
java集合之Set接口及其实现类
一、set集合概述
- 特点:无序、无下标、元素不可重复
- 方法全都是继承处collection
二、set接口的使用
-
set的实现类
-
HashSet:
- 基于HashCode实现元素不重复
- 当存入元素的哈希码相同时,会调用equals进行确认,如结果为true,则拒绝后者存入
-
TreeSet:
- 基于排列顺序实现元素不重复
-
import java.util.HashSet; import java.util.Iterator; import java.util.Set; /*** * set示例 * 无顺序、不能重复、无下标 */ public class SetDemo { public static void main(String[] args) { Set<String> set=new HashSet<>(); //添加 set.add("小米"); set.add("小米");//虽然不报错,但是不会添加 set.add("华为"); set.add("苹果"); System.out.println(set.size()); System.out.println(set);//[苹果, 华为, 小米],打印结果与顺序无关 //删除 set.remove("小米"); System.out.println(set.size()); System.out.println(set);//[苹果, 华为, 小米],打印结果与顺序无关 //遍历 //增强for for (String s : set) { System.out.println(s); } //迭代器 Iterator<String> iterator = set.iterator(); while(iterator.hasNext()){ System.out.println(iterator.next()); } //判断 System.out.println(set.contains("苹果")); System.out.println(set.isEmpty()); } }
-
三、HashSet实现类的使用
-
哈希表结构图解:
- 类似于去车站排队买票,总共5个窗口,每个窗口连在一起看成一个数组,当数据add时,数组如果有空位,直接加到数组中,如果没有位置,则用equals方法进行判断,如果不为true,单个元素处通过链表的方式往下加,如下图

-
import java.util.HashSet; import java.util.Iterator; /*** * HashSet集合的使用 * 存储结构:哈希表(数组+链表+红黑树) */ public class HashSetDemo { public static void main(String[] args) { HashSet<String> hashSet=new HashSet<>(); //1.添加元素 hashSet.add("曹操"); hashSet.add("孙权"); hashSet.add("刘备"); hashSet.add("张飞"); hashSet.add("张飞");//不报错,但添加不会成功 System.out.println(hashSet.size()); System.out.println(hashSet);//[孙权, 张飞, 刘备, 曹操],打印顺序并不一致 //2.删除元素 hashSet.remove("刘备"); //hashSet.clear(); System.out.println(hashSet.size()); System.out.println(hashSet);//[孙权, 张飞, 曹操] //3.遍历 //3.1增强for for (String s : hashSet) { System.out.println(s); } //3.2iterator Iterator<String> iterator = hashSet.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } //4.判断 System.out.println(hashSet.contains("孙权")); System.out.println(hashSet.isEmpty()); } } -
要实现引用类型字段内容相同来判断,则需要重写hashcode和equals方法
-
import java.util.HashSet; import java.util.Iterator; /** * 存储结构:哈希表+链表+红黑树(JDK1.8之后) * 存储过程 * 1.根据hashcode计算要存放的位置,如果位置为空,则直接保存,如果不为空则执行第二步 * 2.执行equals方法,如果equals方法为true,则认为是重复不进行保存,如果为false则形成链表 */ public class HashSetDemo02 { public static void main(String[] args) { HashSet<Person> persons=new HashSet<Person>(); Person p1=new Person("韩信",20); Person p2=new Person("刘邦",41); Person p3=new Person("项羽",25); persons.add(p1); persons.add(p2); persons.add(p3); //persons.add(p3);//重复添加无效果 System.out.println(persons.size());//3 System.out.println(persons);//[Person{name='刘邦', age=41}, Person{name='项羽', age=25}, Person{name='韩信', age=20}],无序,不能重复 //persons.add(new Person("项羽",25));//没重写hashcode和equals之前,new 出来的对象的地址是不样的,因此hashcode也不一样,因此可以add //System.out.println(persons.size());//4 //System.out.println(persons);//[Person{name='刘邦', age=41}, Person{name='项羽', age=25}, Person{name='项羽', age=25}, Person{name='韩信', age=20}] //想要实现new Person()中的name和age和之前的一样进行判断,则需要重写hashcode和equals方法 //重写hashcode后正面的hashcode是一样的 System.out.println(new Person("项羽",25).hashCode());//1242749 System.out.println(p3.hashCode());//1242749 // persons.add(new Person("项羽",25));//重写hashcode方法后,还是能添加,因为equals返回的是false // System.out.println(persons.size());//4 persons.add(new Person("项羽",25));//重写hashcode方法和equals方法后,不能添加,因为equals返回Ture System.out.println(persons.size());//3 //如果只重写equals,可能会添加,也可能不会添加,因为hashcode计算出的值可能会写在同一个位置,remove也是依照hashcode和equals来进行处理的 //也可以通过快捷方式重写hashcode和equals方法 persons.remove(new Person("项羽",25)); System.out.println(persons.size());//2 for (Person person : persons) { System.out.println(person); } Iterator<Person> iterator = persons.iterator(); while (iterator.hasNext()) { iterator.next(); } System.out.println(persons.contains(new Person("刘邦",41)));//true System.out.println(persons.isEmpty());//false } } //Person类 import java.util.Objects; public class Person { private String name; private int age; public Person() { } public Person(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public int getAge() { return age; } public void setName(String name) { this.name = name; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Person person = (Person) o; return age == person.age && name.equals(person.name); } @Override public int hashCode() { return Objects.hash(name, age); } } -
