),"hanshui");//重写CompareTo方法后,如此添加会失败,会对住址进行覆盖,因为CompareTo的方法比较的是Person的ID System.out.println(treeMap.size()); System.out.println(treeMap); //删除 //treeMap.remove(p3);//与下面的remove效果相同 // treeMap.remove(new Person("钟离昧",003)); // System.out.println(treeMap.size()); // System.out.println(treeMap); //遍历 //1.KeySet System.out.println("------------KeySet-------------"); for (Person person : treeMap.keySet()) { System.out.println(person+"-----"+treeMap.get(person)); } //2.EntrySet,效率比KeySet高,因为KeySet的treeMap.get(person)还会进行一次遍历 System.out.println("------------EntrySet-------------"); for (Map.Entry<Person,String> entry : treeMap.entrySet()) { System.out.println(entry.getKey()+"---"+entry.getValue()); } //判断 System.out.println(treeMap.containsKey(p1)); System.out.println(treeMap.containsKey(new Person("钟离昧", 003))); System.out.println(treeMap.containsValue("hanshui")); System.out.println(treeMap.containsValue("汉水")); } } //Person类: public class Person implements Comparable{ private String name; private int ID; public Person() { } public Person(String name, int ID) { this.name = name; this.ID = ID; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getID() { return ID; } public void setID(int ID) { this.ID = ID; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", ID=" + ID + '}'; } @Override public int compareTo(Object o) { //根据ID的不同来进行比较,以此来进行排序 int n1=this.getID()-((Person)o).getID(); return n1; } } -
如果Person类不实现Comparable接口,也可以通过匿名内部类为TreeMap指定比较器来实现比较规则的制定
TreeMap<Person,String> treeMap=new TreeMap<>(new Comparator<Person>() { @Override public int compare(Person o1, Person o2) { int i = o1.getID() - o2.getID(); return i; } }); -
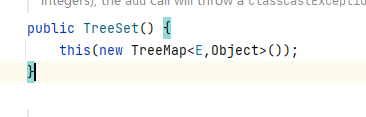
TreeSet和TreeMap的关系
-
TreeSet的构造方法默认是创建一个TreeMap集合。
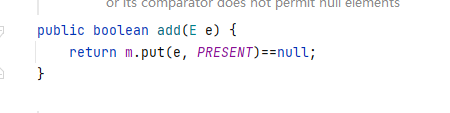
-
add方法则是调用的TreeMap的put方法,只使用了Key。
-
九、Collections工具类
import java.util.*;
public class CollectionsDemo {
public static void main(String[] args) {
ArrayList<Integer> arrayList=new ArrayList<Integer>();
arrayList.add(20);
arrayList.add(22);
arrayList.add(2);
arrayList.add(3);
arrayList.add(100);
System.out.println(arrayList.size());
System.out.println(arrayList);
//自定义比较规则
Collections.sort(arrayList, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
System.out.println(arrayList);
//sort,默认为正序
Collections.sort(arrayList);
System.out.println(arrayList);
//binarySearch,必须正序排序后才可使用
System.out.println(Collections.binarySearch(arrayList, 2));
//copy,需要目标数组的size大于等于源数组的大小,否则会报数组越界异常IndexOutOfBoundsException,需要通过赋值操作才能改变size的值,仅仅指定
//初始容量是没用的(容量指定与否不影响,因为会自动扩容)
ArrayList<Integer> arrayList1 = new ArrayList<>(1);
for (int i = 0; i < arrayList.size()+1; i++) {
arrayList1.add(null);//[2, 3, 20, 22, 100, null]
}
Collections.copy(arrayList1,arrayList);//第一个参数为目标数组,后一个参数为源数组
System.out.println(arrayList1);
//shuffle打乱(洗牌)
Collections.shuffle(arrayList);
System.out.println(arrayList);
//reserve反转
Collections.reverse(arrayList);
System.out.println(arrayList);
System.out.println("===========list转数组无参数toArray==========");
//补充:1.list转数组
//1.1.无参数toArray
Object[] Objects = arrayList.toArray();
for (Object object : Objects) {
System.out.println(object);
}
System.out.println("==========有参数toArray==========");
//1.2.有参数toArray
Integer[] integers = arrayList.toArray(new Integer[0]);//只要容量不超过arraylist的容量就行,超过元素为null(默认值)
for (Integer integer : integers) {
System.out.println(integer);
}
System.out.println("==========数组转list==========");
//数组转list,如此得到的集合不能添加删除操作,因为数组的大小是固定的
Integer []integers1={1,2,3,5,6,41};
List<Integer> asList = Arrays.asList(integers1);//注意是Arrays工具类的方法
//asList.add(1);//抛出异常UnsupportedOperationException
//asList.remove(1);//抛出异常UnsupportedOperationException
System.out.println(asList);
//基本类型数组转集合
int[] nums={1,2,5,3,65};
List<int[]> ints = Arrays.asList(nums);//这个方法返回的是int[]类型,这样的话List集合里只有一个int数组类型的元素
for (int[] anInt : ints) {
System.out.println(anInt);//因为是数组,所以打印出的是地址:[I@2503dbd3
}
//要使用基本类型的包装类
Integer[] nums2={1,2,5,3,65};
List<Integer> ints1 = Arrays.asList(nums2);
for (Integer anInt1 : ints1) {
System.out.println(anInt1);
}
}
}
十、集合总结
- 集合的概念:
- 对象的容器,和数组类似,定义了对多个对象操作的常用方法。
- List集合:
- 有序、有下标、元素可以重复。(ArrayList、LinkedList、Vector)
- Set集合:
- 无序、无下标、元素不可重复。(HashSet、TreeSet)
- Map集合:
- 存储一对数据,无序、无下标,键不可重复,值可重复。(HashMap、HashTable、TreeMap)
- Colletions
- 集合工具类,定义了除了存取以外的集合常用方法。
本文来自博客园,作者:一只快乐的小67,转载请注明原文链接:https://www.cnblogs.com/sp520/p/15934901.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号