HashSet类的hashCode方法重写补充
-
//使用快捷方式,默认是调用下面的方法来进行重写 //用31来进行运算的原因: //1.31是一个质数(只能被1和它本身整除),用它来计算可以减少散列冲突 //2.可以提高执行效率,31*i=(i<<5)-i public static int hashCode(Object a[]) { if (a == null) return 0; int result = 1; for (Object element : a) result = 31 * result + (element == null ? 0 : element.hashCode()); return result; }
四、TreeSet实现类的使用
-
TreeSet
- 基于排列顺序实现元素不重复
- 实现了SortedSet接口,对集合元素自动排序
- 元素对象的类型必须实现Comparable接口,指定排序规则
- 通过CompareTo方法确定是否为重复元素
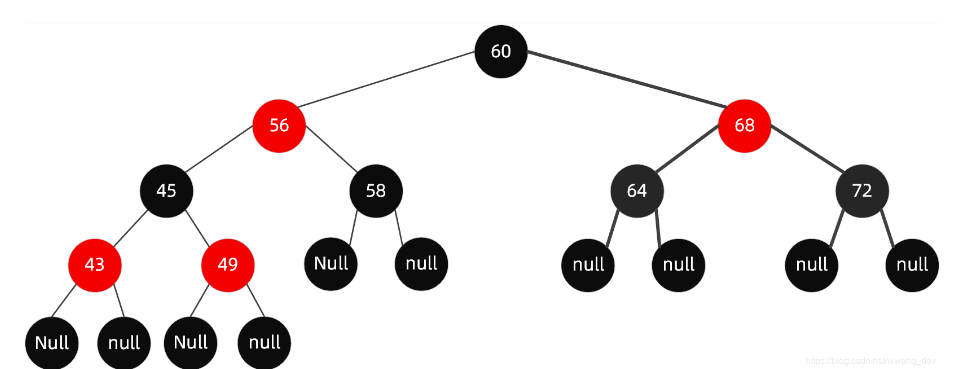
- 其存储结构为红黑树
- 节点的左孩子的值小于节点本身;
- 节点的右孩子的值大于节点本身;
- 左右子树同样为二叉搜索树;
- 红黑是为了维持一种平衡
-
简单例子
-
import java.util.Iterator; import java.util.TreeSet; /** * 存储结构:红黑树 */ public class TreeSetDemo { public static void main(String[] args) { TreeSet<String> treeSet=new TreeSet<>(); //添加 treeSet.add("abc"); treeSet.add("xyz"); treeSet.add("hello"); System.out.println(treeSet.size()); System.out.println(treeSet); //删除 treeSet.remove("abc"); System.out.println(treeSet); //遍历 //1.foreach for (String s : treeSet) { System.out.println(s); } //2.迭代器 System.out.println("---------"); Iterator<String> iterator = treeSet.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } //判断 System.out.println(treeSet.contains("xyz")); } }
-
-
如果add自定义类型,需要实现Comparable接口,重写CompareTo方法,以确定数据的添加规则。
-
import java.util.Iterator; import java.util.TreeSet; public class TreeSetDemo02 { public static void main(String[] args) { TreeSet<Person> treeSet=new TreeSet<>(); Person p1=new Person("韩邦胜",25); Person p2=new Person("韩邦胜",20); Person p3=new Person("宋平",26); //ClassCastException: MrHan.SetInterface.Person cannot be cast to java.lang.Comparable //类型转换异常,如果不重写CompareTo方法,则add的时候不知道如何进行比较以确定是否为重复以及是否添加 treeSet.add(p1); treeSet.add(p2); treeSet.add(p3); treeSet.add(p3); System.out.println(treeSet); //删除,remove也是通过compareTo来判断的 treeSet.remove(new Person("韩邦胜",25)); System.out.println(treeSet); //遍历 //foreach for (Person person : treeSet) { System.out.println(person); } //迭代器 Iterator<Person> iterator = treeSet.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } //判断 System.out.println(treeSet.contains(p1)); } } //Person类中的compareTo方法 //重写ComPareTo方法 @Override public int compareTo(Person o) { //先判断姓名,再判断年龄,返回0则代表重复 int n1=this.name.compareTo(o.name); int n2=this.age-o.age; return n1==0?n2:n1; }
-
-
comparator:比较器,TreeSet的构造方法中可传入一个比较器
-
import java.util.Comparator; import java.util.TreeSet; public class ComparatorDemo { public static void main(String[] args) { //创建一个TreeSet集合,并用比较器指定比较规则,此处的比较器使用一个匿名内部类的方式实现 TreeSet<Person> treeSet=new TreeSet<>(new Comparator<Person>() { @Override public int compare(Person o1, Person o2) { int n1=o1.getName().compareTo(o2.getName()); int n2= o1.getAge()-o2.getAge(); return n1==0?n2:n1; } }); Person p1=new Person("悟空",20); Person p2=new Person("悟空",22); Person p3=new Person("悟空",24); treeSet.add(p1); treeSet.add(p2); treeSet.add(p3); treeSet.add(new Person("悟空",20));//加入失败,因为name和age均相同 System.out.println(treeSet); } }
-
-
TreeSet实例
-
import java.util.Comparator; import java.util.TreeSet; /** * 通过comparator重新定制比较规则来实现不同长度的String进行排列 */ public class TreeSetDemo03 { public static void main(String[] args) { TreeSet<String> treeSet=new TreeSet<>(new Comparator<String>() { @Override public int compare(String o1, String o2) { int n1=o1.length()-o2.length();//长度相减,若为0则重复 int n2=o1.compareTo(o2);//系统默认的比较方式 return n1==0?n2:n1; } }); treeSet.add("hanbangsheng"); treeSet.add("songping"); treeSet.add("hanxin"); treeSet.add("hangping"); System.out.println(treeSet); } }
-
本文来自博客园,作者:一只快乐的小67,转载请注明原文链接:https://www.cnblogs.com/sp520/p/15934889.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号